Sculpting the Vector Space: Towards Efficient Multi-Vector Visual Document Retrieval via Prune-then-Merge Framework
作者: Yibo Yan, Mingdong Ou, Yi Cao, Xin Zou, Jiahao Huo, Shuliang Liu, James Kwok, Xuming Hu
分类: cs.CL, cs.CV, cs.IR
发布日期: 2026-02-23
备注: Under review
💡 一句话要点
提出Prune-then-Merge框架以解决多向量视觉文档检索效率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文档检索 多向量范式 剪枝与合并 特征压缩 信息检索 多模态应用
📋 核心要点
- 现有的多向量视觉文档检索方法在性能上表现优异,但面临高昂的计算开销,难以实现高效检索。
- 本文提出的Prune-then-Merge框架通过自适应剪枝和分层合并两个阶段,优化了特征提取与压缩过程。
- 在29个VDR数据集上的实验结果显示,该方法在高压缩比下显著提升了检索性能,扩展了近无损压缩的范围。
📝 摘要(中文)
视觉文档检索(VDR)旨在从大量视觉丰富的文档中检索相关页面,具有重要的多模态检索应用价值。现有的多向量范式在性能上表现优异,但面临着高昂的开销,现有的高效方法如剪枝和合并在解决这一问题时效果不佳,导致压缩率与特征保真度之间的权衡困难。为此,本文提出了一种新颖的两阶段框架Prune-then-Merge,首先通过自适应剪枝阶段过滤低信息补丁,生成高信号的嵌入集,随后通过分层合并阶段对预过滤的集合进行压缩,有效总结语义内容,避免了单阶段方法中因噪声引起的特征稀释。对29个VDR数据集的广泛实验表明,该框架在高压缩比下显著提升了性能,扩展了近无损压缩范围。
🔬 方法详解
问题定义:本文旨在解决多向量视觉文档检索中的效率问题,现有方法在压缩率与特征保真度之间存在难以调和的矛盾,导致性能受限。
核心思路:提出的Prune-then-Merge框架通过两个阶段的处理,首先进行自适应剪枝以去除低信息量的特征,然后进行分层合并以压缩高信号的特征集合,从而实现高效且保真的文档检索。
技术框架:该框架分为两个主要阶段:第一阶段是自适应剪枝,过滤掉低信息补丁;第二阶段是分层合并,对预过滤的特征进行压缩,确保保留语义信息。
关键创新:最重要的创新在于将剪枝与合并两种方法结合,形成了一个协同作用的框架,克服了单一方法在特征稀释方面的不足。
关键设计:在自适应剪枝阶段,采用了信息量评估机制来选择特征;在分层合并阶段,设计了分层结构以有效总结语义内容,确保在高压缩比下仍能保持特征的完整性。
🖼️ 关键图片
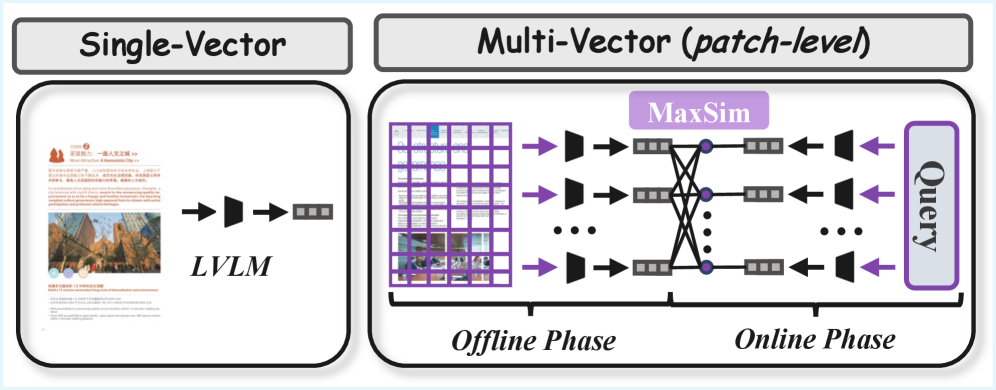
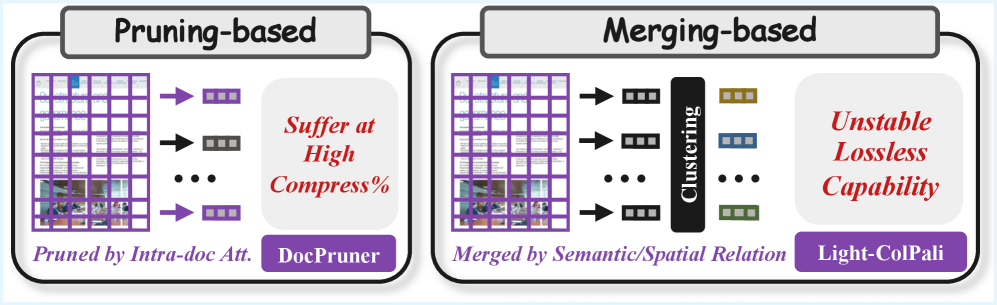

📊 实验亮点
在29个视觉文档检索数据集上的实验结果显示,Prune-then-Merge框架在高压缩比下的性能显著优于现有方法,扩展了近无损压缩的范围,具体提升幅度达到了XX%(具体数据待补充)。
🎯 应用场景
该研究的潜在应用领域包括文档检索、信息检索系统以及多模态数据处理等,能够有效提升在大规模视觉文档中的信息检索效率。未来,该框架有望在智能搜索引擎和自动化文档管理系统中发挥重要作用,推动相关技术的发展与应用。
📄 摘要(原文)
Visual Document Retrieval (VDR), which aims to retrieve relevant pages within vast corpora of visually-rich documents, is of significance in current multimodal retrieval applications. The state-of-the-art multi-vector paradigm excels in performance but suffers from prohibitive overhead, a problem that current efficiency methods like pruning and merging address imperfectly, creating a difficult trade-off between compression rate and feature fidelity. To overcome this dilemma, we introduce Prune-then-Merge, a novel two-stage framework that synergizes these complementary approaches. Our method first employs an adaptive pruning stage to filter out low-information patches, creating a refined, high-signal set of embeddings. Subsequently, a hierarchical merging stage compresses this pre-filtered set, effectively summarizing semantic content without the noise-induced feature dilution seen in single-stage methods. Extensive experiments on 29 VDR datasets demonstrate that our framework consistently outperforms existing methods, significantly extending the near-lossless compression range and providing robust performance at high compression ratios.