How to Train Your Deep Research Agent? Prompt, Reward, and Policy Optimization in Search-R1
作者: Yinuo Xu, Shuo Lu, Jianjie Cheng, Meng Wang, Qianlong Xie, Xingxing Wang, Ran He, Jian Liang
分类: cs.CL
发布日期: 2026-02-23
💡 一句话要点
针对深度研究Agent,系统性研究Prompt、奖励函数和策略优化方法,提升Search-R1性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度研究Agent 强化学习 Prompt工程 奖励函数设计 策略优化 知识密集型任务 检索增强生成
📋 核心要点
- 现有深度研究Agent中,强化学习的应用潜力未被充分挖掘,缺乏系统性的研究。
- 本文从Prompt模板、奖励函数和策略优化三个维度,系统性地研究了强化学习在深度研究Agent中的作用。
- 实验表明,优化Prompt、奖励函数和策略优化方法可以显著提升Search-R1的性能,例如Qwen2.5-7B模型上从0.403提升到0.442。
📝 摘要(中文)
深度研究Agent通过多轮检索和面向决策的生成来处理知识密集型任务。虽然强化学习(RL)已被证明可以提高这种范式的性能,但其贡献仍未得到充分探索。为了充分理解RL的作用,本文对三个解耦的维度进行了系统研究:prompt模板、奖励函数和策略优化。研究表明:1)快速思考模板比先前工作中使用的慢速思考模板产生更大的稳定性和更好的性能;2)基于F1的奖励不如EM,因为答案避免导致训练崩溃;可以通过加入动作级别的惩罚来缓解这个问题,最终超过EM;3)REINFORCE优于PPO,同时需要更少的搜索动作,而GRPO在策略优化方法中表现出最差的稳定性。基于这些见解,本文引入了Search-R1++,这是一个强大的基线,将Search-R1的性能从0.403提高到0.442 (Qwen2.5-7B),从0.289提高到0.331 (Qwen2.5-3B)。希望本文的研究结果能为深度研究系统中更具原则性和可靠性的RL训练策略铺平道路。
🔬 方法详解
问题定义:深度研究Agent旨在解决知识密集型任务,通过多轮检索和决策生成答案。现有方法中,强化学习的应用不够深入,缺乏对Prompt、奖励函数和策略优化等关键因素的系统性研究,导致性能提升受限。现有奖励函数设计存在训练崩溃的风险。
核心思路:本文的核心思路是解耦Prompt模板、奖励函数和策略优化三个维度,分别研究它们对深度研究Agent性能的影响。通过实验分析,找到最优的组合方式,从而提升整体性能。针对奖励函数训练崩溃问题,引入动作级别的惩罚。
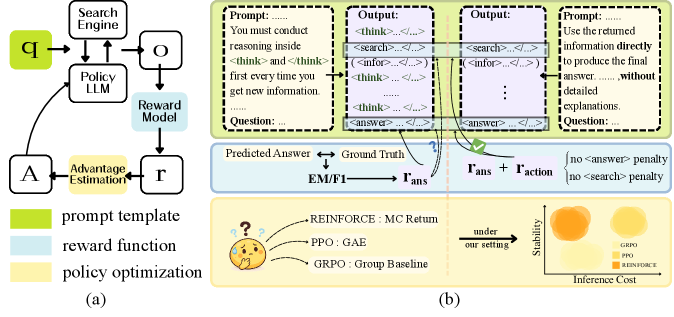
技术框架:整体框架基于Search-R1,主要包含以下几个阶段:1) 使用Prompt模板引导Agent进行检索和生成;2) 根据生成的答案和检索结果,计算奖励;3) 使用强化学习算法优化Agent的策略,使其能够更好地完成任务。本文重点研究了Prompt模板的选择、奖励函数的设计和策略优化算法的选择。
关键创新:本文最重要的技术创新在于对Prompt模板、奖励函数和策略优化进行了系统性的解耦研究,并发现了它们之间的相互作用。此外,引入动作级别的惩罚,有效缓解了奖励函数训练崩溃的问题。提出了Search-R1++,一个更强的基线模型。
关键设计:Prompt模板方面,对比了Fast Thinking和Slow Thinking两种模板。奖励函数方面,对比了F1-based和EM两种奖励,并引入了动作级别的惩罚。策略优化方面,对比了REINFORCE、PPO和GRPO三种算法。具体参数设置和网络结构沿用了Search-R1的设置,并在其基础上进行了优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Fast Thinking模板优于Slow Thinking模板。F1-based奖励在加入动作级别惩罚后,性能超过EM奖励。REINFORCE算法优于PPO算法,且所需搜索动作更少。基于这些发现,本文提出的Search-R1++在Qwen2.5-7B模型上将Search-R1的性能从0.403提高到0.442,在Qwen2.5-3B模型上从0.289提高到0.331。
🎯 应用场景
该研究成果可应用于各种知识密集型任务,例如问答系统、智能助手、科研助手等。通过优化Prompt、奖励函数和策略优化,可以提升Agent的检索和生成能力,使其能够更准确、更高效地完成任务。该研究为深度研究Agent的强化学习训练提供了指导,有助于推动相关领域的发展。
📄 摘要(原文)
Deep Research agents tackle knowledge-intensive tasks through multi-round retrieval and decision-oriented generation. While reinforcement learning (RL) has been shown to improve performance in this paradigm, its contributions remain underexplored. To fully understand the role of RL, we conduct a systematic study along three decoupled dimensions: prompt template, reward function, and policy optimization. Our study reveals that: 1) the Fast Thinking template yields greater stability and better performance than the Slow Thinking template used in prior work; 2) the F1-based reward underperforms the EM due to training collapse driven by answer avoidance; this can be mitigated by incorporating action-level penalties, ultimately surpassing EM; 3) REINFORCE outperforms PPO while requiring fewer search actions, whereas GRPO shows the poorest stability among policy optimization methods. Building on these insights, we then introduce Search-R1++, a strong baseline that improves the performance of Search-R1 from 0.403 to 0.442 (Qwen2.5-7B) and 0.289 to 0.331 (Qwen2.5-3B). We hope that our findings can pave the way for more principled and reliable RL training strategies in Deep Research systems.