Pyramid MoA: A Probabilistic Framework for Cost-Optimized Anytime Inference
作者: Arindam Khaled
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-23
备注: 6 pages, 4 figures, 1 table
💡 一句话要点
提出Pyramid MoA,通过动态路由降低大语言模型推理成本,提升性价比。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理加速 动态路由 混合专家模型 成本优化
📋 核心要点
- 大型语言模型推理成本高昂,小型模型能力不足,难以兼顾性能与效率。
- Pyramid MoA利用轻量级路由器动态调度模型,仅在必要时使用大型模型。
- 实验表明,该方法在保证性能的同时,显著降低了计算成本,延迟开销小。
📝 摘要(中文)
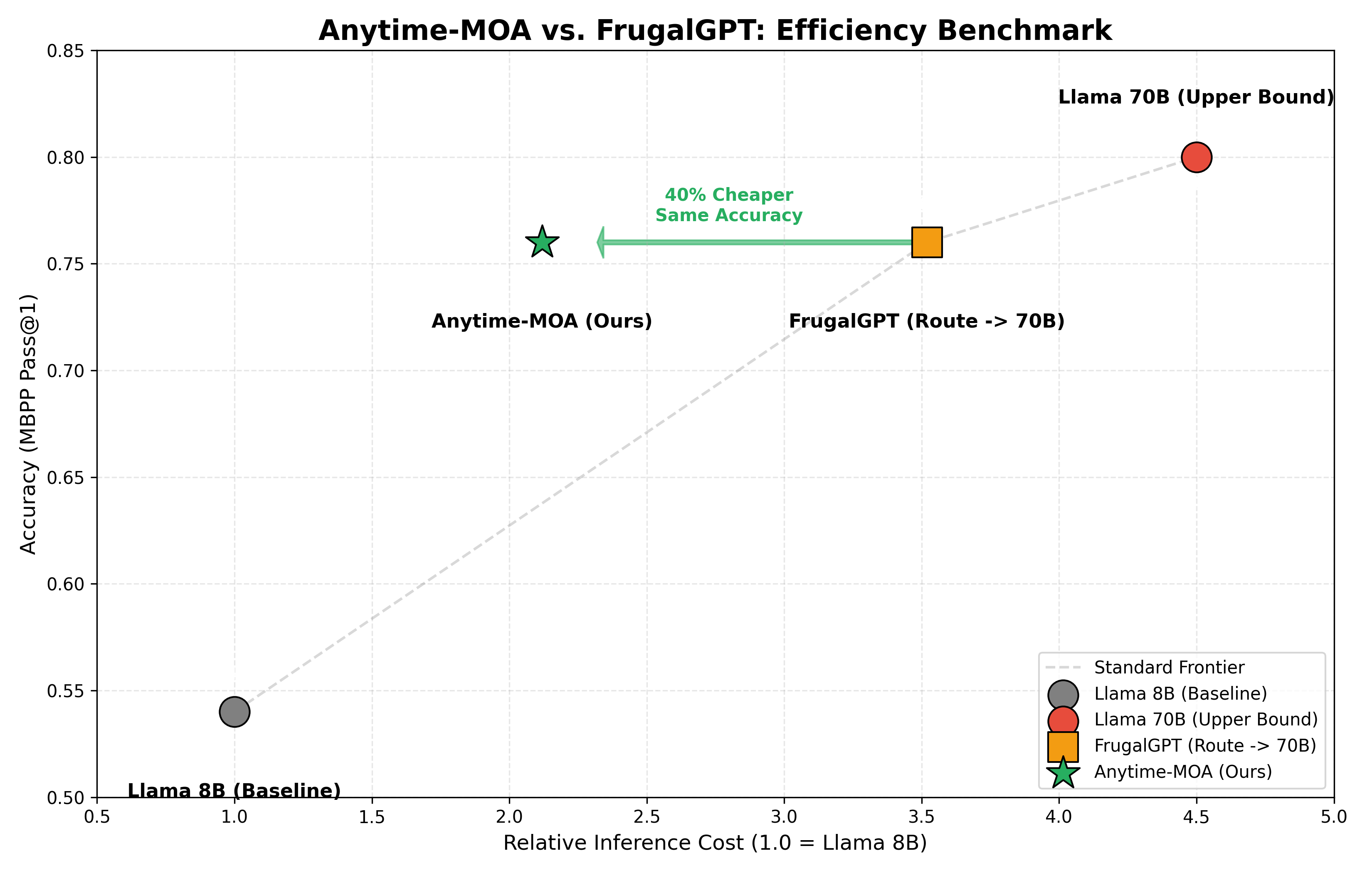
本文提出了一种名为“Pyramid MoA”的分层混合Agent架构,旨在解决大型语言模型(LLMs)推理成本和推理能力之间的权衡问题。该架构使用轻量级路由器,仅在必要时动态升级查询。通过利用小型模型集合之间的语义一致性和置信度校准,路由器能够高精度地识别“困难”问题。在GSM8K基准测试中,该系统实现了93.0%的准确率,有效地匹配了Oracle基线(98.0%),同时降低了61%的计算成本。实验表明,该系统引入的延迟开销可忽略不计(+0.82秒),并允许在性能和预算之间进行可调节的权衡。
🔬 方法详解
问题定义:大型语言模型(LLMs)在推理时面临着计算成本和推理能力之间的权衡。虽然像Llama-3-70B这样的“Oracle”模型可以达到最先进的准确率,但对于高容量部署来说,成本过高。较小的模型(例如8B参数)具有成本效益,但在处理复杂任务时表现不佳。因此,如何在保证性能的前提下,降低LLM的推理成本是一个关键问题。
核心思路:Pyramid MoA的核心思想是利用一个轻量级的路由器,根据输入问题的难易程度,动态地选择合适的模型进行推理。对于简单的输入,使用小型模型快速推理;对于复杂的输入,则升级到大型模型进行更精确的推理。通过这种方式,可以避免对所有输入都使用大型模型,从而降低整体的计算成本。
技术框架:Pyramid MoA采用分层混合Agent架构。该架构包含多个小型模型(Agents)和一个轻量级路由器。路由器首先分析输入问题,并根据小型模型之间的语义一致性和置信度校准,判断问题的难易程度。如果问题被认为是“简单”的,则由小型模型直接进行推理。如果问题被认为是“困难”的,则将其路由到更大的模型进行推理。整个过程可以看作是一个金字塔结构,底层是多个小型模型,顶层是大型模型,路由器负责在不同层级之间进行动态调度。
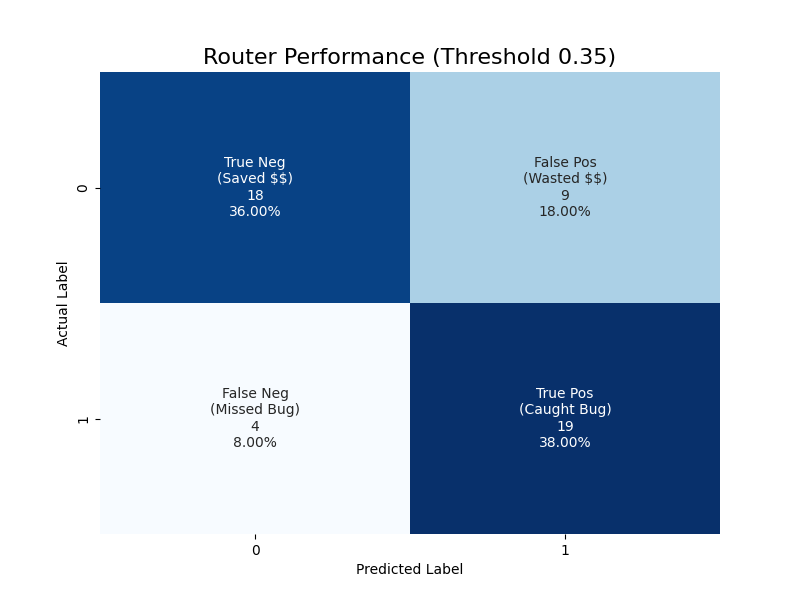
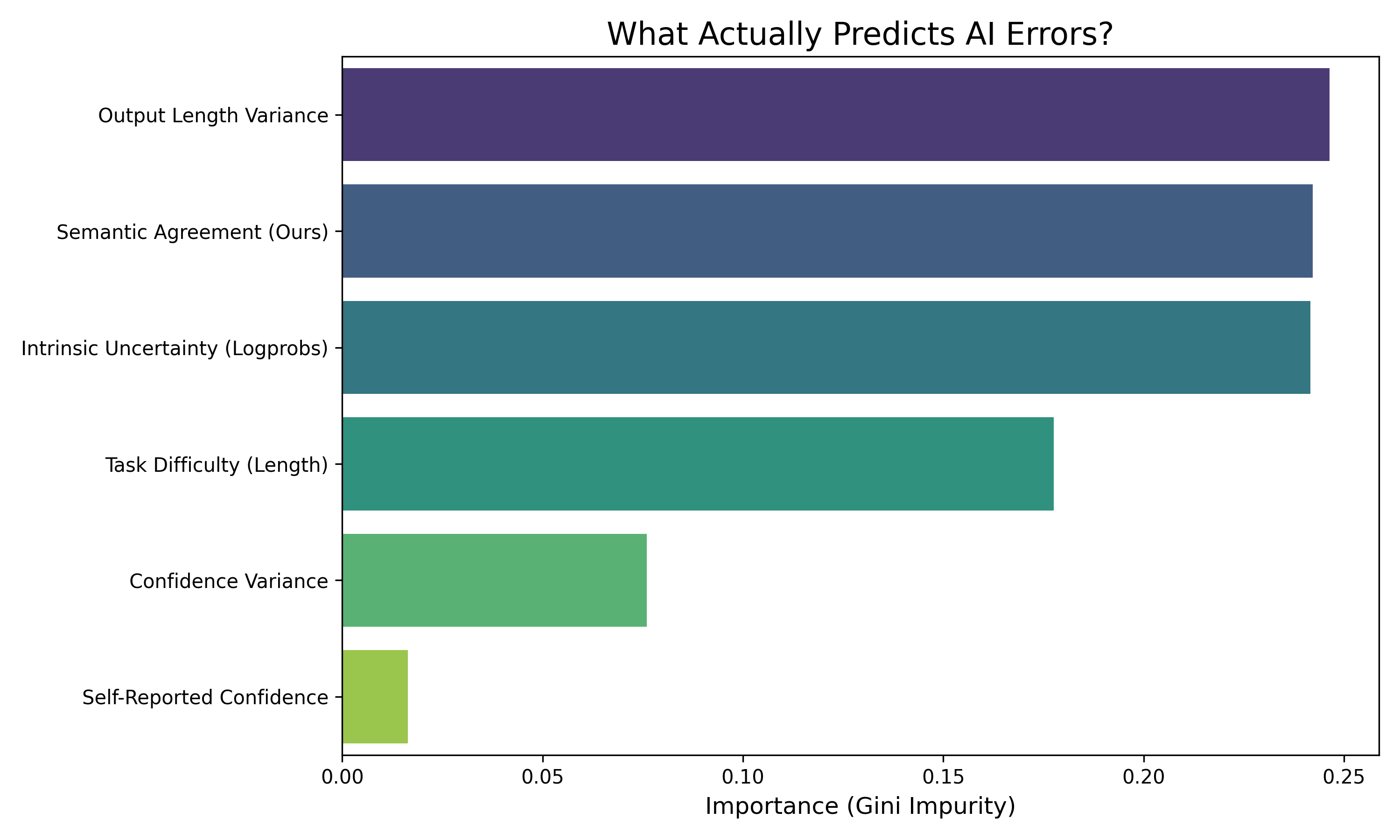
关键创新:Pyramid MoA的关键创新在于其动态路由机制。传统的混合专家模型通常使用固定的路由策略,或者依赖于复杂的路由网络。而Pyramid MoA使用基于语义一致性和置信度校准的轻量级路由器,能够更准确地判断问题的难易程度,并进行更有效的模型调度。这种动态路由机制可以显著降低计算成本,同时保持较高的推理准确率。
关键设计:路由器使用小型模型输出的语义一致性和置信度作为判断问题难易程度的依据。语义一致性可以通过计算不同模型输出之间的相似度来衡量。置信度可以通过分析模型输出的概率分布来估计。路由器使用这些信息来训练一个分类器,用于预测问题是否需要升级到更大的模型进行推理。损失函数的设计需要平衡准确率和计算成本,避免过度使用大型模型。
🖼️ 关键图片
📊 实验亮点
在GSM8K基准测试中,Pyramid MoA实现了93.0%的准确率,与Oracle基线(98.0%)的性能差距很小,但计算成本降低了61%。同时,该系统引入的延迟开销仅为+0.82秒,几乎可以忽略不计。这些结果表明,Pyramid MoA能够在保证性能的同时,显著降低LLM的推理成本。
🎯 应用场景
Pyramid MoA适用于需要大规模部署LLM的各种场景,例如智能客服、搜索引擎、代码生成等。通过降低推理成本,该方法可以使LLM更广泛地应用于资源受限的环境中,例如移动设备和边缘计算设备。此外,该方法还可以用于构建更高效的LLM服务,提高服务的吞吐量和响应速度。
📄 摘要(原文)
Large Language Models (LLMs) face a persistent trade-off between inference cost and reasoning capability. While "Oracle" models (e.g., Llama-3-70B) achieve state-of-the-art accuracy, they are prohibitively expensive for high-volume deployment. Smaller models (e.g., 8B parameters) are cost-effective but struggle with complex tasks. In this work, we propose "Pyramid MoA", a hierarchical Mixture-of-Agents architecture that uses a lightweight Router to dynamically escalate queries only when necessary. By leveraging semantic agreement and confidence calibration among an ensemble of small models, our Router identifies "hard" problems with high precision. On the GSM8K benchmark, our system achieves 93.0% accuracy, effectively matching the Oracle baseline (98.0%) while reducing compute costs by 61%. We demonstrate that the system introduces negligible latency overhead (+0.82s) and allows for a tunable trade-off between performance and budget.