Retrieval Augmented Enhanced Dual Co-Attention Framework for Target Aware Multimodal Bengali Hateful Meme Detection
作者: Raihan Tanvir, Md. Golam Rabiul Alam
分类: cs.CL
发布日期: 2026-02-22
💡 一句话要点
提出检索增强的增强双重协同注意力框架xDORA,用于识别孟加拉语仇恨模因。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 仇恨模因检测 多模态学习 低资源语言 检索增强 协同注意力 孟加拉语 FAISS
📋 核心要点
- 现有方法在低资源语言(如孟加拉语)仇恨模因检测中,面临数据稀缺、类别不平衡和代码混合等挑战。
- 论文提出增强双重协同注意力框架(xDORA),结合视觉和文本编码器,利用检索增强生成上下文信息,提升模型性能。
- 实验结果表明,xDORA和RAG-Fused DORA在仇恨模因识别和目标实体检测方面均优于基线模型,提升显著。
📝 摘要(中文)
社交媒体上的仇恨内容日益以多模态模因的形式出现,它们结合图像和文本来传达有害信息。在孟加拉语等低资源语言中,由于标注数据有限、类别不平衡和普遍存在的代码混合,自动检测仍然具有挑战性。为了解决这些问题,我们使用孟加拉语多模态攻击数据集(MIMOSA)中语义对齐的样本来扩充孟加拉语仇恨模因(BHM)数据集,从而改善类别平衡和语义多样性。我们提出了增强双重协同注意力框架(xDORA),通过加权注意力池化集成视觉编码器(CLIP、DINOv2)和多语言文本编码器(XGLM、XLM-R),以学习鲁棒的跨模态表示。在此基础上,我们开发了一个基于FAISS的k近邻分类器用于非参数推理,并引入了RAG-Fused DORA,它结合了检索驱动的上下文推理。我们进一步评估了LLaVA在零样本、少样本和检索增强提示设置下的性能。在扩展数据集上的实验表明,xDORA (CLIP + XLM-R)在仇恨模因识别方面实现了0.78的宏平均F1分数,在目标实体检测方面实现了0.71的宏平均F1分数,而RAG-Fused DORA将性能提高到0.79和0.74,优于DORA基线。基于FAISS的分类器表现出很强的竞争力,并通过语义相似性建模展示了对罕见类别的鲁棒性。相比之下,LLaVA在少样本设置中的有效性有限,仅在检索增强下略有改进,突出了预训练视觉语言模型在没有微调的情况下对代码混合孟加拉语内容的约束。这些发现证明了有监督、检索增强和非参数多模态框架在解决低资源仇恨言论检测中的语言和文化复杂性方面的有效性。
🔬 方法详解
问题定义:论文旨在解决低资源语言(特别是孟加拉语)中仇恨模因检测的难题。现有方法在处理此类问题时,面临着标注数据不足、类别分布不平衡以及代码混合现象普遍等挑战,导致模型性能受限。这些问题使得模型难以准确捕捉模因中蕴含的仇恨信息,尤其是在涉及特定目标实体时。
核心思路:论文的核心思路是利用数据增强和检索增强技术,结合双重协同注意力机制,提升模型对多模态信息的理解能力。通过扩充数据集,增加语义多样性,缓解数据稀缺问题。利用检索增强,为模型提供更丰富的上下文信息,从而提高识别准确率。双重协同注意力机制则用于有效融合图像和文本特征,捕捉跨模态关联。
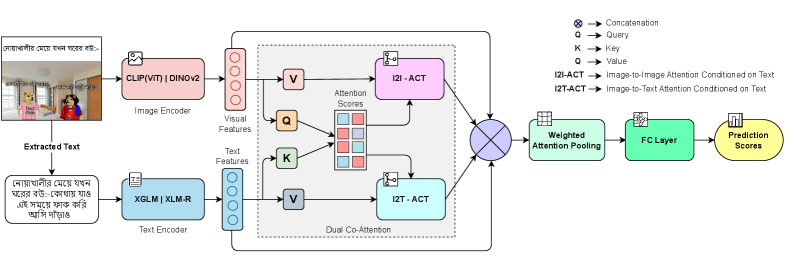
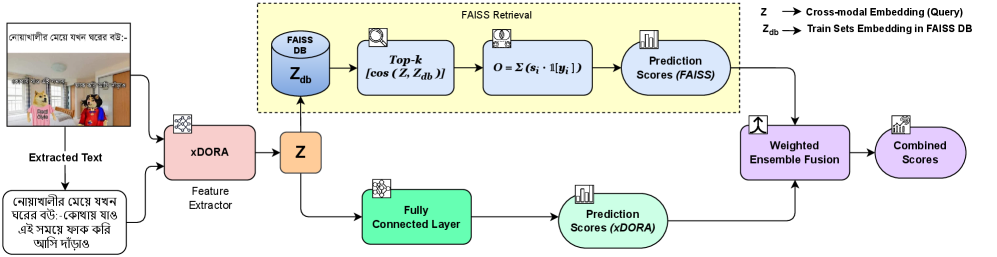
技术框架:整体框架包含以下几个主要模块:1) 数据增强模块:使用MIMOSA数据集扩充BHM数据集,提升数据量和类别平衡性。2) 特征提取模块:使用CLIP和DINOv2提取图像特征,使用XGLM和XLM-R提取文本特征。3) 双重协同注意力模块:通过加权注意力池化,融合视觉和文本特征,学习跨模态表示。4) 分类模块:使用基于FAISS的k近邻分类器进行非参数推理,或使用RAG-Fused DORA进行检索增强推理。
关键创新:论文的关键创新在于:1) 提出了增强双重协同注意力框架(xDORA),有效融合视觉和文本特征。2) 引入了RAG-Fused DORA,利用检索增强技术,提升模型对上下文信息的利用能力。3) 使用基于FAISS的k近邻分类器,提高了对罕见类别的鲁棒性。
关键设计:在双重协同注意力模块中,使用了加权注意力池化,根据不同模态的重要性进行加权融合。RAG-Fused DORA使用FAISS索引构建检索系统,检索与输入模因相关的上下文信息。损失函数方面,论文可能使用了交叉熵损失函数或其他适用于分类任务的损失函数。具体的网络结构细节(如层数、神经元数量等)可能在论文正文中详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,xDORA (CLIP + XLM-R)在仇恨模因识别方面实现了0.78的宏平均F1分数,在目标实体检测方面实现了0.71的宏平均F1分数。RAG-Fused DORA进一步将性能提高到0.79和0.74,显著优于DORA基线。基于FAISS的分类器表现出很强的竞争力,并通过语义相似性建模展示了对罕见类别的鲁棒性。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,自动检测和过滤孟加拉语仇恨模因,减少有害信息的传播。此外,该方法也可推广到其他低资源语言的多模态仇恨言论检测任务中,具有重要的社会价值和应用前景。未来,可以进一步探索更有效的跨模态融合方法和检索策略,提升模型的性能和泛化能力。
📄 摘要(原文)
Hateful content on social media increasingly appears as multimodal memes that combine images and text to convey harmful narratives. In low-resource languages such as Bengali, automated detection remains challenging due to limited annotated data, class imbalance, and pervasive code-mixing. To address these issues, we augment the Bengali Hateful Memes (BHM) dataset with semantically aligned samples from the Multimodal Aggression Dataset in Bengali (MIMOSA), improving both class balance and semantic diversity. We propose the Enhanced Dual Co-attention Framework (xDORA), integrating vision encoders (CLIP, DINOv2) and multilingual text encoders (XGLM, XLM-R) via weighted attention pooling to learn robust cross-modal representations. Building on these embeddings, we develop a FAISS-based k-nearest neighbor classifier for non-parametric inference and introduce RAG-Fused DORA, which incorporates retrieval-driven contextual reasoning. We further evaluate LLaVA under zero-shot, few-shot, and retrieval-augmented prompting settings. Experiments on the extended dataset show that xDORA (CLIP + XLM-R) achieves macro-average F1-scores of 0.78 for hateful meme identification and 0.71 for target entity detection, while RAG-Fused DORA improves performance to 0.79 and 0.74, yielding gains over the DORA baseline. The FAISS-based classifier performs competitively and demonstrates robustness for rare classes through semantic similarity modeling. In contrast, LLaVA exhibits limited effectiveness in few-shot settings, with only modest improvements under retrieval augmentation, highlighting constraints of pretrained vision-language models for code-mixed Bengali content without fine-tuning. These findings demonstrate the effectiveness of supervised, retrieval-augmented, and non-parametric multimodal frameworks for addressing linguistic and cultural complexities in low-resource hate speech detection.