Next Reply Prediction X Dataset: Linguistic Discrepancies in Naively Generated Content
作者: Simon Münker, Nils Schwager, Kai Kugler, Michael Heseltine, Achim Rettinger
分类: cs.CL, cs.AI
发布日期: 2026-02-22
备注: 8 pages (12 including references), 2 figures and 2 tables
💡 一句话要点
提出基于X平台的新型回复预测数据集,评估LLM生成内容与人类表达的语言差异。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 回复预测 社交媒体数据 语言风格分析 内容真实性评估
📋 核心要点
- 现有方法直接使用LLM生成内容,缺乏对人类真实语言模式的约束,导致生成内容与真实数据存在显著差异。
- 论文提出基于真实X平台数据的回复预测任务,构建数据集,用于评估LLM生成内容与人类表达的语言差异。
- 通过风格和内容指标分析LLM生成内容与人类回复之间的差异,为评估合成数据的质量提供定量框架。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用作社会科学研究中人类参与者的替代品,这带来了一个充满希望但也存在方法论风险的范式转变。虽然LLM具有可扩展性和成本效益,但其“naive”应用,即在没有明确行为约束的情况下提示它们生成内容,会引入显著的语言差异,从而挑战研究结果的有效性。本文通过在真实的X(前身为Twitter)数据上引入一种新颖的、历史条件下的回复预测任务来解决这些限制,从而创建一个数据集,旨在评估LLM生成的语言输出与人类生成的内容的差异。我们使用风格和基于内容的指标分析这些差异,为研究人员提供了一个定量框架来评估合成数据的质量和真实性。我们的研究结果强调需要更复杂的提示技术和专门的数据集,以确保LLM生成的内容准确反映人类交流的复杂语言模式,从而提高计算社会科学研究的有效性。
🔬 方法详解
问题定义:论文旨在解决LLM在计算社会科学研究中作为人类代理时,由于缺乏对人类语言行为的约束,导致生成内容与真实人类表达存在显著差异的问题。现有方法直接使用LLM生成内容,忽略了真实社交互动中复杂的语言模式,这会影响研究结果的有效性。
核心思路:论文的核心思路是构建一个基于真实社交媒体数据(X平台)的回复预测任务,以此来评估LLM生成内容与人类真实表达之间的语言差异。通过比较LLM生成的回复和人类实际的回复,可以量化LLM在风格、内容和语言模式上的偏差。
技术框架:整体框架包括以下几个主要阶段:1) 数据收集:从X平台收集真实的对话数据,包括上下文信息和回复内容。2) 数据预处理:对收集到的数据进行清洗和处理,例如去除噪声、处理特殊字符等。3) 模型训练:使用LLM在处理后的数据上进行训练,使其能够预测给定上下文的回复。4) 评估:使用风格和内容相关的指标,比较LLM生成的回复和人类实际的回复,从而评估LLM的性能和语言差异。
关键创新:论文的关键创新在于提出了一个基于真实社交媒体数据的回复预测任务,并构建了一个专门用于评估LLM生成内容的数据集。与以往的研究不同,该方法更加关注LLM在模拟人类社交互动时的语言真实性,并提供了一个量化的评估框架。
关键设计:论文使用X平台作为数据来源,保证了数据的真实性和多样性。在评估指标方面,论文采用了风格和内容相关的多种指标,例如词汇多样性、情感倾向、主题一致性等,从而能够全面地评估LLM生成内容的质量。具体的参数设置、损失函数、网络结构等技术细节在论文中可能没有详细描述,属于LLM训练的常规设置。
🖼️ 关键图片
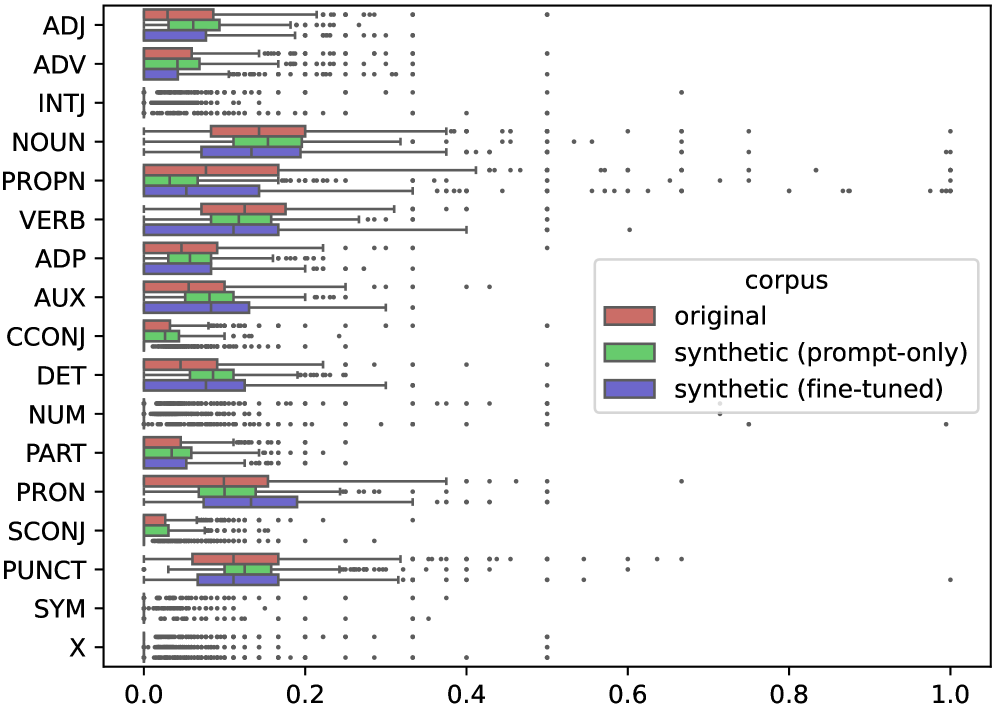
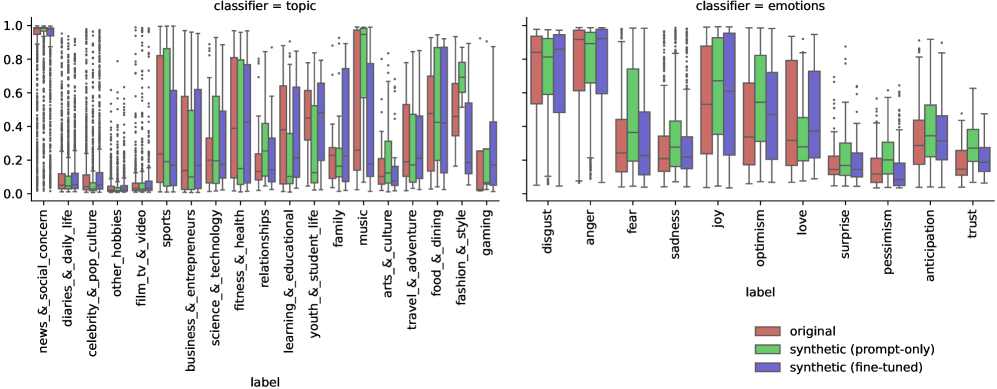
📊 实验亮点
论文通过实验分析了LLM生成内容与人类回复之间的语言差异,发现LLM在风格和内容上都存在一定的偏差。例如,LLM生成的回复可能缺乏人类回复的个性化特征,或者在情感表达上不够自然。这些发现为改进LLM的生成能力提供了重要的参考。
🎯 应用场景
该研究成果可应用于计算社会科学、自然语言处理等领域。通过评估和改进LLM生成内容的真实性,可以提高LLM在社会科学研究中的应用价值,例如模拟社会舆论、分析用户行为等。此外,该研究还可以促进LLM在对话系统、智能客服等领域的应用,使其能够生成更自然、更符合人类表达习惯的回复。
📄 摘要(原文)
The increasing use of Large Language Models (LLMs) as proxies for human participants in social science research presents a promising, yet methodologically risky, paradigm shift. While LLMs offer scalability and cost-efficiency, their "naive" application, where they are prompted to generate content without explicit behavioral constraints, introduces significant linguistic discrepancies that challenge the validity of research findings. This paper addresses these limitations by introducing a novel, history-conditioned reply prediction task on authentic X (formerly Twitter) data, to create a dataset designed to evaluate the linguistic output of LLMs against human-generated content. We analyze these discrepancies using stylistic and content-based metrics, providing a quantitative framework for researchers to assess the quality and authenticity of synthetic data. Our findings highlight the need for more sophisticated prompting techniques and specialized datasets to ensure that LLM-generated content accurately reflects the complex linguistic patterns of human communication, thereby improving the validity of computational social science studies.