A Dataset for Named Entity Recognition and Relation Extraction from Art-historical Image Descriptions
作者: Stefanie Schneider, Miriam Göldl, Julian Stalter, Ricarda Vollmer
分类: cs.CL
发布日期: 2026-02-22
💡 一句话要点
提出FRAME数据集,用于艺术史图像描述的命名实体识别和关系抽取。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 命名实体识别 关系抽取 艺术史 图像描述 数据集 知识图谱 自然语言处理
📋 核心要点
- 现有的NER和RE数据集在艺术史领域数据稀缺,缺乏细粒度的标注和实体类型。
- FRAME数据集通过人工标注艺术史图像描述,提供多层次、细粒度的实体类型和关系标注。
- 该数据集可用于基准测试和微调NER和RE系统,支持零样本和少样本学习,并促进知识图谱构建。
📝 摘要(中文)
本文介绍了一个名为FRAME(艺术史元数据和实体细粒度识别)的手动标注数据集,该数据集用于艺术史图像描述的命名实体识别(NER)和关系抽取(RE)。描述文本来源于博物馆目录、拍卖清单、开放获取平台和学术数据库,经过筛选以确保每个文本都专注于单个艺术品,并包含关于其材料、构图或图像志的明确陈述。FRAME提供三个层次的独立标注:对象级别属性的元数据层、描绘的主题和主题的内容层,以及链接重复提及的共指层。在各个层中,实体跨度被标记为37种类型,并通过类型化的RE链接在提及之间连接。实体类型与Wikidata对齐,以支持命名实体链接(NEL)和下游知识图谱构建。该数据集以UIMA XMI通用分析结构(CAS)文件的形式发布,附带图像和书目元数据,可用于基准测试和微调NER和RE系统,包括大型语言模型(LLM)的零样本和少样本设置。
🔬 方法详解
问题定义:该论文旨在解决艺术史领域图像描述的命名实体识别(NER)和关系抽取(RE)问题。现有方法在处理艺术史领域的文本时,面临数据稀缺、标注粒度粗糙以及缺乏领域知识对齐等挑战,导致性能不佳。
核心思路:核心思路是构建一个高质量、细粒度标注的艺术史图像描述数据集FRAME。通过人工标注,提供丰富的实体类型和关系信息,并与Wikidata等知识库对齐,从而提升NER和RE模型在艺术史领域的性能。
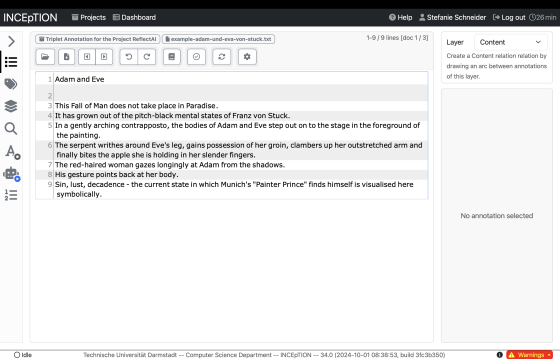
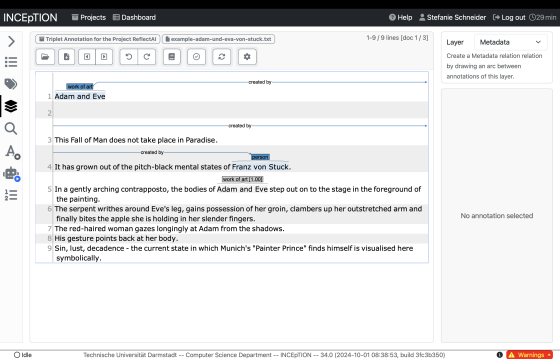
技术框架:FRAME数据集的构建包含以下几个主要阶段:1) 数据收集:从博物馆目录、拍卖清单等来源收集艺术史图像描述文本。2) 数据筛选:筛选出专注于单个艺术品并包含材料、构图或图像志描述的文本。3) 数据标注:进行三层标注,包括元数据层、内容层和共指层。4) 实体类型对齐:将实体类型与Wikidata对齐,支持命名实体链接。5) 数据发布:以UIMA XMI CAS文件的形式发布数据集,附带图像和书目元数据。
关键创新:该数据集的关键创新在于其细粒度的标注体系和多层次的标注结构。它不仅标注了实体类型,还标注了实体之间的关系,并提供了共指信息。此外,与Wikidata的对齐使得该数据集可以用于知识图谱构建等下游任务。
关键设计:FRAME数据集包含37种实体类型,涵盖了艺术品的各个方面,如材料、风格、作者等。关系抽取任务定义了实体之间的多种关系类型,如“is_made_of”、“depicts”等。标注过程采用人工标注,保证了标注的质量和准确性。数据集以UIMA XMI CAS文件的形式发布,方便用户使用和集成。
🖼️ 关键图片

📊 实验亮点
FRAME数据集包含大量人工标注的艺术史图像描述,涵盖37种实体类型和多种关系类型。实验表明,该数据集可用于有效训练和评估NER和RE模型,并在零样本和少样本设置下取得良好效果。与现有数据集相比,FRAME数据集的细粒度标注和领域知识对齐能够显著提升模型在艺术史领域的性能。
🎯 应用场景
该研究成果可应用于艺术史研究、博物馆数字化、艺术品知识图谱构建等领域。通过自动识别和抽取艺术品图像描述中的实体和关系,可以帮助研究人员更高效地分析艺术品,提升博物馆的数字化水平,并为用户提供更丰富的艺术品知识服务。未来,该数据集可以用于训练更强大的艺术史领域知识图谱,并应用于艺术品推荐、艺术风格分析等任务。
📄 摘要(原文)
This paper introduces FRAME (Fine-grained Recognition of Art-historical Metadata and Entities), a manually annotated dataset of art-historical image descriptions for Named Entity Recognition (NER) and Relation Extraction (RE). Descriptions were collected from museum catalogs, auction listings, open-access platforms, and scholarly databases, then filtered to ensure that each text focuses on a single artwork and contains explicit statements about its material, composition, or iconography. FRAME provides stand-off annotations in three layers: a metadata layer for object-level properties, a content layer for depicted subjects and motifs, and a co-reference layer linking repeated mentions. Across layers, entity spans are labeled with 37 types and connected by typed RE links between mentions. Entity types are aligned with Wikidata to support Named Entity Linking (NEL) and downstream knowledge-graph construction. The dataset is released as UIMA XMI Common Analysis Structure (CAS) files with accompanying images and bibliographic metadata, and can be used to benchmark and fine-tune NER and RE systems, including zero- and few-shot setups with Large Language Models (LLMs).