Astra: Activation-Space Tail-Eigenvector Low-Rank Adaptation of Large Language Models
作者: Kainan Liu, Yong Zhang, Ning Cheng, Yun Zhu, Yanmeng Wang, Shaojun Wang, Jing Xiao
分类: cs.CL
发布日期: 2026-02-22
备注: 22 pages, 10 figures
💡 一句话要点
Astra:利用激活空间尾部特征向量的低秩适配方法,提升大语言模型微调性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适配 激活空间 尾部特征向量 大语言模型 自然语言处理 任务自适应
📋 核心要点
- 现有LoRA等PEFT方法未能充分利用激活空间中尾部特征向量的潜力,导致微调性能受限。
- Astra通过利用任务特定校准集估计的尾部特征向量,构建任务自适应的低秩适配器。
- 实验表明,Astra在多个NLU和NLG任务上超越了现有PEFT方法,并在某些情况下优于全量微调。
📝 摘要(中文)
参数高效微调(PEFT)方法,特别是LoRA,因其计算和存储效率而被广泛用于将预训练模型适配到下游任务。然而,在LoRA及其变体的背景下,与尾部特征向量对应的激活子空间的潜力仍未得到充分利用,这可能导致次优的微调性能。本文提出了Astra(激活空间尾部特征向量低秩适配),一种新的PEFT方法,它利用模型输出激活的尾部特征向量(从小的特定任务校准集中估计)来构建任务自适应的低秩适配器。通过将更新限制在这些尾部特征向量所跨越的子空间中,Astra实现了更快的收敛速度和改进的下游性能,同时显著降低了参数预算。在自然语言理解(NLU)和自然语言生成(NLG)任务中的大量实验表明,Astra在16个基准测试中始终优于现有的PEFT基线,甚至在某些情况下超过了全量微调(FFT)。
🔬 方法详解
问题定义:现有参数高效微调方法(如LoRA)虽然降低了计算和存储成本,但对激活空间中尾部特征向量的利用不足,限制了模型在下游任务上的性能提升。这些尾部特征向量可能包含任务相关的关键信息,但未被有效利用。
核心思路:Astra的核心思想是利用模型输出激活的尾部特征向量来构建低秩适配器。通过将模型的更新限制在由这些尾部特征向量张成的子空间内,可以更有效地学习任务相关的知识,同时保持较低的参数量。这种方法旨在更好地捕捉和利用激活空间中蕴含的任务特定信息。
技术框架:Astra方法主要包含以下几个阶段:1) 使用少量任务特定数据(校准集)运行预训练模型,获取模型输出激活;2) 对激活进行特征分解,提取尾部特征向量;3) 基于提取的尾部特征向量构建低秩适配器;4) 使用下游任务数据微调适配器,同时保持预训练模型参数不变。整体流程旨在将任务相关的更新限制在由尾部特征向量定义的子空间内。
关键创新:Astra的关键创新在于利用激活空间的尾部特征向量来指导低秩适配器的构建。与传统的随机初始化或基于奇异值分解的低秩适配器不同,Astra的适配器是任务自适应的,能够更好地捕捉任务相关的特征。这种方法有效地利用了模型在特定任务上的激活信息,从而提高了微调效率和性能。
关键设计:Astra的关键设计包括:1) 使用少量校准集来估计尾部特征向量,降低计算成本;2) 通过控制尾部特征向量的数量来调节适配器的参数量;3) 使用标准的反向传播算法来微调适配器参数,同时保持预训练模型参数不变。损失函数通常采用交叉熵损失或类似的适用于下游任务的损失函数。
🖼️ 关键图片
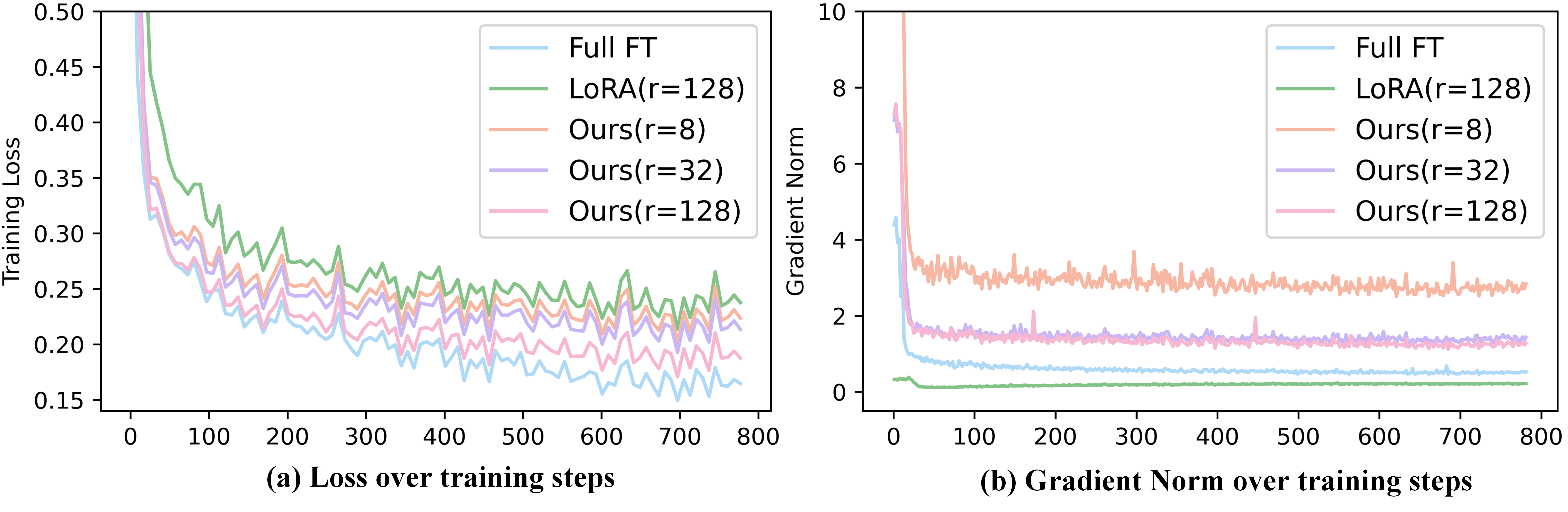
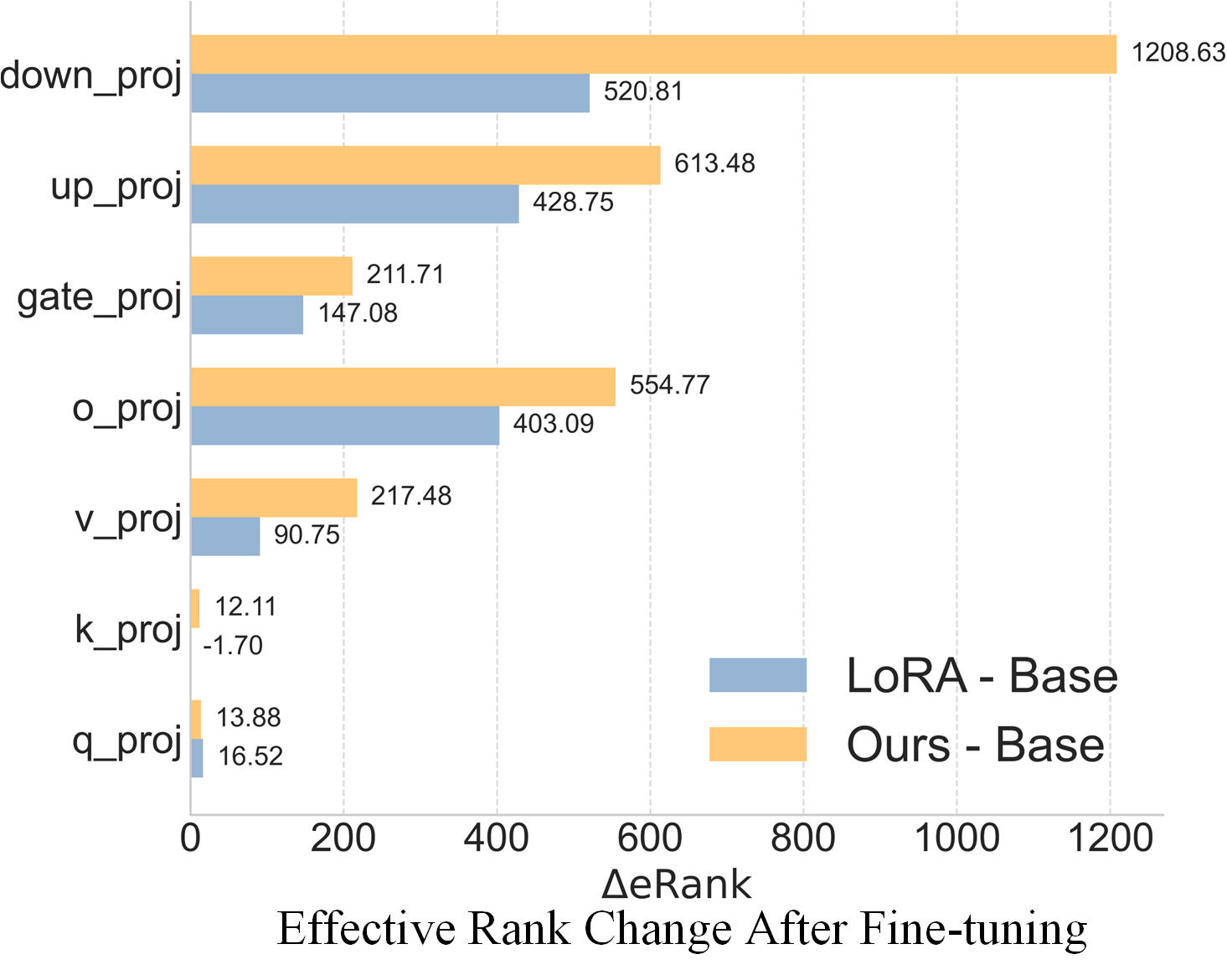
📊 实验亮点
实验结果表明,Astra在16个NLU和NLG基准测试中始终优于现有的PEFT基线方法,例如LoRA。在某些任务上,Astra甚至超过了全量微调(FFT)的性能。例如,在某些文本生成任务上,Astra的BLEU得分比LoRA提高了显著的百分比。这些结果证明了Astra在参数效率和性能方面的优势。
🎯 应用场景
Astra可广泛应用于各种需要将大型语言模型适配到特定下游任务的场景,例如文本分类、情感分析、机器翻译、文本生成等。该方法尤其适用于资源受限的环境,例如边缘计算设备或移动设备,因为它可以显著降低微调所需的计算和存储成本。Astra的未来影响在于推动大模型在更多实际应用中的部署。
📄 摘要(原文)
Parameter-Efficient Fine-Tuning (PEFT) methods, especially LoRA, are widely used for adapting pre-trained models to downstream tasks due to their computational and storage efficiency. However, in the context of LoRA and its variants, the potential of activation subspaces corresponding to tail eigenvectors remains substantially under-exploited, which may lead to suboptimal fine-tuning performance. In this work, we propose Astra (Activation-Space Tail-Eigenvector Low-Rank Adaptation), a novel PEFT method that leverages the tail eigenvectors of the model output activations-estimated from a small task-specific calibration set-to construct task-adaptive low-rank adapters. By constraining updates to the subspace spanned by these tail eigenvectors, Astra achieves faster convergence and improved downstream performance with a significantly reduced parameter budget. Extensive experiments across natural language understanding (NLU) and natural language generation (NLG) tasks demonstrate that Astra consistently outperforms existing PEFT baselines across 16 benchmarks and even surpasses full fine-tuning (FFT) in certain scenarios.