Do LLMs and VLMs Share Neurons for Inference? Evidence and Mechanisms of Cross-Modal Transfer
作者: Chenhang Cui, An Zhang, Yuxin Chen, Gelei Deng, Jingnan Zheng, Zhenkai Liang, Xiang Wang, Tat-Seng Chua
分类: cs.CL
发布日期: 2026-02-22
🔗 代码/项目: GITHUB
💡 一句话要点
提出SNRF框架,通过共享神经元低秩融合,提升LVLM多步推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 知识迁移 共享神经元 低秩融合
📋 核心要点
- LVLM在复杂推理任务上表现不足,现有方法难以有效利用LLM的推理能力。
- 论文提出SNRF框架,通过识别并融合LLM和LVLM的共享神经元,实现推理能力的迁移。
- 实验表明,SNRF能显著提升LVLM在数学和感知任务上的推理性能,且参数效率高。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在各个领域迅速发展,但在需要多步推理和组合决策的任务上,仍然落后于强大的纯文本大型语言模型(LLMs)。受其共享Transformer架构的启发,我们研究了这两个模型家族是否依赖于共同的内部计算来进行此类推理。在神经元层面,我们发现了一个惊人的大的重叠:在多步推理过程中,超过一半的top-activated单元在代表性的LLMs和LVLMs之间共享,揭示了一个模态不变的推理子空间。通过激活放大的因果探测,我们进一步表明,这些共享神经元编码了一致且可解释的概念级效应,证明了它们对推理的功能贡献。在此基础上,我们提出了一种共享神经元低秩融合(SNRF)的参数高效框架,该框架将成熟的推理电路从LLMs转移到LVLMs。SNRF分析跨模型激活以识别共享神经元,计算模型间权重差异的低秩近似,并在共享神经元子空间内选择性地注入这些更新。这种机制以最小的参数变化增强了多模态推理性能,并且不需要大规模的多模态微调。在各种数学和感知基准测试中,SNRF始终提高LVLM的推理性能,同时保持感知能力。我们的结果表明,共享神经元在LLMs和LVLMs之间形成了一个可解释的桥梁,从而能够以低成本将推理能力转移到多模态模型中。
🔬 方法详解
问题定义:现有的大型视觉语言模型(LVLMs)在多步推理和组合决策任务上表现不如纯文本大型语言模型(LLMs)。现有的方法通常需要大规模的多模态微调,计算成本高昂,且难以有效利用LLMs中已经学习到的成熟的推理能力。因此,如何以参数高效的方式将LLMs的推理能力迁移到LVLMs是一个关键问题。
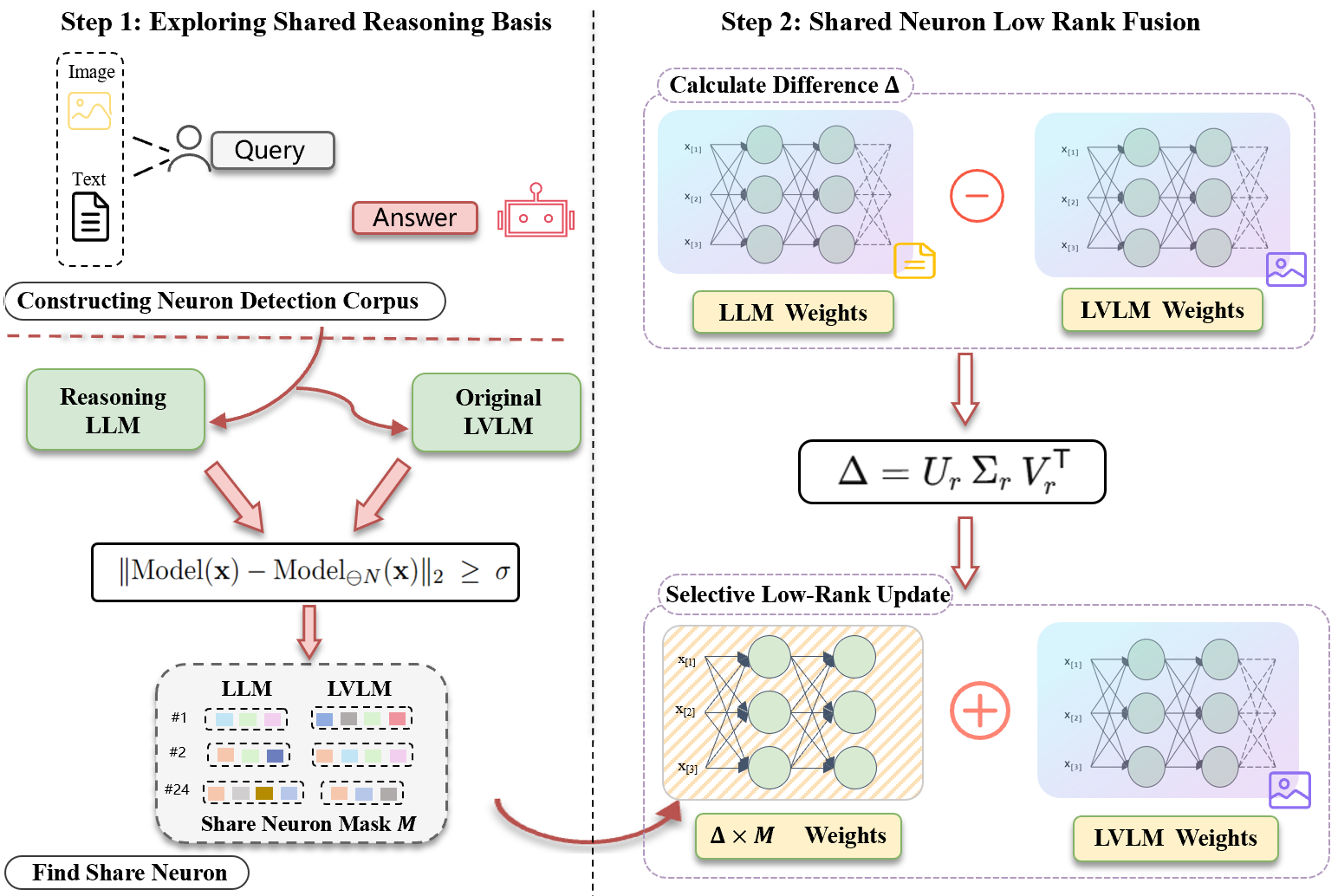
核心思路:论文的核心思路是利用LLMs和LVLMs之间共享的神经元,这些共享神经元构成了模态不变的推理子空间。通过识别这些共享神经元,并利用低秩近似来建模LLMs和LVLMs之间权重差异,可以将LLMs的推理能力选择性地注入到LVLMs中,从而提升LVLMs的推理性能。这种方法避免了大规模的微调,实现了参数高效的推理能力迁移。
技术框架:SNRF框架主要包含以下几个步骤:1) 共享神经元识别:通过分析LLMs和LVLMs在特定任务上的激活情况,识别出top-activated且在两个模型中都活跃的神经元,这些神经元被认为是共享神经元。2) 权重差异建模:计算LLMs和LVLMs在共享神经元相关的权重上的差异。为了降低计算复杂度,使用低秩近似来建模这些权重差异。3) 推理能力注入:将低秩近似的权重差异选择性地注入到LVLMs的共享神经元相关的权重中,从而将LLMs的推理能力迁移到LVLMs。
关键创新:该论文最重要的技术创新点在于发现了LLMs和LVLMs之间存在共享神经元,这些神经元构成了模态不变的推理子空间。基于这一发现,论文提出了SNRF框架,通过低秩融合的方式,实现了LLMs推理能力向LVLMs的参数高效迁移。与现有方法相比,SNRF不需要大规模的多模态微调,且能够有效提升LVLMs的推理性能。
关键设计:SNRF的关键设计包括:1) 共享神经元的选择标准:选择top-activated且在LLMs和LVLMs中都活跃的神经元作为共享神经元。2) 低秩近似的秩的选择:通过实验确定合适的低秩近似的秩,以在计算复杂度和性能之间取得平衡。3) 权重注入的方式:将低秩近似的权重差异选择性地注入到LVLMs的共享神经元相关的权重中,避免对LVLMs的感知能力造成负面影响。
🖼️ 关键图片
📊 实验亮点
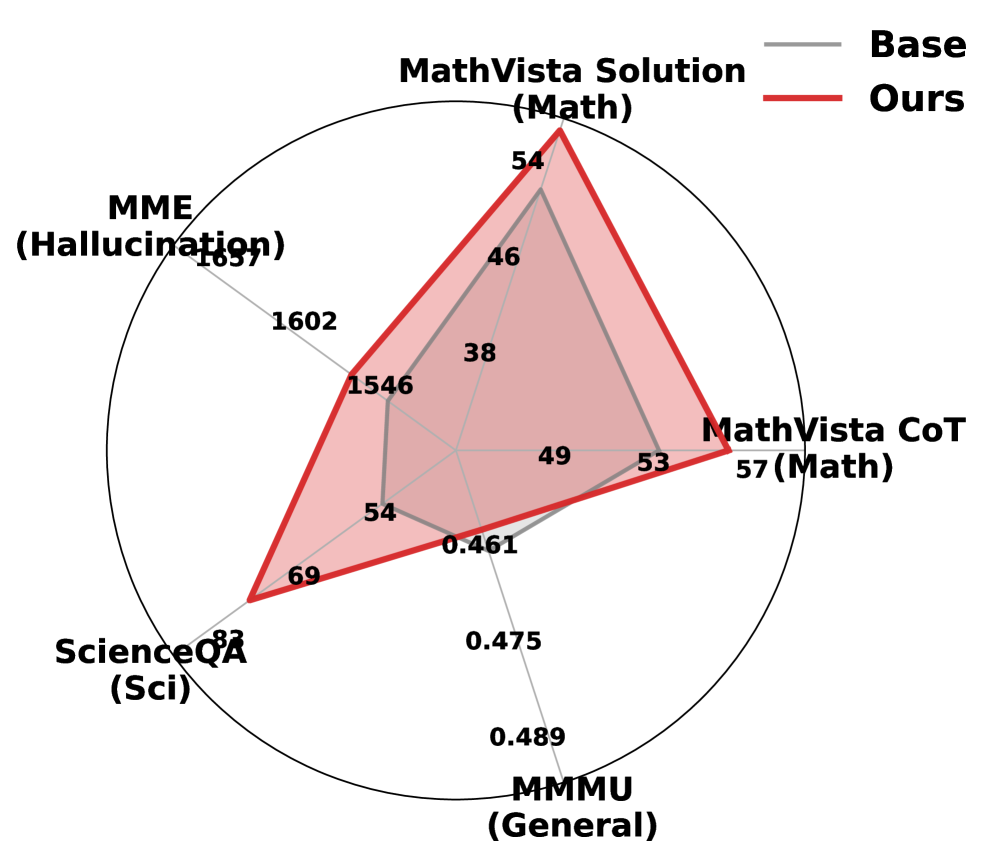
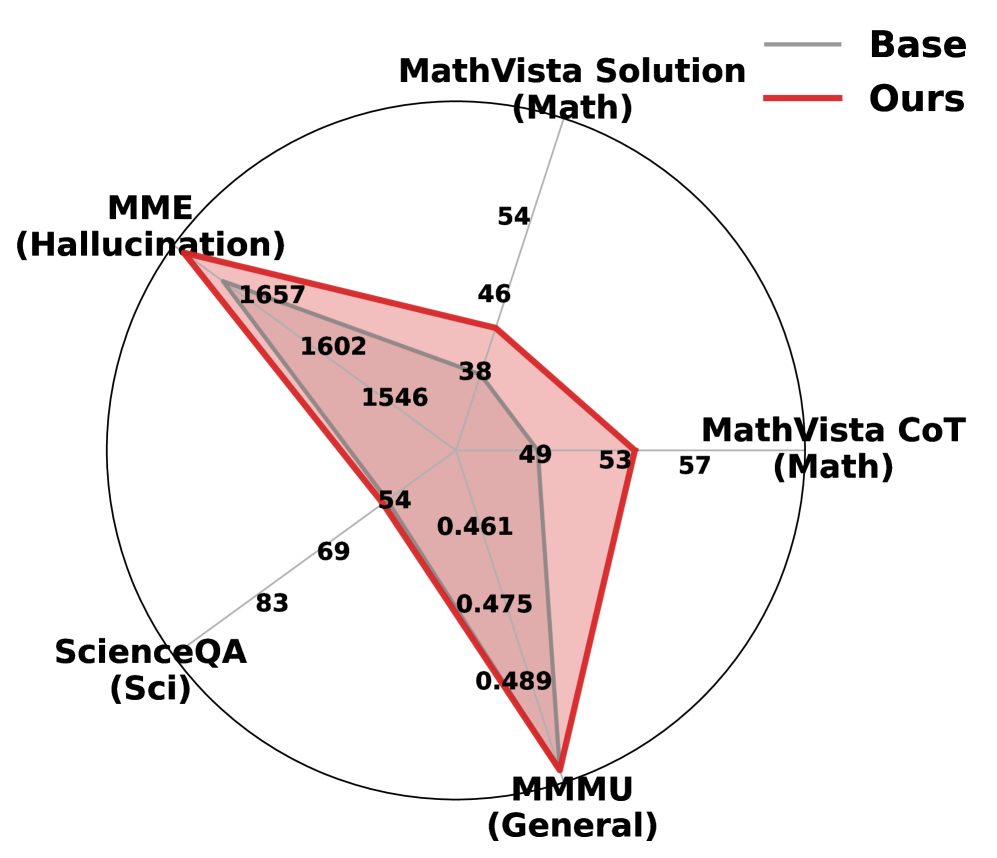
实验结果表明,SNRF框架在数学和感知基准测试中均能显著提升LVLM的推理性能。例如,在某些数学推理任务上,SNRF可以将LVLM的准确率提升超过10%。此外,SNRF的参数效率很高,只需要少量参数更新即可实现显著的性能提升,同时保持了LVLM原有的感知能力。
🎯 应用场景
该研究成果可应用于各种需要多模态推理的场景,例如视觉问答、图像描述生成、机器人导航等。通过将LLM的推理能力迁移到LVLM,可以提升这些应用在复杂任务上的性能,并降低模型训练和部署的成本。未来,该方法可以进一步扩展到其他模态和任务,实现更广泛的知识迁移和模型增强。
📄 摘要(原文)
Large vision-language models (LVLMs) have rapidly advanced across various domains, yet they still lag behind strong text-only large language models (LLMs) on tasks that require multi-step inference and compositional decision-making. Motivated by their shared transformer architectures, we investigate whether the two model families rely on common internal computation for such inference. At the neuron level, we uncover a surprisingly large overlap: more than half of the top-activated units during multi-step inference are shared between representative LLMs and LVLMs, revealing a modality-invariant inference subspace. Through causal probing via activation amplification, we further show that these shared neurons encode consistent and interpretable concept-level effects, demonstrating their functional contribution to inference. Building on this insight, we propose Shared Neuron Low-Rank Fusion (SNRF), a parameter-efficient framework that transfers mature inference circuitry from LLMs to LVLMs. SNRF profiles cross-model activations to identify shared neurons, computes a low-rank approximation of inter-model weight differences, and injects these updates selectively within the shared-neuron subspace. This mechanism strengthens multimodal inference performance with minimal parameter changes and requires no large-scale multimodal fine-tuning. Across diverse mathematics and perception benchmarks, SNRF consistently enhances LVLM inference performance while preserving perceptual capabilities. Our results demonstrate that shared neurons form an interpretable bridge between LLMs and LVLMs, enabling low-cost transfer of inference ability into multimodal models. Our code is available at https://github.com/chenhangcuisg-code/Do-LLMs-VLMs-Share-Neurons.