IAPO: Information-Aware Policy Optimization for Token-Efficient Reasoning
作者: Yinhan He, Yaochen Zhu, Mingjia Shi, Wendy Zheng, Lin Su, Xiaoqing Wang, Qi Guo, Jundong Li
分类: cs.CL, cs.LG
发布日期: 2026-02-22
🔗 代码/项目: GITHUB
💡 一句话要点
提出IAPO,通过信息论优化策略,提升大模型推理效率并缩短推理链。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息论 策略优化 语言模型 推理效率 互信息
📋 核心要点
- 现有序列级奖励塑造方法对推理过程中token的利用率控制不足,导致推理效率低下。
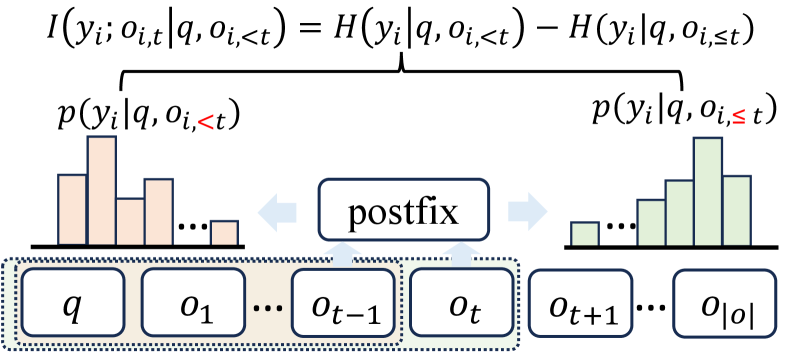
- IAPO通过计算token与最终答案的条件互信息,为每个token分配优势,从而优化推理过程。
- 实验表明,IAPO在提高推理准确性的同时,显著减少了推理长度,优于现有方法。
📝 摘要(中文)
大型语言模型越来越多地依赖于长链思维来提高准确性,但这种提升伴随着巨大的推理时间成本。本文重新审视了token高效的后训练方法,并指出现有的序列级奖励塑造方法对推理过程中的token分配控制有限。为了弥合这一差距,我们提出了IAPO,一个信息论的后训练框架,它根据每个token与最终答案的条件互信息(MI)来分配token级别的优势。这为识别信息丰富的推理步骤和抑制低效探索提供了一个显式的、有原则的机制。我们提供了一个理论分析,表明我们的IAPO可以在不损害正确性的前提下,单调地减少推理冗余。实验结果表明,IAPO在各种推理数据集上始终提高推理准确性,同时将推理长度最多减少36%,优于现有的token高效RL方法。广泛的实验评估表明,信息感知的优势塑造是token高效后训练的一个强大而通用的方向。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在推理过程中token利用率低下的问题。现有方法,特别是序列级别的奖励塑造方法,无法精细地控制每个token的贡献,导致推理链冗长,计算成本高昂。这些方法缺乏对token重要性的区分,无法有效抑制低效的探索。
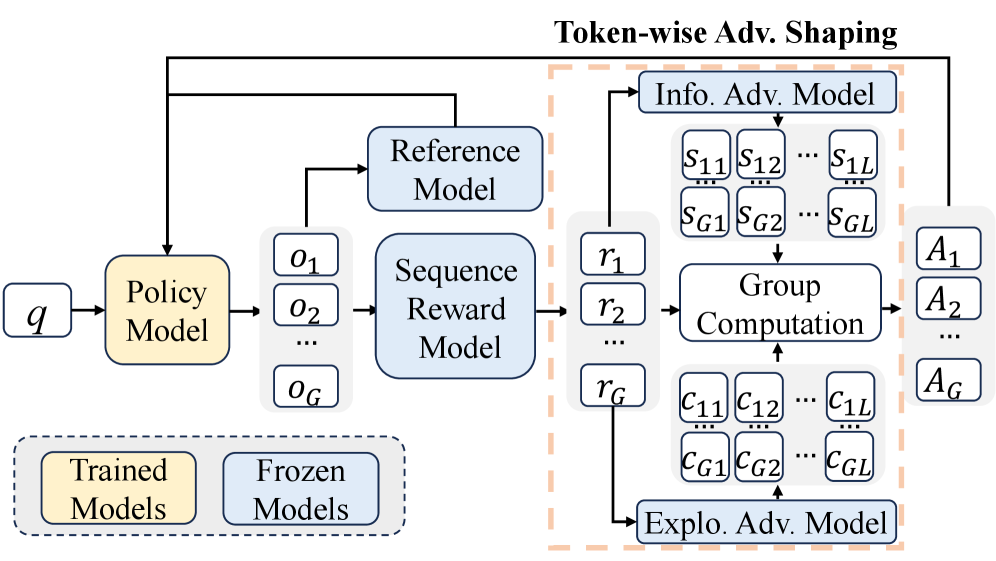
核心思路:IAPO的核心思路是利用信息论中的互信息来衡量每个token对最终答案的贡献。通过计算每个token与最终答案的条件互信息,可以评估该token所包含的信息量。然后,根据这个信息量来分配token级别的优势,鼓励模型生成信息量大的token,抑制信息量小的token,从而优化推理过程。
技术框架:IAPO是一个后训练框架,其主要流程如下:1) 使用大型语言模型生成推理链;2) 计算每个token与最终答案的条件互信息;3) 基于互信息计算token级别的优势;4) 使用优势函数调整模型的策略,鼓励生成高优势的token。这个过程可以迭代进行,逐步优化模型的推理策略。
关键创新:IAPO的关键创新在于提出了信息感知的优势塑造方法。与传统的奖励塑造方法不同,IAPO直接基于信息论的互信息来评估token的价值,从而能够更准确地识别重要的推理步骤。这种方法提供了一种显式的、有原则的机制来控制推理过程,避免了盲目的探索。
关键设计:IAPO的关键设计包括:1) 使用条件互信息作为token优势的度量;2) 设计合适的优势函数,将互信息转化为奖励信号;3) 使用策略梯度方法优化模型,鼓励生成高优势的token。具体而言,条件互信息的计算需要估计token和答案的联合概率分布,这可以通过采样或近似方法来实现。优势函数的设计需要平衡探索和利用,避免模型过早收敛到局部最优解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,IAPO在多个推理数据集上显著提高了推理准确性,同时减少了推理长度。例如,在某些数据集上,IAPO可以将推理长度减少高达36%,同时保持或提高推理准确性。IAPO的性能优于现有的token高效RL方法,证明了信息感知的优势塑造在token高效后训练中的有效性。
🎯 应用场景
IAPO具有广泛的应用前景,可以应用于各种需要长链推理的场景,例如问答系统、知识图谱推理、代码生成等。通过提高推理效率,IAPO可以降低计算成本,提高系统的响应速度,并促进大型语言模型在资源受限环境中的部署。此外,IAPO还可以用于分析模型的推理过程,帮助理解模型的决策机制。
📄 摘要(原文)
Large language models increasingly rely on long chains of thought to improve accuracy, yet such gains come with substantial inference-time costs. We revisit token-efficient post-training and argue that existing sequence-level reward-shaping methods offer limited control over how reasoning effort is allocated across tokens. To bridge the gap, we propose IAPO, an information-theoretic post-training framework that assigns token-wise advantages based on each token's conditional mutual information (MI) with the final answer. This yields an explicit, principled mechanism for identifying informative reasoning steps and suppressing low-utility exploration. We provide a theoretical analysis showing that our IAPO can induce monotonic reductions in reasoning verbosity without harming correctness. Empirically, IAPO consistently improves reasoning accuracy while reducing reasoning length by up to 36%, outperforming existing token-efficient RL methods across various reasoning datasets. Extensive empirical evaluations demonstrate that information-aware advantage shaping is a powerful and general direction for token-efficient post-training. The code is available at https://github.com/YinhanHe123/IAPO.