Uncovering Context Reliance in Unstructured Knowledge Editing
作者: Zisheng Zhou, Mengqi Zhang, Shiguang Wu, Xiaotian Ye, Chi Zhang, Zhumin Chen, Pengjie Ren
分类: cs.CL
发布日期: 2026-02-22
备注: 21 pages, 14 figures
💡 一句话要点
提出COIN框架,解决非结构化知识编辑中LLM对上下文的过度依赖问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识编辑 大型语言模型 上下文依赖 非结构化知识 下一个token预测
📋 核心要点
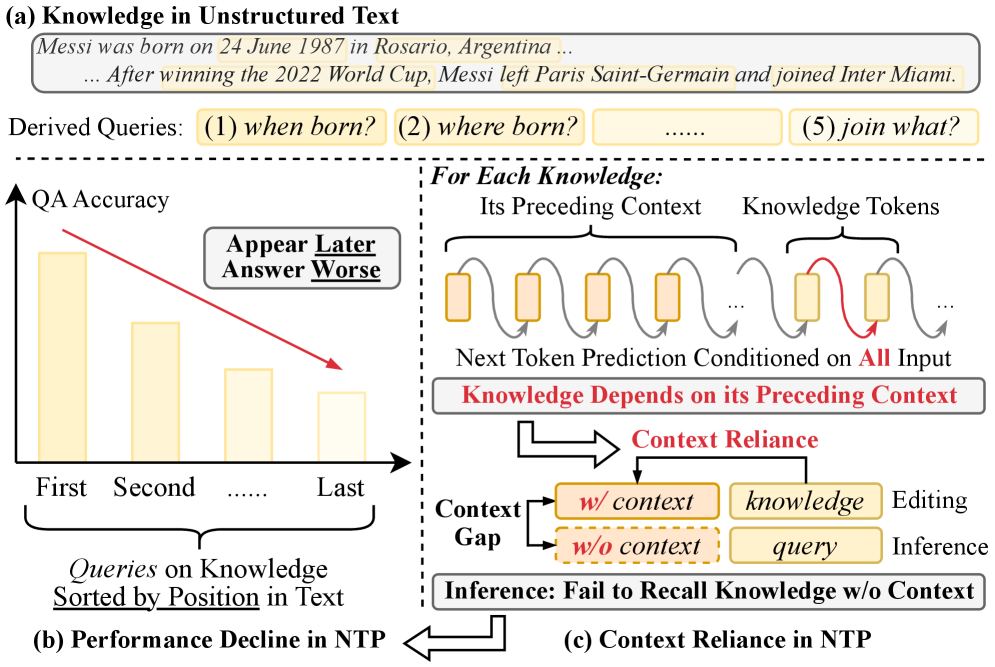
- 现有基于NTP的知识编辑方法存在“上下文依赖”问题,即模型过度依赖编辑文本的上下文。
- COIN框架通过鼓励模型关注局部知识,减少对上下文的依赖,从而提高编辑的泛化能力。
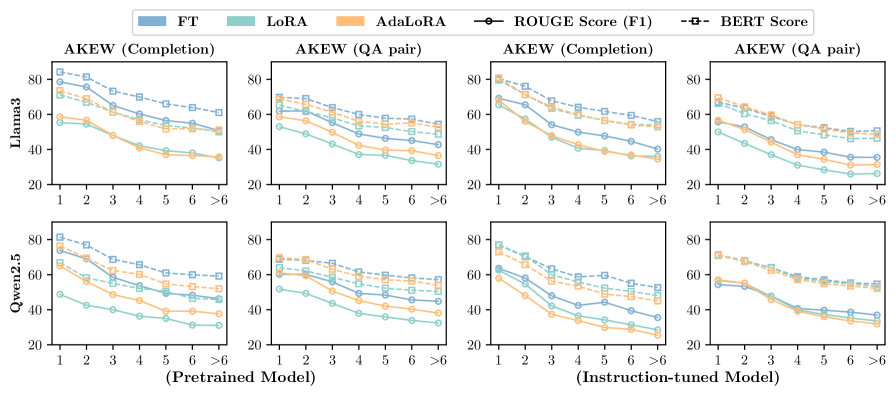
- 实验表明,COIN框架显著降低了上下文依赖,并在编辑成功率上超越了现有方法。
📝 摘要(中文)
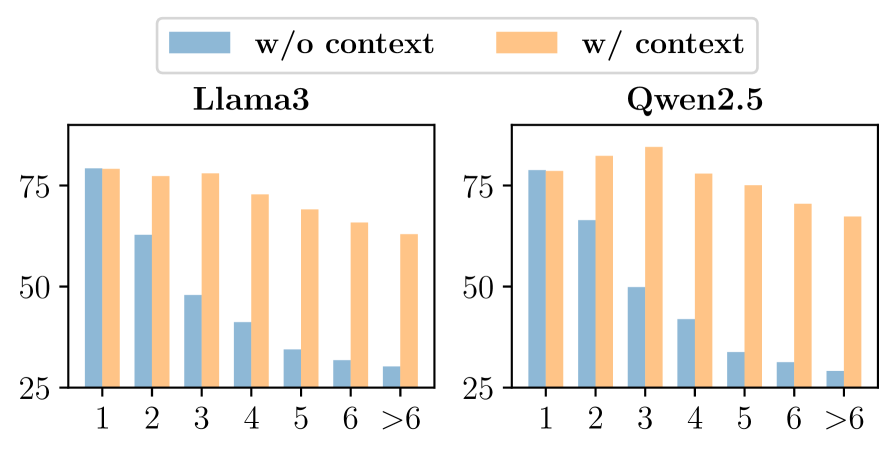
本文研究了使用真实世界非结构化知识编辑大型语言模型(LLMs)的问题,这对于修正和更新其内部参数化知识至关重要。我们重新审视了基于下一个token预测(NTP)的非结构化编辑范式,并发现“上下文依赖”是NTP方法的一个关键失败模式。在这种模式下,从编辑文本中获得的知识高度依赖于其前置上下文,导致在缺乏该上下文时出现召回失败。我们的实验验证表明,在推理时添加前置上下文可以恢复知识召回,从而支持了这一假设。我们进一步从理论上证明,上下文依赖是基于梯度的优化固有的结果,它倾向于将获得的知识与特定的聚合上下文表示绑定。为了解决这个问题,我们提出了一个简单而有效的上下文独立编辑框架(COIN),鼓励模型关注局部范围内的知识,而不是记忆上下文模式。评估结果表明,COIN将上下文依赖降低了45.2%,并在编辑成功率方面优于强大的基线方法23.6%,突出了缓解上下文依赖对于鲁棒编辑的关键作用。
🔬 方法详解
问题定义:现有基于下一个token预测(NTP)的知识编辑方法,在处理非结构化知识时,存在严重的“上下文依赖”问题。这意味着模型学习到的知识与编辑文本的上下文紧密绑定,当推理时上下文发生变化或缺失时,模型无法正确召回或应用这些知识。这种上下文依赖性限制了知识编辑的泛化能力和鲁棒性。
核心思路:COIN框架的核心思路是减少模型对上下文的依赖,鼓励模型更多地关注局部范围内的知识。通过让模型学习更通用的知识表示,而不是记忆特定的上下文模式,从而提高知识编辑的泛化能力。COIN框架旨在使编辑后的模型在各种上下文下都能正确地应用编辑后的知识。
技术框架:COIN框架主要包含两个阶段:编辑阶段和推理阶段。在编辑阶段,COIN使用特定的损失函数来训练模型,以减少上下文依赖。在推理阶段,COIN可以直接使用编辑后的模型进行知识推理,无需额外的处理。整体流程简单高效,易于实现。
关键创新:COIN框架的关键创新在于其上下文独立性设计。与传统的NTP方法不同,COIN通过特定的训练目标,鼓励模型学习与上下文无关的知识表示。这种设计使得模型能够更好地泛化到不同的上下文,从而提高了知识编辑的鲁棒性。
关键设计:COIN框架的关键设计在于其损失函数。该损失函数旨在惩罚模型对上下文的过度依赖,并鼓励模型关注局部范围内的知识。具体的损失函数形式未知,但其核心思想是减少模型对上下文信息的利用,从而实现上下文独立性。此外,COIN框架可能还包含一些其他的技术细节,例如特定的正则化方法或网络结构设计,以进一步提高模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,COIN框架能够显著降低上下文依赖,降低幅度达到45.2%。同时,在编辑成功率方面,COIN框架也优于现有的强大基线方法,提升幅度达到23.6%。这些数据表明,COIN框架在解决上下文依赖问题方面具有显著优势,能够有效提高知识编辑的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于各种需要知识更新和修正的场景,例如:自动问答系统、对话机器人、信息检索等。通过使用COIN框架,可以更有效地编辑LLM的知识,提高其在各种上下文下的表现,从而提升用户体验和应用价值。未来,该技术有望在教育、医疗、金融等领域发挥重要作用。
📄 摘要(原文)
Editing Large language models (LLMs) with real-world, unstructured knowledge is essential for correcting and updating their internal parametric knowledge. In this work, we revisit the fundamental next-token prediction (NTP) as a candidate paradigm for unstructured editing. We identify Context Reliance as a critical failure mode of NTP-based approaches, where knowledge acquired from edited text becomes highly dependent on its preceding context, leading to recall failures when that context is absent during inference. This hypothesis is supported by our empirical validation that prepending context during inference recovers knowledge recall. We further theoretically demonstrate that Context Reliance is an inherent consequence of gradient-based optimization, which tends to bind acquired knowledge to a specific aggregated contextual representation. To address this, we propose a simple yet effective COntext-INdependent editing framework (COIN), encouraging model to focus on knowledge within local scope rather than memorizing contextual patterns. Evaluations show that COIN reduces Context Reliance by 45.2% and outperforms strong baselines by 23.6% in editing success rate, highlighting the vital role of mitigating Context Reliance for robust editing.