DeepInnovator: Triggering the Innovative Capabilities of LLMs
作者: Tianyu Fan, Fengji Zhang, Yuxiang Zheng, Bei Chen, Xinyao Niu, Chengen Huang, Junyang Lin, Chao Huang
分类: cs.CL, cs.AI
发布日期: 2026-02-21
🔗 代码/项目: GITHUB
💡 一句话要点
提出DeepInnovator以激发大语言模型的创新能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 创新能力 自动化数据提取 下一想法预测 科学发现 训练框架
📋 核心要点
- 现有方法主要依赖复杂的提示工程,缺乏系统的训练范式,限制了LLMs的创新能力。
- 提出DeepInnovator训练框架,通过自动化数据提取和下一想法预测训练范式激发LLMs的创新能力。
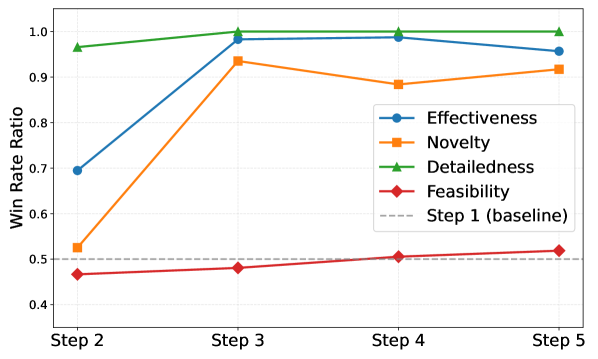
- DeepInnovator-14B在实验中表现优异,赢率高达80.53%-93.81%,与领先的LLMs性能相当。
📝 摘要(中文)
大语言模型(LLMs)在加速科学发现中的应用引起了越来越多的关注,尤其是在构建具备创新能力的研究代理方面。现有方法主要依赖复杂的提示工程,缺乏系统的训练范式。为此,本文提出了DeepInnovator,一个旨在激发LLMs创新能力的训练框架。该方法包括两个核心组件:一是构建自动化数据提取管道,从大量未标记的科学文献中提取和组织结构化研究知识;二是引入“下一想法预测”训练范式,将研究想法的生成建模为一个持续预测、评估和完善新想法的迭代过程。实验结果表明,DeepInnovator-14B显著优于未训练的基线,赢率达到80.53%-93.81%,性能与当前领先的LLMs相当。该研究为构建具备真正原创性创新能力的研究代理提供了可扩展的训练路径,并将开源数据集以促进社区发展。
🔬 方法详解
问题定义:本文旨在解决现有大语言模型在创新能力方面的不足,特别是缺乏系统化训练的痛点。
核心思路:通过构建自动化数据提取管道和引入“下一想法预测”训练范式,DeepInnovator能够有效激发LLMs的创新能力。
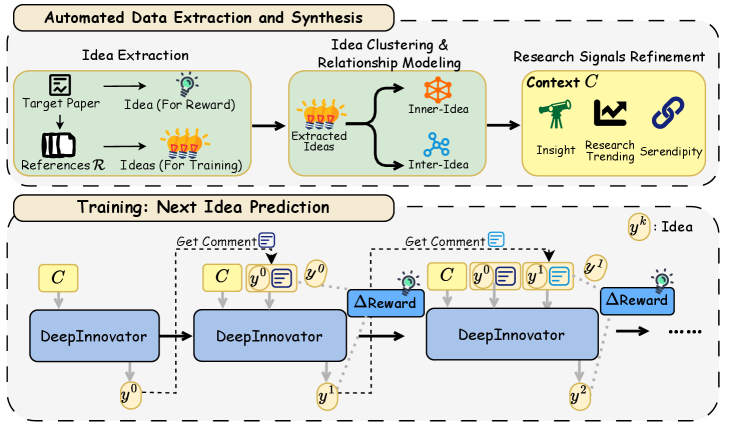
技术框架:整体架构包括两个主要模块:数据提取模块和训练模块。数据提取模块负责从未标记的科学文献中提取结构化知识,训练模块则通过迭代预测和评估生成新想法。
关键创新:最重要的创新在于“下一想法预测”训练范式,它将研究想法的生成视为一个动态的迭代过程,与传统的静态生成方法有本质区别。
关键设计:在参数设置上,DeepInnovator-14B采用了特定的损失函数和网络结构,以优化生成过程中的预测精度和创新性。
🖼️ 关键图片
📊 实验亮点
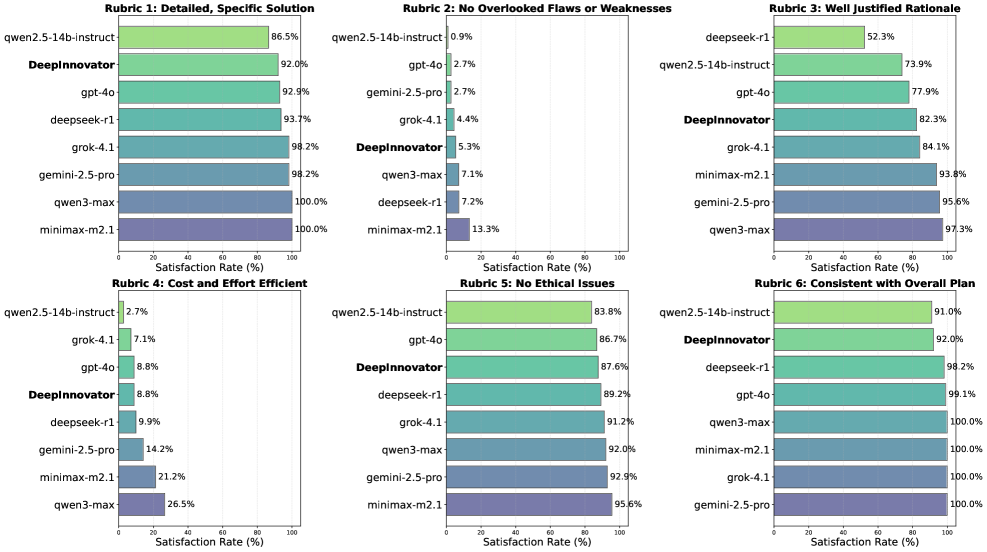
DeepInnovator-14B在实验中表现出色,赢率达到80.53%-93.81%,显著优于未训练的基线,且性能与当前领先的LLMs相当。这一结果表明该方法在激发创新能力方面的有效性。
🎯 应用场景
该研究的潜在应用领域包括科学研究、技术创新和知识发现等。通过激发LLMs的创新能力,DeepInnovator可以帮助研究人员快速生成新颖的研究想法,从而加速科学发现的进程,具有重要的实际价值和未来影响。
📄 摘要(原文)
The application of Large Language Models (LLMs) in accelerating scientific discovery has garnered increasing attention, with a key focus on constructing research agents endowed with innovative capability, i.e., the ability to autonomously generate novel and significant research ideas. Existing approaches predominantly rely on sophisticated prompt engineering and lack a systematic training paradigm. To address this, we propose DeepInnovator, a training framework designed to trigger the innovative capability of LLMs. Our approach comprises two core components. (1)
Standing on the shoulders of giants''. We construct an automated data extraction pipeline to extract and organize structured research knowledge from a vast corpus of unlabeled scientific literature. (2)Conjectures and refutations''. We introduce a ``Next Idea Prediction'' training paradigm, which models the generation of research ideas as an iterative process of continuously predicting, evaluating, and refining plausible and novel next idea. Both automatic and expert evaluations demonstrate that our DeepInnovator-14B significantly outperforms untrained baselines, achieving win rates of 80.53\%-93.81\%, and attains performance comparable to that of current leading LLMs. This work provides a scalable training pathway toward building research agents with genuine, originative innovative capability, and will open-source the dataset to foster community advancement. Source code and data are available at: https://github.com/HKUDS/DeepInnovator.