Think$^{2}$: Grounded Metacognitive Reasoning in Large Language Models
作者: Abraham Paul Elenjical, Vivek Hruday Kavuri, Vasudeva Varma
分类: cs.CL, cs.AI
发布日期: 2026-02-21
💡 一句话要点
Think$^{2}$:提出基于认知理论的元认知框架,提升大语言模型推理和自我纠错能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 元认知 推理 自我纠错 认知心理学 提示工程 可解释性
📋 核心要点
- 现有大语言模型在推理能力方面表现出色,但缺乏可靠的自我监控、诊断和纠错机制,限制了其应用。
- 论文提出Think$^{2}$框架,将认知心理学中的元认知理论(计划、监控、评估)融入LLM,提升其推理过程的透明性和可控性。
- 实验结果表明,Think$^{2}$框架显著提升了LLM在多个推理和诊断任务中的错误诊断和自我纠正能力,并获得了人类评估的认可。
📝 摘要(中文)
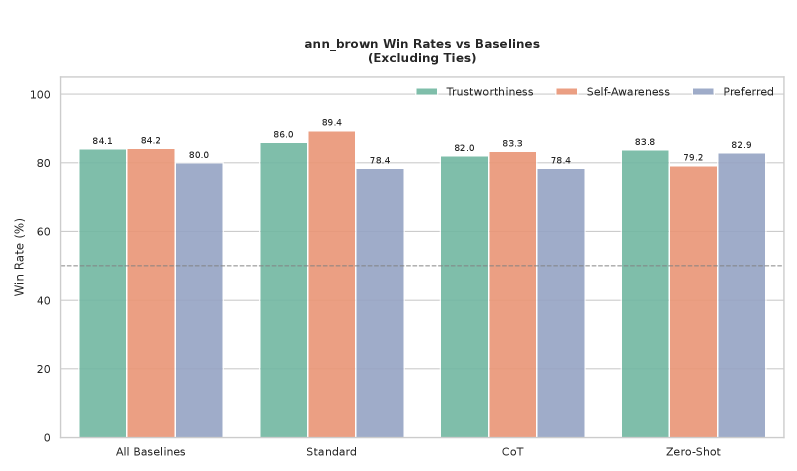
大型语言模型(LLMs)展现出强大的推理能力,但其可靠地监控、诊断和纠正自身错误的能力仍然有限。我们引入了一个心理学基础的元认知框架,该框架将Ann Brown的调节循环(计划、监控和评估)操作化为一个结构化的提示架构,并研究其在轻量级双过程MetaController中的集成,以实现自适应的努力分配。在使用Llama-3和Qwen-3(8B)的各种推理和诊断基准(GSM8K、CRUXEval、MBPP、AIME、CorrectBench和TruthfulQA)上,显式的调节结构显著改善了错误诊断,并使成功的自我纠正增加了三倍。对580个查询对进行的盲人人工评估显示,与标准和思维链基线相比,总体上有84%的偏好倾向于信任度和元认知自我意识。将LLM推理建立在已建立的认知理论基础上,为更透明和诊断鲁棒的AI系统提供了一条有原则的道路。
🔬 方法详解
问题定义:现有的大语言模型虽然在推理任务上取得了显著进展,但它们在推理过程中缺乏有效的自我监控和纠错机制。这导致模型在面对复杂问题时容易产生错误,并且难以识别和纠正这些错误。现有方法通常依赖于简单的思维链(Chain-of-Thought)提示,缺乏对推理过程的深入控制和诊断能力。
核心思路:论文的核心思路是将认知心理学中的元认知理论引入到大语言模型中。元认知是指个体对自身认知过程的认知和控制能力,包括计划、监控和评估三个关键环节。通过模拟人类的元认知过程,可以使大语言模型更好地理解自身的推理过程,并及时发现和纠正错误。
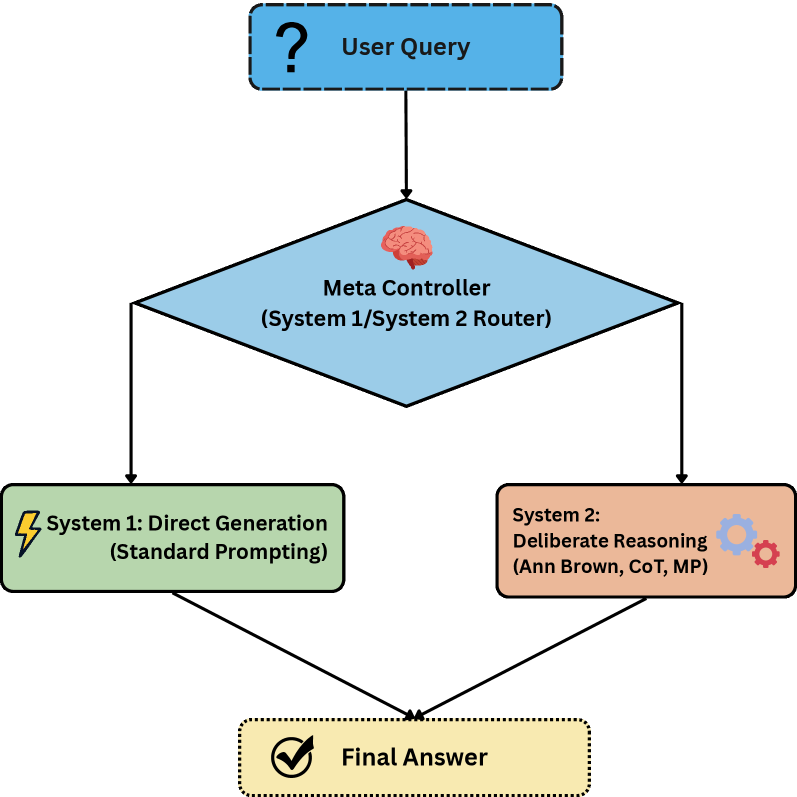
技术框架:Think$^{2}$框架主要包含三个阶段,对应于元认知理论的三个环节:计划(Planning)、监控(Monitoring)和评估(Evaluation)。在计划阶段,模型制定推理策略;在监控阶段,模型评估当前推理步骤的合理性;在评估阶段,模型总结推理过程并进行自我纠正。此外,论文还引入了一个MetaController模块,用于自适应地分配计算资源,决定何时进行监控和评估。
关键创新:Think$^{2}$框架的关键创新在于将认知心理学理论与大语言模型相结合,提出了一种结构化的元认知推理框架。与传统的思维链方法相比,Think$^{2}$框架更加强调对推理过程的显式控制和诊断,从而提高了模型的推理能力和可靠性。MetaController的引入使得模型能够根据问题的难度自适应地调整推理策略,进一步提升了效率。
关键设计:Think$^{2}$框架的关键设计包括:(1) 使用结构化的提示模板来引导模型进行计划、监控和评估;(2) 设计MetaController模块,根据推理过程中的不确定性动态调整计算资源的分配;(3) 使用特定的损失函数来鼓励模型进行准确的错误诊断和自我纠正。具体的提示模板和MetaController的实现细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Think$^{2}$框架在GSM8K、CRUXEval、MBPP、AIME、CorrectBench和TruthfulQA等多个推理和诊断基准上取得了显著的性能提升。例如,在CorrectBench数据集上,Think$^{2}$框架使成功的自我纠正增加了三倍。此外,人工评估结果显示,84%的受访者更倾向于Think$^{2}$框架的输出,认为其更具信任度和元认知自我意识。
🎯 应用场景
Think$^{2}$框架具有广泛的应用前景,可以应用于各种需要可靠推理和决策的场景,例如:自动驾驶、医疗诊断、金融风险评估等。通过提高大语言模型的推理能力和可靠性,可以使其在这些领域发挥更大的作用。此外,Think$^{2}$框架还可以用于开发更透明和可解释的AI系统,从而增强人们对AI的信任。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate strong reasoning performance, yet their ability to reliably monitor, diagnose, and correct their own errors remains limited. We introduce a psychologically grounded metacognitive framework that operationalizes Ann Brown's regulatory cycle (Planning, Monitoring, and Evaluation) as a structured prompting architecture, and study its integration within a lightweight dual-process MetaController for adaptive effort allocation. Across diverse reasoning and diagnostic benchmarks (GSM8K, CRUXEval, MBPP, AIME, CorrectBench, and TruthfulQA) using Llama-3 and Qwen-3 (8B), explicit regulatory structuring substantially improves error diagnosis and yields a threefold increase in successful self-correction. Blinded human evaluations over 580 query pairs show an 84% aggregate preference for trustworthiness and metacognitive self-awareness over standard and Chain-of-Thought baselines. Grounding LLM reasoning in established cognitive theory offers a principled path toward more transparent and diagnostically robust AI systems.