BURMESE-SAN: Burmese NLP Benchmark for Evaluating Large Language Models
作者: Thura Aung, Jann Railey Montalan, Jian Gang Ngui, Peerat Limkonchotiwat
分类: cs.CL
发布日期: 2026-02-21
💡 一句话要点
提出BURMESE-SAN,用于系统评估大型语言模型在缅甸语上的理解、推理和生成能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 缅甸语NLP 大型语言模型 基准测试 自然语言理解 自然语言生成 低资源语言 模型评估
📋 核心要点
- 现有缅甸语NLP基准测试不足,缺乏对大型语言模型在理解、推理和生成能力上的全面评估。
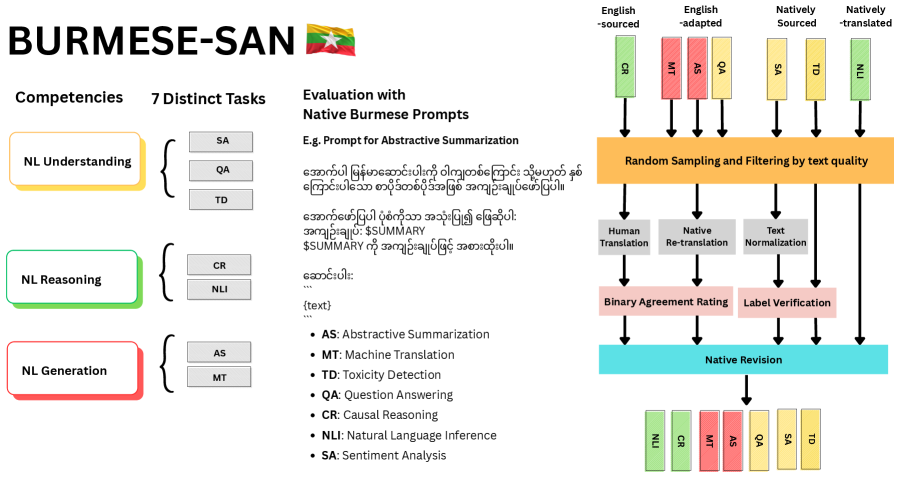
- BURMESE-SAN通过整合七个子任务,涵盖理解、推理和生成三个核心NLP能力,构建了全面的评估基准。
- 实验结果表明,模型架构、语言表示和指令微调对缅甸语性能影响显著,东南亚区域微调和新模型带来提升。
📝 摘要(中文)
本文介绍了BURMESE-SAN,这是首个全面评估大型语言模型(LLM)在缅甸语上的自然语言处理能力的标准。该基准系统地评估了LLM在三个核心NLP能力上的表现:理解(NLU)、推理(NLR)和生成(NLG)。BURMESE-SAN整合了七个涵盖这些能力的子任务,包括问答、情感分析、毒性检测、因果推理、自然语言推理、抽象摘要和机器翻译,其中一些任务以前在缅甸语中不可用。该基准通过严格的母语者驱动流程构建,以确保语言的自然性、流畅性和文化真实性,同时最大限度地减少翻译引起的伪影。我们对开放权重和商业LLM进行了大规模评估,以检验缅甸语建模中由于有限的预训练覆盖率、丰富的形态和句法变异而产生的挑战。结果表明,缅甸语的性能更多地取决于架构设计、语言表示和指令调整,而不是仅仅取决于模型规模。特别是,东南亚区域微调和更新的模型世代带来了显著的收益。最后,我们发布BURMESE-SAN作为一个公共排行榜,以支持对缅甸语和其他低资源语言的系统评估和持续进展。
🔬 方法详解
问题定义:论文旨在解决缺乏针对缅甸语的大型语言模型(LLM)全面评估基准的问题。现有方法无法系统地评估LLM在缅甸语的理解、推理和生成能力,阻碍了该语言NLP技术的发展。此外,缅甸语的低资源特性、丰富的形态和句法变异也给LLM带来了独特的挑战。
核心思路:论文的核心思路是构建一个综合性的基准测试集BURMESE-SAN,该基准包含多个涵盖不同NLP能力的子任务,并通过母语者驱动的流程来保证数据的质量和真实性。通过在该基准上评估不同的LLM,可以深入了解它们在缅甸语上的表现,并为未来的研究提供指导。
技术框架:BURMESE-SAN基准测试包含七个子任务,涵盖了自然语言理解(NLU)、自然语言推理(NLR)和自然语言生成(NLG)三个核心NLP能力。这些子任务包括:问答、情感分析、毒性检测、因果推理、自然语言推理、抽象摘要和机器翻译。该基准的构建过程包括数据收集、标注、质量控制等环节,并由母语者进行审核,以确保数据的准确性和自然性。
关键创新:BURMESE-SAN是首个针对缅甸语的综合性NLP基准测试,它填补了该领域的一个空白。该基准的构建过程注重语言的自然性和文化真实性,避免了翻译带来的伪影。此外,该基准还提供了一个公共排行榜,方便研究人员进行模型评估和比较。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,论文强调了数据质量的重要性,并采用了严格的质量控制流程来保证数据的准确性和一致性。此外,论文还强调了指令微调和区域微调对模型性能的影响,表明这些技术可以有效地提高LLM在缅甸语上的表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,缅甸语性能不仅取决于模型规模,更依赖于架构设计、语言表示和指令微调。东南亚区域微调和新一代模型带来了显著的性能提升。BURMESE-SAN基准测试的发布,为缅甸语和其他低资源语言的NLP研究提供了宝贵的资源。
🎯 应用场景
BURMESE-SAN可用于评估和改进大型语言模型在缅甸语上的性能,推动缅甸语自然语言处理技术的发展。该基准可应用于机器翻译、情感分析、问答系统等多个领域,为缅甸语用户提供更好的信息服务和人机交互体验。此外,该研究也为其他低资源语言的NLP基准构建提供了借鉴。
📄 摘要(原文)
We introduce BURMESE-SAN, the first holistic benchmark that systematically evaluates large language models (LLMs) for Burmese across three core NLP competencies: understanding (NLU), reasoning (NLR), and generation (NLG). BURMESE-SAN consolidates seven subtasks spanning these competencies, including Question Answering, Sentiment Analysis, Toxicity Detection, Causal Reasoning, Natural Language Inference, Abstractive Summarization, and Machine Translation, several of which were previously unavailable for Burmese. The benchmark is constructed through a rigorous native-speaker-driven process to ensure linguistic naturalness, fluency, and cultural authenticity while minimizing translation-induced artifacts. We conduct a large-scale evaluation of both open-weight and commercial LLMs to examine challenges in Burmese modeling arising from limited pretraining coverage, rich morphology, and syntactic variation. Our results show that Burmese performance depends more on architectural design, language representation, and instruction tuning than on model scale alone. In particular, Southeast Asia regional fine-tuning and newer model generations yield substantial gains. Finally, we release BURMESE-SAN as a public leaderboard to support systematic evaluation and sustained progress in Burmese and other low-resource languages. https://leaderboard.sea-lion.ai/detailed/MY