Contradiction to Consensus: Dual Perspective, Multi Source Retrieval Based Claim Verification with Source Level Disagreement using LLM
作者: Md Badsha Biswas, Ozlem Uzuner
分类: cs.CL
发布日期: 2026-02-21
💡 一句话要点
提出基于双重视角和多源检索的声明验证系统,利用LLM分析来源层面的不一致性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 声明验证 事实核查 大型语言模型 多源检索 知识聚合
📋 核心要点
- 现有声明验证系统依赖单一知识源,忽略了不同来源之间的分歧,限制了知识覆盖和透明性。
- 提出一种新颖的开放域声明验证系统,利用LLM、多视角证据检索和跨源分歧分析。
- 实验表明,知识聚合能有效改进声明验证,并揭示不同来源的推理差异,提升系统可靠性。
📝 摘要(中文)
数字平台上错误信息的传播会带来严重的社会风险。声明验证(又称事实核查)系统可以帮助识别潜在的错误信息。然而,它们的有效性受到所依赖的知识来源的限制。大多数自动声明验证系统依赖于单一知识来源,并利用该来源的支持证据,忽略了其来源与其他来源的分歧。这限制了它们的知识覆盖范围和透明度。为了解决这些限制,我们提出了一个新颖的开放域声明验证(ODCV)系统,该系统利用大型语言模型(LLM)、多视角证据检索和跨源分歧分析。我们的方法引入了一种新颖的检索策略,该策略收集原始声明和否定形式的证据,使系统能够从不同的来源(维基百科、PubMed和谷歌)捕获支持和矛盾的信息。这些证据集经过过滤、去重和跨源聚合,形成一个统一且丰富的知识库,更好地反映了真实世界信息的复杂性。然后,使用聚合的证据通过LLM进行声明验证。我们通过分析模型置信度分数来量化和可视化源间分歧,从而进一步增强可解释性。通过对五个LLM在四个基准数据集上的广泛评估,我们表明知识聚合不仅改进了声明验证,还揭示了源特定推理的差异。我们的研究结果强调了在证据中拥抱多样性、矛盾和聚合对于构建可靠和透明的声明验证系统的重要性。
🔬 方法详解
问题定义:论文旨在解决开放域声明验证任务中,现有方法依赖单一知识来源、忽略来源间分歧的问题。现有方法无法充分利用多源信息,导致知识覆盖范围有限,且缺乏透明度,难以解释验证结果的可信度。
核心思路:论文的核心思路是利用大型语言模型(LLM)进行声明验证,并结合多视角证据检索和跨源分歧分析。通过检索原始声明和否定形式的证据,从多个来源获取支持和反对信息,从而构建更全面、更丰富的知识库。
技术框架:该系统包含以下主要模块:1) 多视角证据检索:从维基百科、PubMed和谷歌等多个来源检索原始声明和否定形式的证据。2) 证据过滤和聚合:对检索到的证据进行过滤、去重和聚合,形成统一的知识库。3) 基于LLM的声明验证:利用LLM对聚合后的证据进行分析,判断声明的真伪。4) 跨源分歧分析:分析LLM的置信度分数,量化和可视化不同来源之间的分歧。
关键创新:该论文的关键创新在于:1) 提出了一种新颖的检索策略,同时检索原始声明和否定形式的证据,从而捕获更全面的信息。2) 引入了跨源分歧分析,通过量化和可视化不同来源之间的分歧,增强了系统的可解释性。3) 将多源证据聚合与LLM相结合,提升了声明验证的准确性和可靠性。
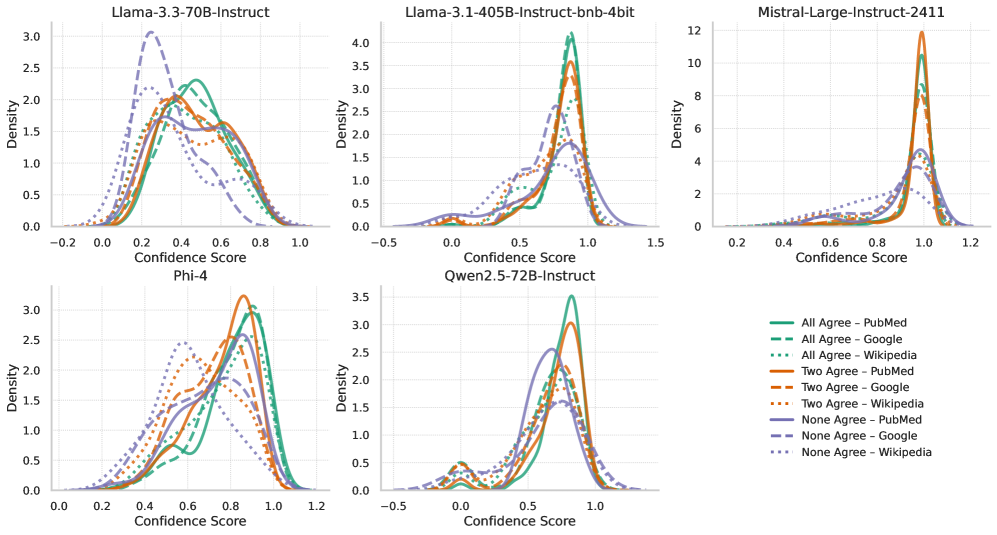
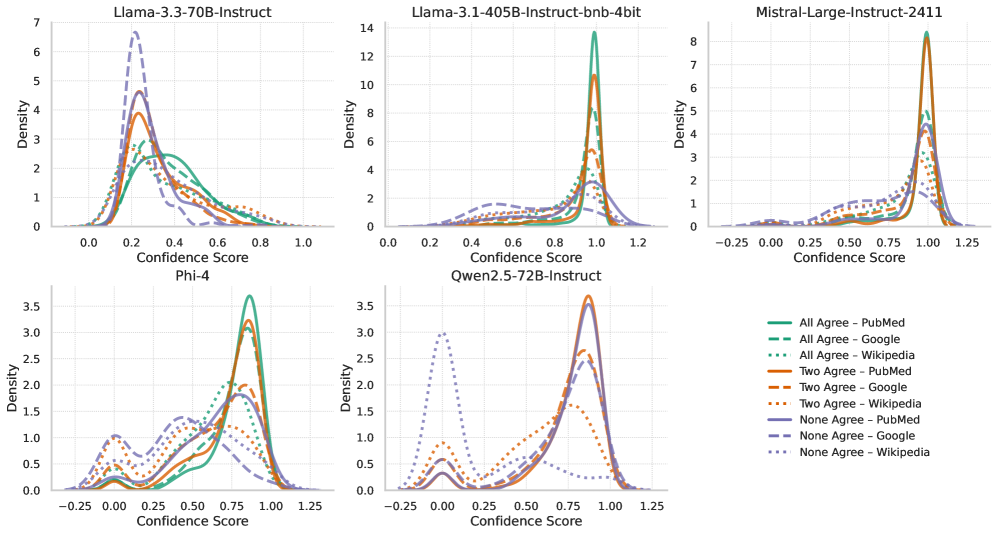
关键设计:论文中没有明确提及关键的参数设置、损失函数、网络结构等技术细节。证据过滤和聚合的具体算法未知。LLM的选择和微调策略未知。跨源分歧分析中,置信度分数的具体量化方法未知。
🖼️ 关键图片
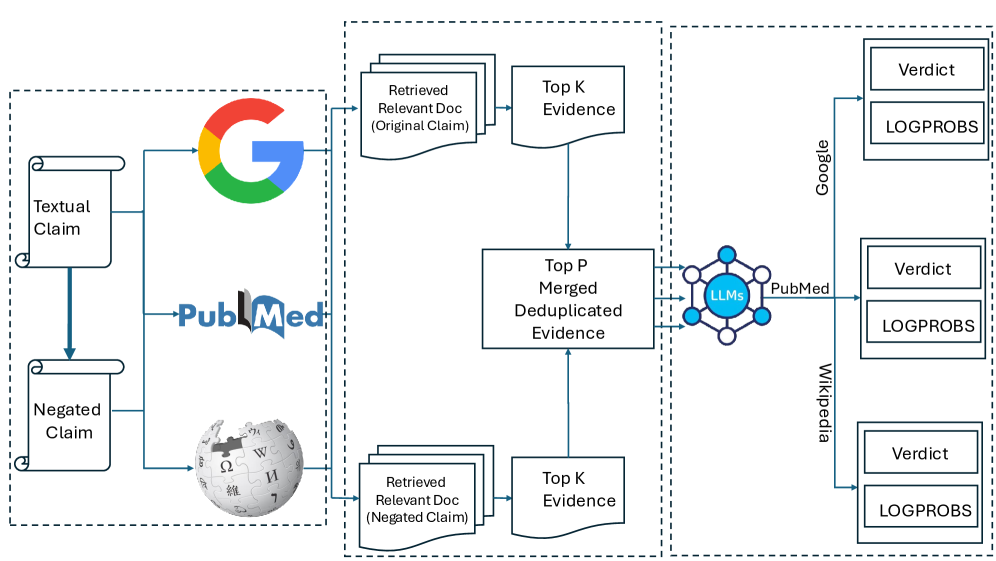
📊 实验亮点
论文在四个基准数据集上进行了广泛评估,结果表明,知识聚合能够有效改进声明验证,并揭示不同来源的推理差异。具体性能数据和提升幅度未知,但实验结果强调了在证据中拥抱多样性、矛盾和聚合对于构建可靠和透明的声明验证系统的重要性。
🎯 应用场景
该研究成果可应用于新闻媒体、社交平台等领域,用于自动识别和验证虚假信息,提高信息传播的可靠性。该系统能够帮助用户快速了解事件的真相,减少错误信息带来的负面影响,并为构建更健康的网络环境做出贡献。
📄 摘要(原文)
The spread of misinformation across digital platforms can pose significant societal risks. Claim verification, a.k.a. fact-checking, systems can help identify potential misinformation. However, their efficacy is limited by the knowledge sources that they rely on. Most automated claim verification systems depend on a single knowledge source and utilize the supporting evidence from that source; they ignore the disagreement of their source with others. This limits their knowledge coverage and transparency. To address these limitations, we present a novel system for open-domain claim verification (ODCV) that leverages large language models (LLMs), multi-perspective evidence retrieval, and cross-source disagreement analysis. Our approach introduces a novel retrieval strategy that collects evidence for both the original and the negated forms of a claim, enabling the system to capture supporting and contradicting information from diverse sources: Wikipedia, PubMed, and Google. These evidence sets are filtered, deduplicated, and aggregated across sources to form a unified and enriched knowledge base that better reflects the complexity of real-world information. This aggregated evidence is then used for claim verification using LLMs. We further enhance interpretability by analyzing model confidence scores to quantify and visualize inter-source disagreement. Through extensive evaluation on four benchmark datasets with five LLMs, we show that knowledge aggregation not only improves claim verification but also reveals differences in source-specific reasoning. Our findings underscore the importance of embracing diversity, contradiction, and aggregation in evidence for building reliable and transparent claim verification systems