DP-RFT: Learning to Generate Synthetic Text via Differentially Private Reinforcement Fine-Tuning
作者: Fangyuan Xu, Sihao Chen, Zinan Lin, Taiwei Shi, Sydney Graham, Pei Zhou, Mengting Wan, Alex Stein, Virginia Estellers, Charles Chen, Morris Sharp, Richard Speyer, Tadas Baltrusaitis, Jennifer Neville, Eunsol Choi, Longqi Yang
分类: cs.CL
发布日期: 2026-02-20
💡 一句话要点
提出DP-RFT,通过差分隐私强化微调生成高质量合成文本数据
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 强化学习 合成数据生成 大型语言模型 近端策略优化
📋 核心要点
- 现有DP微调方法虽有隐私保证,但需访问原始私有数据;而直接使用预训练模型生成数据,质量难以保证。
- DP-RFT利用差分隐私保护的最近邻投票作为奖励信号,通过强化学习微调LLM,无需直接访问私有数据。
- 实验表明,DP-RFT在新闻、会议记录和医学摘要等任务上,缩小了私有进化和DP微调方法之间的差距。
📝 摘要(中文)
差分隐私(DP)合成数据生成在私有数据上开发大型语言模型(LLM)方面起着关键作用,因为数据所有者无法提供对单个示例的直接访问。生成DP合成数据通常涉及一个困难的权衡。一方面,DP微调方法训练LLM作为具有正式隐私保证的合成数据生成器,但它仍然需要私有示例的原始内容用于模型训练。另一方面,避免直接暴露于私有数据的方法受到现成的、未微调模型的限制,其输出通常缺乏领域保真度。我们能否训练LLM生成高质量的合成文本,而无需直接访问单个私有示例?在本文中,我们介绍了一种用于LLM合成数据生成的差分隐私强化微调(DP-RFT)在线强化学习算法。DP-RFT利用来自非直接访问的私有语料库的DP保护的最近邻投票作为LLM生成的策略样本的奖励信号。LLM通过近端策略优化(PPO)迭代学习生成合成数据,以最大化预期的DP投票。我们评估了DP-RFT在长文本和特定领域合成数据生成方面的性能,例如新闻文章、会议记录和医学文章摘要。实验表明,DP-RFT在生成的合成数据的保真度和下游效用方面缩小了私有进化和DP微调方法之间的差距,同时尊重私有数据边界。
🔬 方法详解
问题定义:论文旨在解决在保护数据隐私的前提下,如何利用大型语言模型(LLM)生成高质量合成文本数据的问题。现有方法要么需要直接访问私有数据进行差分隐私微调,要么依赖未经微调的LLM,导致生成的数据质量不高,缺乏领域保真度。
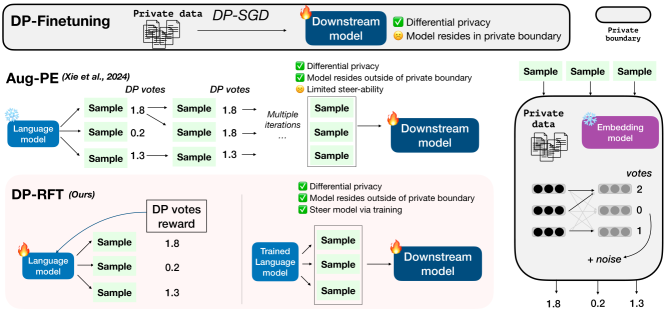
核心思路:论文的核心思路是利用差分隐私保护的最近邻投票作为奖励信号,通过强化学习的方式微调LLM。这样,LLM可以在不直接接触私有数据的情况下,学习生成与私有数据分布相似的合成数据。这种方法避免了直接暴露私有数据的风险,同时提升了生成数据的质量。
技术框架:DP-RFT的整体框架是一个在线强化学习过程。首先,LLM生成合成文本样本。然后,从私有语料库中进行差分隐私保护的最近邻搜索,得到一个投票结果作为奖励信号。LLM利用这个奖励信号,通过近端策略优化(PPO)算法更新模型参数,从而迭代地学习生成更好的合成数据。
关键创新:该方法最重要的创新点在于将差分隐私保护的最近邻投票与强化学习相结合,实现了一种在不直接访问私有数据的情况下,微调LLM生成高质量合成数据的方法。与现有方法相比,DP-RFT避免了直接暴露私有数据,同时提升了生成数据的质量和领域保真度。
关键设计:DP-RFT的关键设计包括:1)使用差分隐私机制保护最近邻搜索过程,确保隐私性;2)使用PPO算法进行强化学习,稳定训练过程;3)精心设计奖励函数,使得LLM能够学习生成与私有数据分布相似的文本。
🖼️ 关键图片
📊 实验亮点
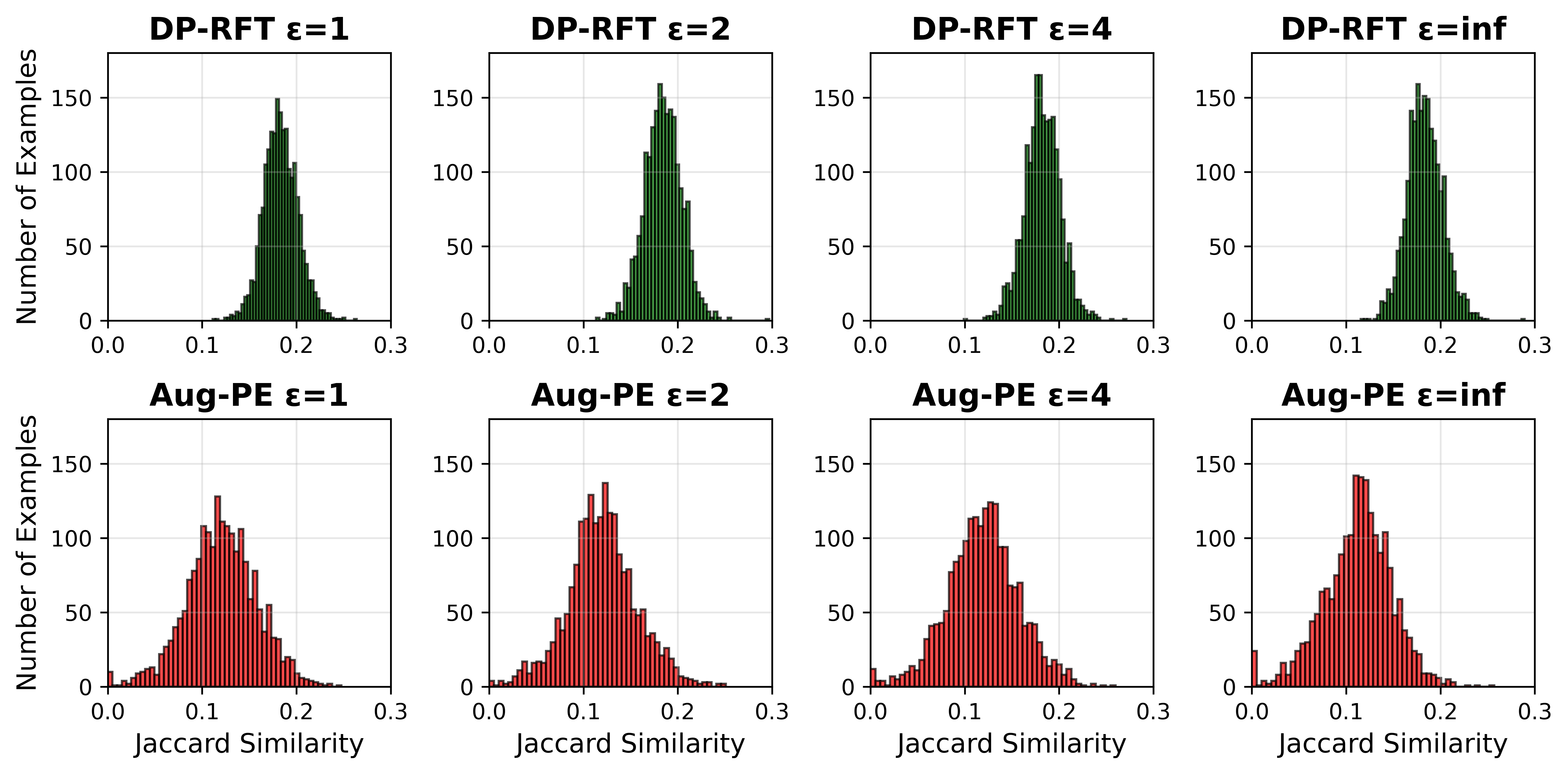
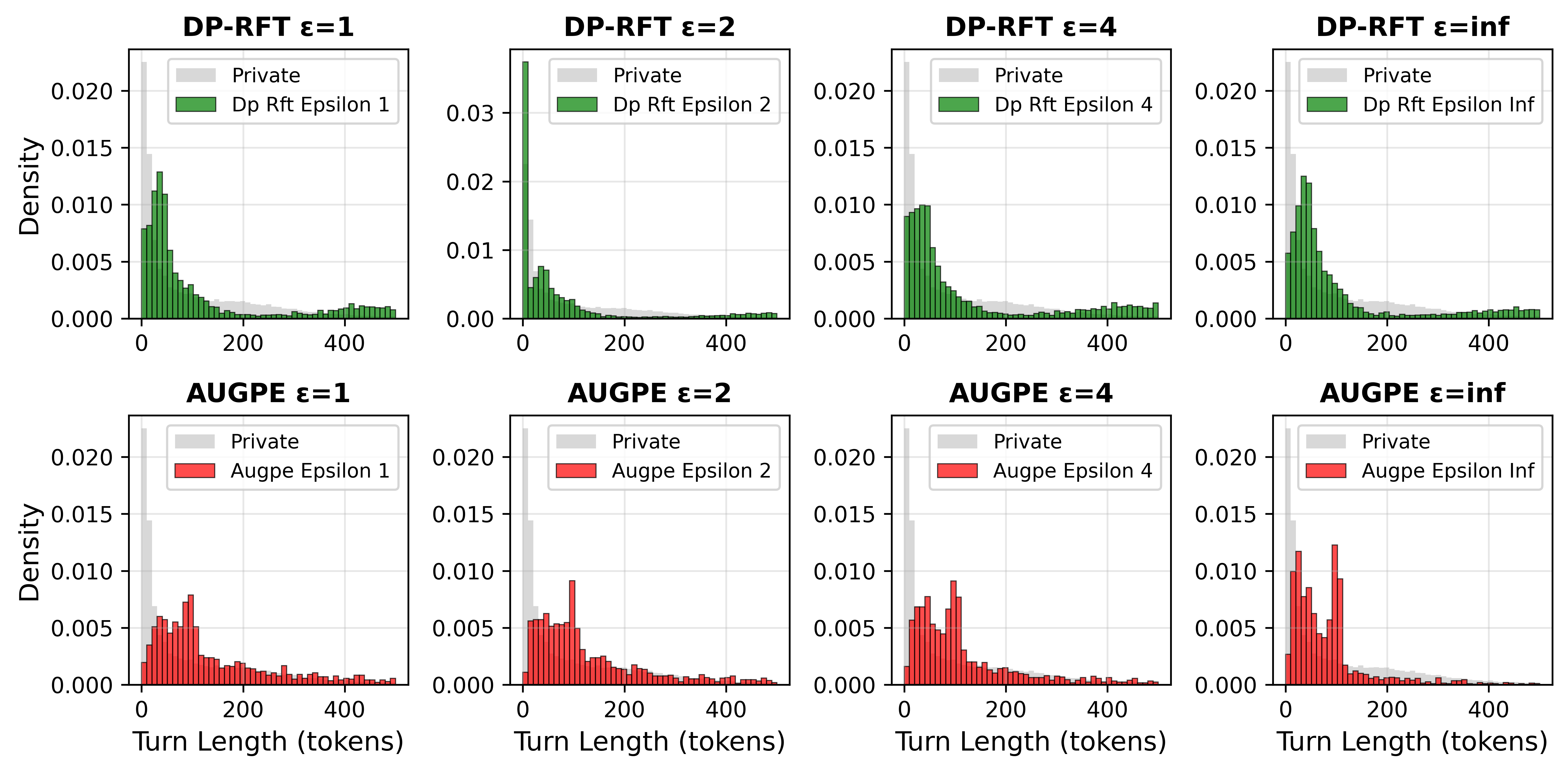
实验结果表明,DP-RFT在生成新闻文章、会议记录和医学文章摘要等任务上表现出色。与仅使用预训练模型相比,DP-RFT显著提高了生成数据的质量和下游任务的性能。在某些任务上,DP-RFT甚至可以达到与使用差分隐私微调方法相近的性能,同时避免了直接访问私有数据。
🎯 应用场景
DP-RFT可应用于医疗、金融等敏感数据领域,在保护用户隐私的前提下,生成用于模型训练的合成数据,促进相关领域AI技术的发展。例如,可以生成医疗记录摘要,用于训练疾病诊断模型,或生成金融交易数据,用于训练反欺诈模型。该技术有助于打破数据孤岛,释放数据价值。
📄 摘要(原文)
Differentially private (DP) synthetic data generation plays a pivotal role in developing large language models (LLMs) on private data, where data owners cannot provide eyes-on access to individual examples. Generating DP synthetic data typically involves a difficult trade-off. On one hand, DP finetuning methods train an LLM as a synthetic data generator with formal privacy guarantees, yet it still requires the raw content of private examples for model training. However, methods that avoid direct exposure to private data are bounded by an off-the-shelf, un-finetuned model, whose outputs often lack domain fidelity. Can we train an LLM to generate high-quality synthetic text without eyes-on access to individual private examples? In this work, we introduce Differentially Private Reinforcement Fine-Tuning (DP-RFT), an online reinforcement learning algorithm for synthetic data generation with LLMs. DP-RFT leverages DP-protected nearest-neighbor votes from an eyes-off private corpus as a reward signal for on-policy synthetic samples generated by an LLM. The LLM iteratively learns to generate synthetic data to maximize the expected DP votes through Proximal Policy Optimization (PPO). We evaluate DP-RFT for long-form and domain-specific synthetic data generation, such as news articles, meeting transcripts, and medical article abstracts. Our experiments show that DP-RFT closes the gap between private evolution and DP finetuning methods in terms of the fidelity and downstream utility of the generated synthetic data, while respecting the private data boundary.