Vichara: Appellate Judgment Prediction and Explanation for the Indian Judicial System
作者: Pavithra PM Nair, Preethu Rose Anish
分类: cs.CL, cs.AI
发布日期: 2026-02-20
期刊: AI and Law @ AAAI 2026
💡 一句话要点
Vichara:针对印度司法系统的上诉判决预测与解释框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 判决预测 法律人工智能 印度司法系统 决策点 可解释性
📋 核心要点
- 印度法院案件积压严重,现有方法难以有效预测上诉判决,缺乏可解释性。
- Vichara框架将上诉案件分解为决策点,提取法律问题、裁决等信息,实现精准预测。
- 实验表明,Vichara在判决预测任务上超越现有基准,GPT-4o mini模型表现最佳。
📝 摘要(中文)
在印度等法院面临大量案件积压的司法管辖区,人工智能为法律判决预测提供了变革潜力。上诉案件是积压案件中的一个关键子集,它是指上级法院对下级法院裁决进行审查后发布的正式判决。为此,我们提出了Vichara,这是一个为印度司法系统量身定制的新型框架,用于预测和解释上诉判决。Vichara处理英文上诉案件程序文件,并将其分解为决策点。决策点是离散的法律判定,它封装了法律问题、裁决机构、结果、推理和时间背景。这种结构化表示隔离了核心判定及其背景,从而能够进行准确的预测和可解释的解释。Vichara的解释遵循IRAC(问题-规则-应用-结论)框架,并针对印度法律推理进行了调整,从而增强了解释性,使法律专业人士能够有效地评估预测的合理性。我们使用GPT-4o mini、Llama-3.1-8B、Mistral-7B和Qwen2.5-7B这四种大型语言模型,在PredEx和印度法律文件语料库(ILDC_expert)的专家注释子集这两个数据集上评估了Vichara。Vichara在两个数据集上均超过了现有的判决预测基准,其中GPT-4o mini取得了最高的性能(在PredEx上F1值为81.5,在ILDC_expert上为80.3),其次是Llama-3.1-8B。对生成的解释在清晰度、关联性和有用性指标方面进行的人工评估突出了GPT-4o mini的卓越可解释性。
🔬 方法详解
问题定义:论文旨在解决印度司法系统中上诉判决预测的问题。现有方法在处理大量法律文本时效率低下,并且缺乏对判决结果的有效解释,导致法律专业人士难以信任和使用这些预测结果。因此,如何提高判决预测的准确性和可解释性是本研究要解决的核心问题。
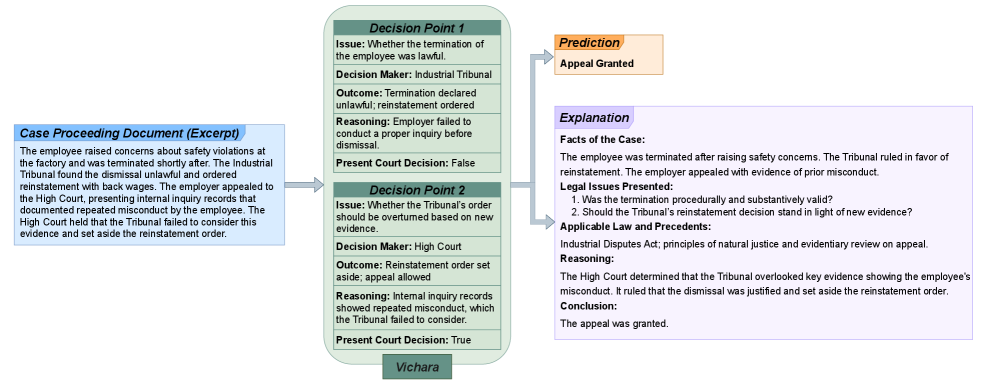
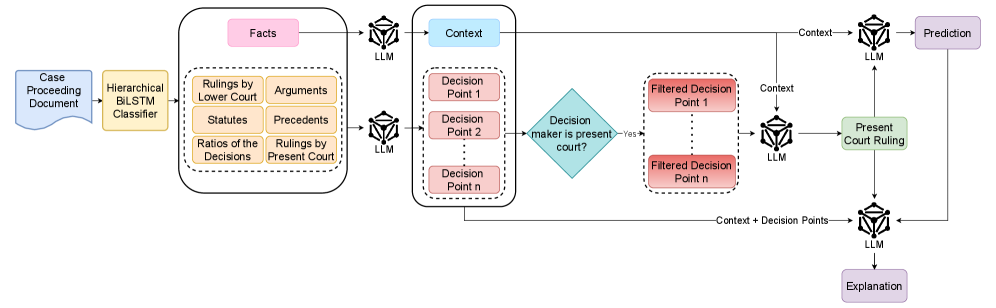
核心思路:论文的核心思路是将复杂的上诉案件分解为一系列独立的“决策点”,每个决策点代表一个具体的法律判定,包含法律问题、裁决机构、结果、推理和时间背景等关键信息。通过结构化地表示这些决策点,可以有效地提取案件的核心要素,从而提高预测的准确性和可解释性。
技术框架:Vichara框架主要包含以下几个阶段:1) 上诉案件文本预处理:对输入的英文上诉案件文档进行清洗和格式化。2) 决策点提取:将案件文本分解为一系列决策点,并提取每个决策点的关键信息。3) 判决预测:利用大型语言模型(如GPT-4o mini、Llama-3.1-8B等)对提取的决策点信息进行分析,预测上诉判决的结果。4) 判决解释生成:基于IRAC框架,生成对预测结果的结构化解释,帮助法律专业人士理解判决的逻辑和依据。
关键创新:Vichara的关键创新在于其“决策点”的概念和结构化表示方法。与传统的直接对整个案件文本进行预测的方法不同,Vichara通过将案件分解为更小的、更易于理解的决策点,从而提高了预测的准确性和可解释性。此外,Vichara还针对印度法律推理的特点,对IRAC框架进行了调整,使其更适合于解释印度法律判决。
关键设计:论文中没有详细描述关键的参数设置、损失函数、网络结构等技术细节。但可以推测,在判决预测阶段,可能使用了交叉熵损失函数来训练大型语言模型,并根据验证集上的性能来调整模型的超参数。此外,在决策点提取阶段,可能使用了基于规则或机器学习的方法来识别和提取关键信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Vichara框架在PredEx和ILDC_expert两个数据集上均超越了现有的判决预测基准。其中,GPT-4o mini模型取得了最佳性能,在PredEx数据集上F1值为81.5,在ILDC_expert数据集上F1值为80.3。人工评估结果也表明,GPT-4o mini生成的解释在清晰度、关联性和有用性方面表现出色。
🎯 应用场景
Vichara框架可应用于印度司法系统,辅助法官和律师快速了解案件要点,预测判决结果,提高案件处理效率。该研究还可推广到其他司法管辖区,为法律人工智能领域的发展提供借鉴。未来,Vichara有望成为法律专业人士的得力助手,促进司法公正和效率。
📄 摘要(原文)
In jurisdictions like India, where courts face an extensive backlog of cases, artificial intelligence offers transformative potential for legal judgment prediction. A critical subset of this backlog comprises appellate cases, which are formal decisions issued by higher courts reviewing the rulings of lower courts. To this end, we present Vichara, a novel framework tailored to the Indian judicial system that predicts and explains appellate judgments. Vichara processes English-language appellate case proceeding documents and decomposes them into decision points. Decision points are discrete legal determinations that encapsulate the legal issue, deciding authority, outcome, reasoning, and temporal context. The structured representation isolates the core determinations and their context, enabling accurate predictions and interpretable explanations. Vichara's explanations follow a structured format inspired by the IRAC (Issue-Rule-Application-Conclusion) framework and adapted for Indian legal reasoning. This enhances interpretability, allowing legal professionals to assess the soundness of predictions efficiently. We evaluate Vichara on two datasets, PredEx and the expert-annotated subset of the Indian Legal Documents Corpus (ILDC_expert), using four large language models: GPT-4o mini, Llama-3.1-8B, Mistral-7B, and Qwen2.5-7B. Vichara surpasses existing judgment prediction benchmarks on both datasets, with GPT-4o mini achieving the highest performance (F1: 81.5 on PredEx, 80.3 on ILDC_expert), followed by Llama-3.1-8B. Human evaluation of the generated explanations across Clarity, Linking, and Usefulness metrics highlights GPT-4o mini's superior interpretability.