VeriSoftBench: Repository-Scale Formal Verification Benchmarks for Lean
作者: Yutong Xin, Qiaochu Chen, Greg Durrett, Işil Dillig
分类: cs.SE, cs.CL, cs.LG, cs.PL
发布日期: 2026-02-20
🔗 代码/项目: GITHUB
💡 一句话要点
VeriSoftBench:面向Lean的形式化验证,仓库级规模的基准测试集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 形式化验证 Lean 大型语言模型 基准测试 软件验证
📋 核心要点
- 现有LLM定理证明基准主要集中在Mathlib数学库,缺乏对软件验证中复杂代码库的针对性评估。
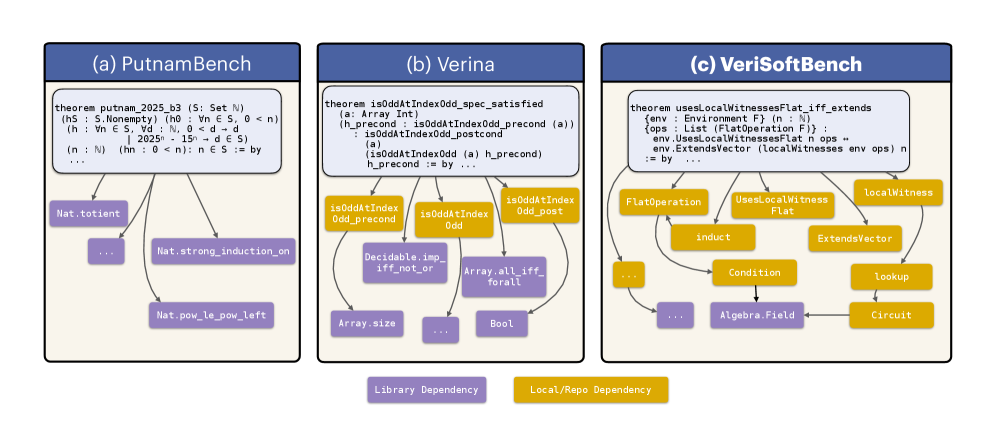
- VeriSoftBench通过收集开源形式化方法项目中的500个Lean 4证明义务,构建了仓库级规模的基准测试集。
- 实验表明,针对Mathlib优化的证明器在VeriSoftBench上表现不佳,证明难度与仓库依赖深度显著相关。
📝 摘要(中文)
大型语言模型在交互式定理证明方面取得了显著成果,尤其是在Lean中。然而,大多数基于LLM的证明自动化基准测试都来自Mathlib生态系统中的数学领域,而软件验证中的证明是在定义丰富的代码库中开发的,这些代码库具有大量的项目特定库。我们引入了VeriSoftBench,这是一个包含500个Lean 4证明义务的基准测试集,这些证明义务来自开源形式化方法开发,并被打包以保留真实的仓库上下文和跨文件依赖关系。我们对前沿LLM和专用证明器的评估产生了三个观察结果。首先,为Mathlib风格的数学调整的证明器在这种以仓库为中心的设置中表现不佳。其次,成功与传递仓库依赖性密切相关:其证明依赖于大型多跳依赖闭包的任务不太可能被解决。第三,提供限制于证明依赖闭包的精选上下文可以提高相对于暴露整个仓库的性能,但仍然留有很大的改进空间。我们的基准测试和评估套件已在https://github.com/utopia-group/VeriSoftBench上发布。
🔬 方法详解
问题定义:现有基于LLM的定理证明benchmark,例如Mathlib,主要关注数学领域的证明,缺乏对软件验证场景的针对性。软件验证通常涉及复杂的代码库和项目特定的依赖关系,这与Mathlib的数学证明环境有很大不同。因此,需要一个新的benchmark来评估LLM在软件验证中的能力。
核心思路:VeriSoftBench的核心思路是构建一个更贴近实际软件验证场景的benchmark。通过收集开源形式化方法项目中的证明义务,并保留其仓库上下文和跨文件依赖关系,VeriSoftBench能够更真实地反映软件验证的复杂性。
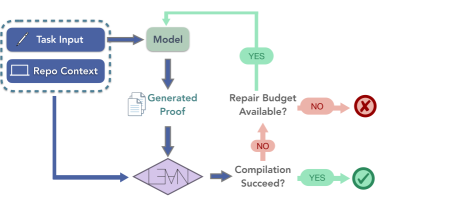
技术框架:VeriSoftBench包含500个Lean 4证明义务,这些义务来自开源形式化方法项目。该benchmark的关键在于保留了每个证明义务的仓库上下文和跨文件依赖关系。评估过程包括使用不同的LLM和专用证明器来尝试解决这些证明义务,并分析其性能。研究人员还探索了通过提供精选上下文(仅限于证明的依赖闭包)来提高性能的方法。
关键创新:VeriSoftBench的主要创新在于其仓库级规模和对真实软件验证场景的模拟。与现有的benchmark相比,VeriSoftBench更能够反映软件验证的复杂性,并为LLM在软件验证中的应用提供更可靠的评估。此外,对依赖关系深度的分析也为理解LLM在处理复杂依赖关系时的局限性提供了新的视角。
关键设计:VeriSoftBench的关键设计包括:1) 从开源形式化方法项目中选择证明义务;2) 保留每个证明义务的仓库上下文和跨文件依赖关系;3) 提供评估工具和脚本,方便研究人员使用该benchmark;4) 分析证明成功率与仓库依赖深度之间的关系;5) 探索通过提供精选上下文来提高性能的方法。具体参数设置和损失函数等细节取决于所使用的LLM和证明器。
🖼️ 关键图片

📊 实验亮点
实验结果表明,针对Mathlib优化的证明器在VeriSoftBench上的表现明显不如预期,这表明现有方法在软件验证领域的泛化能力有限。此外,证明的成功率与仓库依赖深度呈现负相关,表明LLM在处理复杂依赖关系时面临挑战。提供精选上下文可以提高性能,但仍有很大的提升空间。
🎯 应用场景
VeriSoftBench可用于评估和改进LLM在软件形式化验证领域的应用。通过该基准测试,可以更好地了解LLM在处理复杂代码库和依赖关系时的能力,并开发更有效的自动化证明工具,从而提高软件的可靠性和安全性。该研究对形式化验证工具的智能化发展具有重要意义。
📄 摘要(原文)
Large language models have achieved striking results in interactive theorem proving, particularly in Lean. However, most benchmarks for LLM-based proof automation are drawn from mathematics in the Mathlib ecosystem, whereas proofs in software verification are developed inside definition-rich codebases with substantial project-specific libraries. We introduce VeriSoftBench, a benchmark of 500 Lean 4 proof obligations drawn from open-source formal-methods developments and packaged to preserve realistic repository context and cross-file dependencies. Our evaluation of frontier LLMs and specialized provers yields three observations. First, provers tuned for Mathlib-style mathematics transfer poorly to this repository-centric setting. Second, success is strongly correlated with transitive repository dependence: tasks whose proofs draw on large, multi-hop dependency closures are less likely to be solved. Third, providing curated context restricted to a proof's dependency closure improves performance relative to exposing the full repository, but nevertheless leaves substantial room for improvement. Our benchmark and evaluation suite are released at https://github.com/utopia-group/VeriSoftBench.