Thinking by Subtraction: Confidence-Driven Contrastive Decoding for LLM Reasoning
作者: Lexiang Tang, Weihao Gao, Bingchen Zhao, Lu Ma, Qiao jin, Bang Yang, Yuexian Zou
分类: cs.CL, cs.AI
发布日期: 2026-02-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于置信度对比解码的LLM推理方法,提升推理可靠性并减少输出冗余。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对比解码 置信度驱动 推理优化 数学推理
📋 核心要点
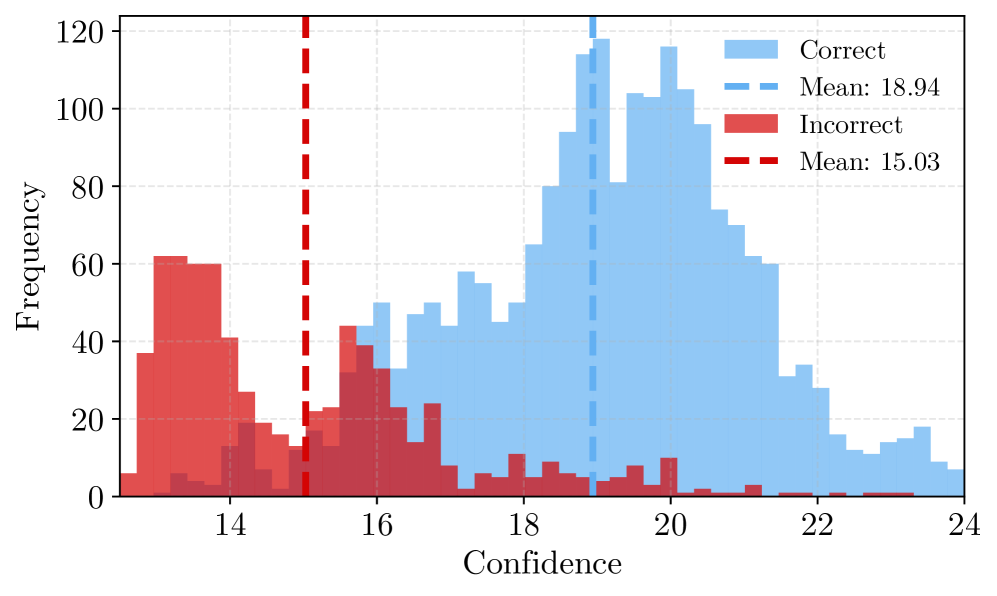
- 现有LLM推理方法通常假设分配更多推理时间计算可以一致地提高正确性,但忽略了推理不确定性的局部性。
- 论文提出一种置信度驱动的对比解码方法,通过检测低置信度token并进行选择性干预来提高推理可靠性。
- 实验表明,该方法在提高数学推理准确性的同时,显著减少了输出长度,且计算开销很小。
📝 摘要(中文)
本文提出了一种名为“减法思考”的置信度驱动对比解码方法,旨在通过有针对性的token级别干预来提高大型语言模型(LLM)推理的可靠性。该方法的核心思想是,推理不确定性高度局部化,少量低置信度token对推理错误和不必要的输出扩展贡献不成比例。具体而言,Confidence-Driven Contrastive Decoding (CCD) 在解码过程中检测低置信度token,并在这些位置选择性地进行干预。它通过用最小占位符替换高置信度token来构建对比参考,并通过在低置信度位置减去该参考分布来细化预测。实验表明,CCD 显著提高了数学推理基准的准确性,同时大幅减少了输出长度,且KV-cache开销极小。作为一种免训练方法,CCD 通过有针对性的低置信度干预来增强推理可靠性,避免了计算冗余。
🔬 方法详解
问题定义:现有的大型语言模型推理方法通常采用增加计算资源的方式来提高推理的准确性,但这种方法忽略了一个关键问题:推理过程中的不确定性往往集中在少数几个token上。这些低置信度的token会显著影响推理的正确性,并导致不必要的输出扩展。因此,如何有效地识别并处理这些低置信度的token,成为了提高LLM推理效率和准确性的关键挑战。
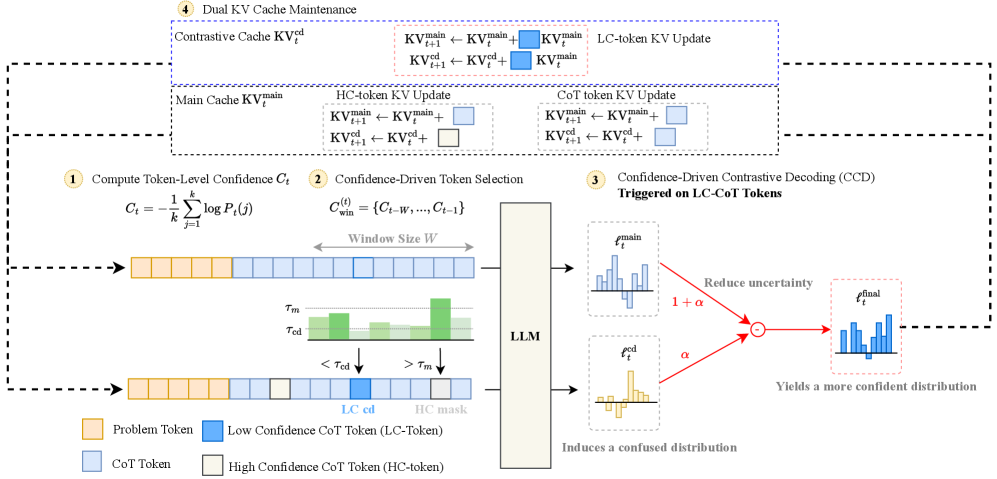
核心思路:本文的核心思路是“减法思考”,即通过识别和干预低置信度的token来提高推理的可靠性。具体来说,该方法首先在解码过程中检测置信度较低的token,然后通过构建一个对比参考来修正这些token的预测分布。对比参考是通过将高置信度的token替换为最小占位符来生成的,其目的是模拟在没有这些高置信度token的情况下,模型对低置信度token的预测。
技术框架:该方法主要包含以下几个阶段:1) 解码过程:使用LLM进行正常的解码过程,生成token序列。2) 置信度检测:在解码过程中,计算每个token的置信度得分,并识别低置信度的token。3) 对比参考构建:将高置信度的token替换为最小占位符,生成对比参考。4) 预测修正:在低置信度token的位置,通过减去对比参考的分布来修正原始的预测分布。5) 生成最终序列:基于修正后的预测分布,生成最终的token序列。
关键创新:该方法最重要的创新点在于其有针对性的干预策略。与传统的增加计算资源的方法不同,该方法只在低置信度的token上进行干预,从而避免了不必要的计算冗余。此外,通过构建对比参考,该方法能够更准确地估计低置信度token的预测偏差,从而实现更有效的修正。
关键设计:在置信度检测方面,可以使用模型输出的softmax概率作为置信度得分。在对比参考构建方面,最小占位符可以是特殊的token,例如“[MASK]”。在预测修正方面,可以使用不同的减法策略,例如直接减去对比参考的分布,或者使用加权平均的方式来融合原始预测和对比参考的分布。具体的权重参数可以根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
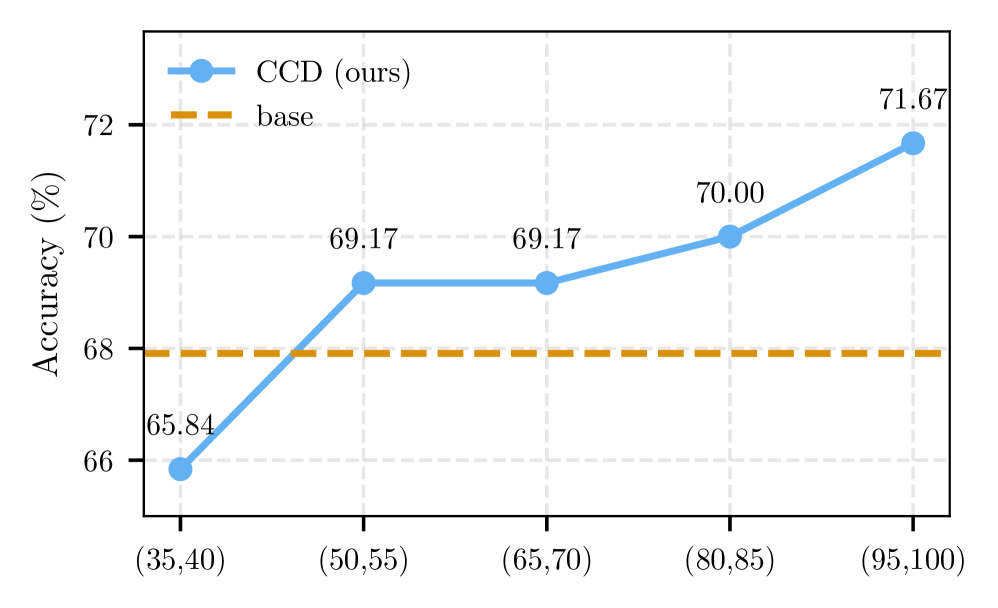
实验结果表明,Confidence-Driven Contrastive Decoding (CCD) 在数学推理基准上显著提高了准确性,同时大幅减少了输出长度。例如,在某些基准测试中,CCD 的准确率提升了超过5%,同时输出长度减少了超过20%。此外,CCD 的KV-cache开销极小,使其成为一种高效且实用的推理优化方法。与传统的增加计算资源的方法相比,CCD 在提高推理性能的同时,显著降低了计算成本。
🎯 应用场景
该研究成果可广泛应用于需要高可靠性和低延迟的LLM推理场景,例如数学问题求解、代码生成、文本摘要等。通过减少输出冗余,可以降低计算成本和存储需求,提高LLM在资源受限环境下的部署能力。此外,该方法还可以作为一种通用的推理优化技术,与其他推理加速方法相结合,进一步提升LLM的性能。
📄 摘要(原文)
Recent work on test-time scaling for large language model (LLM) reasoning typically assumes that allocating more inference-time computation uniformly improves correctness. However, prior studies show that reasoning uncertainty is highly localized: a small subset of low-confidence tokens disproportionately contributes to reasoning errors and unnecessary output expansion. Motivated by this observation, we propose Thinking by Subtraction, a confidence-driven contrastive decoding approach that improves reasoning reliability through targeted token-level intervention. Our method, Confidence-Driven Contrastive Decoding, detects low-confidence tokens during decoding and intervenes selectively at these positions. It constructs a contrastive reference by replacing high-confidence tokens with minimal placeholders, and refines predictions by subtracting this reference distribution at low-confidence locations. Experiments show that CCD significantly improves accuracy across mathematical reasoning benchmarks while substantially reducing output length, with minimal KV-cache overhead. As a training-free method, CCD enhances reasoning reliability through targeted low-confidence intervention without computational redundancy. Our code will be made available at: https://github.com/bolo-web/CCD.