Click it or Leave it: Detecting and Spoiling Clickbait with Informativeness Measures and Large Language Models
作者: Wojciech Michaluk, Tymoteusz Urban, Mateusz Kubita, Soveatin Kuntur, Anna Wroblewska
分类: cs.CL, cs.AI
发布日期: 2026-02-20
💡 一句话要点
提出一种融合信息量化特征与大语言模型的混合方法,用于检测并消除网络点击诱饵。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 点击诱饵检测 自然语言处理 Transformer模型 语言学特征 XGBoost 文本分类 信息量化
📋 核心要点
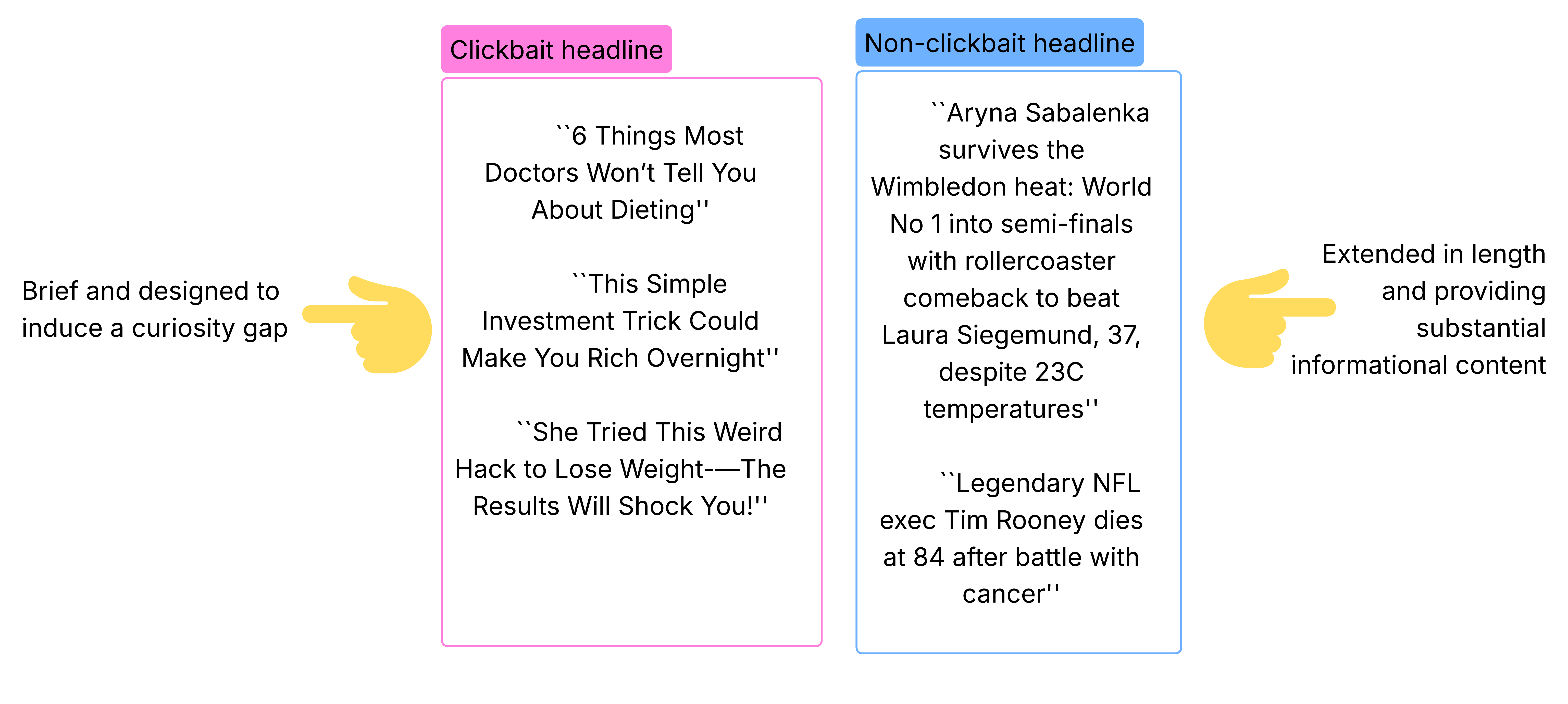
- 现有点击诱饵检测方法缺乏对语言学特征的深入挖掘,可解释性较差,难以有效识别。
- 结合Transformer嵌入和语言学信息量化特征,利用XGBoost进行分类,提升检测性能和可解释性。
- 实验表明,该方法F1值达到91%,优于传统方法和仅使用LLM的方法,并开源代码和模型。
📝 摘要(中文)
点击诱饵标题降低了在线信息的质量,并损害了用户信任。本文提出了一种混合方法来检测点击诱饵,该方法结合了基于Transformer的文本嵌入和语言学驱动的信息量化特征。利用自然语言处理技术,我们评估了经典向量化器、词嵌入基线以及与基于树的分类器配对的大型语言模型嵌入。我们表现最佳的模型,即XGBoost在增强了15个显式特征的嵌入上,实现了91%的F1分数,优于TF-IDF、Word2Vec、GloVe、基于LLM提示的分类以及仅使用特征的基线。所提出的特征集通过突出诸如第二人称代词、最高级、数字和以注意力为导向的标点符号等显著的语言线索来增强可解释性,从而实现透明且良好校准的点击诱饵预测。我们发布了代码和训练好的模型,以支持可重复的研究。
🔬 方法详解
问题定义:论文旨在解决网络上点击诱饵标题泛滥的问题。现有方法通常依赖于简单的关键词匹配或浅层机器学习模型,缺乏对标题深层语义和语言学特征的理解,导致检测精度不高,且可解释性差。此外,现有方法难以有效区分正常标题和刻意制造悬念的点击诱饵。
核心思路:论文的核心思路是将深度学习模型(Transformer)提取的文本嵌入与精心设计的语言学特征相结合,利用机器学习模型进行分类。这种混合方法既能捕捉标题的语义信息,又能利用语言学特征提高检测精度和可解释性。通过信息量化特征,模型能够更好地理解标题的意图,从而更准确地识别点击诱饵。
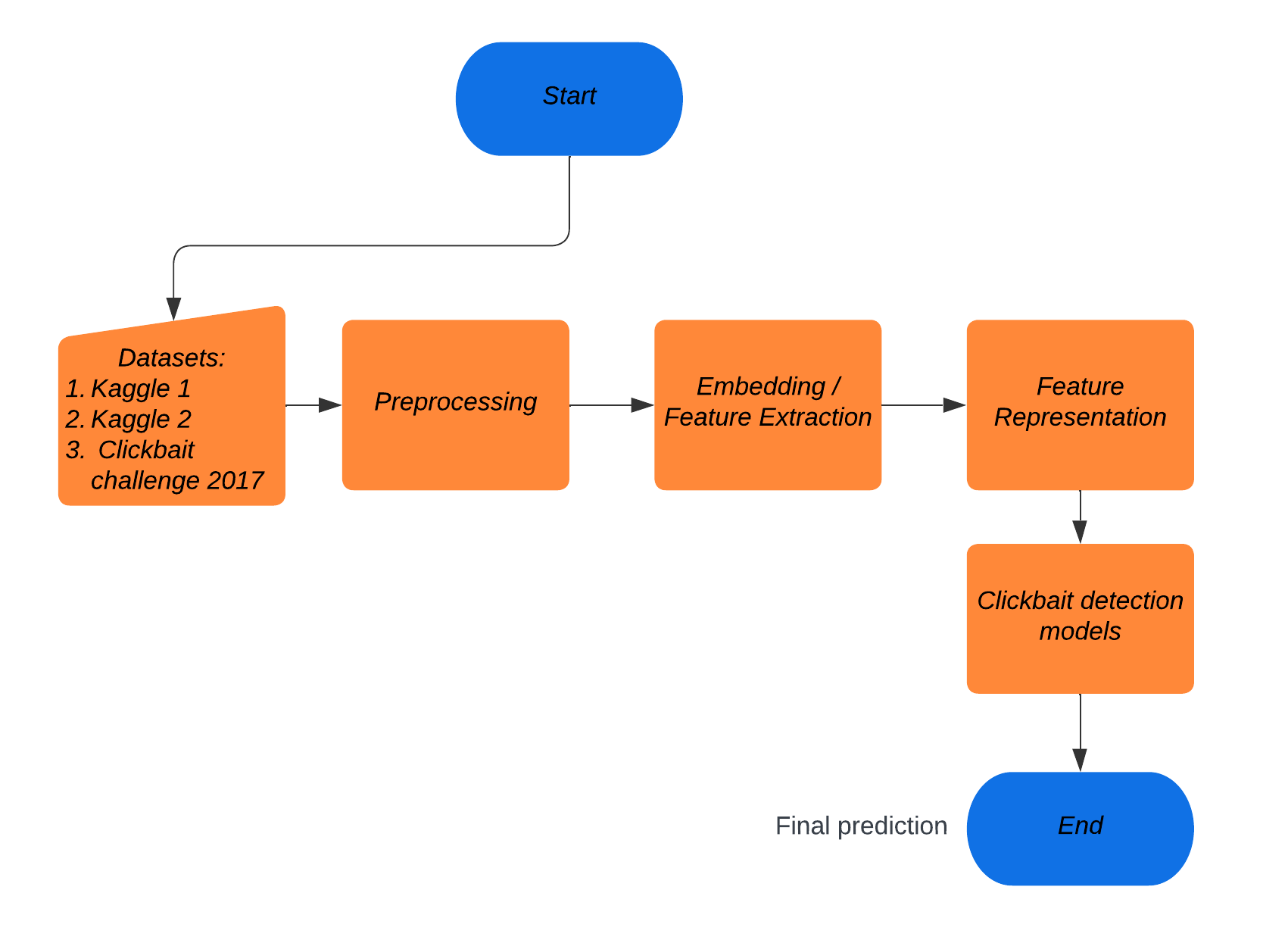
技术框架:该方法主要包含以下几个阶段:1) 数据预处理:对标题文本进行清洗和标准化。2) 特征提取:使用Transformer模型(如BERT)提取文本嵌入,并计算15个语言学特征,包括第二人称代词、最高级、数字和标点符号等。3) 模型训练:将文本嵌入和语言学特征输入到XGBoost分类器中进行训练。4) 模型评估:使用测试集评估模型的性能,并与其他基线方法进行比较。
关键创新:该方法最重要的创新点在于将深度学习模型与语言学特征相结合。传统方法通常只关注文本的表面特征,而该方法能够同时捕捉文本的语义信息和语言学特征,从而更准确地识别点击诱饵。此外,该方法提出的15个语言学特征具有很强的可解释性,能够帮助人们理解模型做出决策的原因。
关键设计:在特征提取阶段,论文使用了预训练的Transformer模型来提取文本嵌入。同时,论文精心设计了15个语言学特征,这些特征能够反映标题的语言风格和意图。在模型训练阶段,论文使用了XGBoost分类器,并对模型参数进行了优化。此外,论文还使用了交叉验证等技术来提高模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在点击诱饵检测任务上取得了显著的性能提升。基于XGBoost的模型,结合文本嵌入和15个语言学特征,F1分数达到了91%,超过了TF-IDF、Word2Vec、GloVe等传统方法,以及仅使用LLM提示的分类方法。这证明了结合深度学习和语言学特征的有效性。
🎯 应用场景
该研究成果可应用于在线新闻平台、社交媒体网站和搜索引擎等领域,用于自动检测和过滤点击诱饵标题,提高在线信息的质量和用户体验。通过减少用户接触低质量信息的机会,可以提升用户对平台的信任度,并促进更健康的网络生态。
📄 摘要(原文)
Clickbait headlines degrade the quality of online information and undermine user trust. We present a hybrid approach to clickbait detection that combines transformer-based text embeddings with linguistically motivated informativeness features. Using natural language processing techniques, we evaluate classical vectorizers, word embedding baselines, and large language model embeddings paired with tree-based classifiers. Our best-performing model, XGBoost over embeddings augmented with 15 explicit features, achieves an F1-score of 91\%, outperforming TF-IDF, Word2Vec, GloVe, LLM prompt based classification, and feature-only baselines. The proposed feature set enhances interpretability by highlighting salient linguistic cues such as second-person pronouns, superlatives, numerals, and attention-oriented punctuation, enabling transparent and well-calibrated clickbait predictions. We release code and trained models to support reproducible research.