The Statistical Signature of LLMs
作者: Ortal Hadad, Edoardo Loru, Jacopo Nudo, Niccolò Di Marco, Matteo Cinelli, Walter Quattrociocchi
分类: cs.CL, cs.CY, physics.soc-ph
发布日期: 2026-02-20
💡 一句话要点
利用无损压缩识别LLM文本的统计特征,揭示生成模型在不同信息生态中的结构规律。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 无损压缩 文本生成 统计规律性 信息生态系统
📋 核心要点
- 现有方法难以有效区分人类文本和LLM生成文本,尤其是在不依赖模型内部信息或语义评估的情况下。
- 论文提出利用无损压缩作为模型无关的统计规律性度量,通过分析文本的可压缩性来区分生成模式。
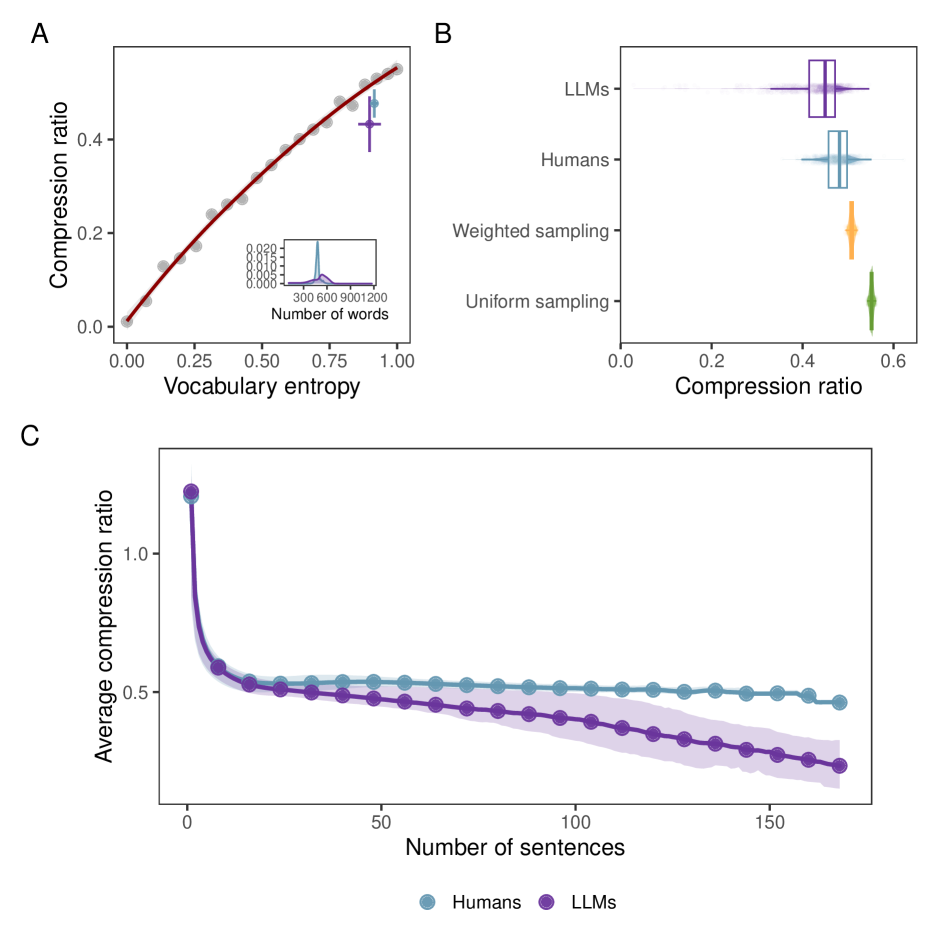
- 实验表明,LLM生成的文本通常比人类文本具有更高的可压缩性,但在分散的交互环境中这种差异会减弱。
📝 摘要(中文)
大型语言模型通过高维分布的概率采样生成文本,但这种过程如何重塑语言的结构统计组织仍然不完全清楚。本文表明,无损压缩提供了一种简单的、模型无关的统计规律性度量,可以直接从表面文本区分生成机制。我们分析了三种逐渐复杂的信息生态系统中的压缩行为:受控的人类-LLM延续、知识基础设施的生成调解(维基百科与Grokipedia)以及完全合成的社交互动环境(Moltbook与Reddit)。在各种设置中,压缩揭示了概率生成的一种持久结构特征。在受控和调解的上下文中,LLM生成的语言比人类编写的文本表现出更高的结构规律性和可压缩性,这与输出集中在高度重复的统计模式中一致。然而,这种特征表现出尺度依赖性:在分散的交互环境中,这种分离减弱,表明在小尺度上表面水平可区分性的根本限制。这种基于可压缩性的分离在模型、任务和领域中始终如一地出现,并且可以直接从表面文本观察到,而无需依赖模型内部或语义评估。总的来说,我们的发现引入了一个简单而稳健的框架,用于量化生成系统如何重塑文本生成,从而为通信不断演变的复杂性提供了一个结构性的视角。
🔬 方法详解
问题定义:论文旨在解决如何有效区分大型语言模型(LLM)生成的文本和人类编写的文本的问题。现有方法通常依赖于模型内部信息或复杂的语义分析,这限制了其通用性和可解释性。此外,在小规模或分散的交互环境中,区分LLM生成文本和人类文本变得更加困难。
核心思路:论文的核心思路是利用无损压缩算法来衡量文本的统计规律性。LLM通过概率采样生成文本,这可能导致其输出在统计模式上与人类文本存在差异。无损压缩算法能够有效地捕捉这些统计模式,从而提供一种模型无关的区分方法。可压缩性越高,表明文本的统计规律性越强,反之亦然。
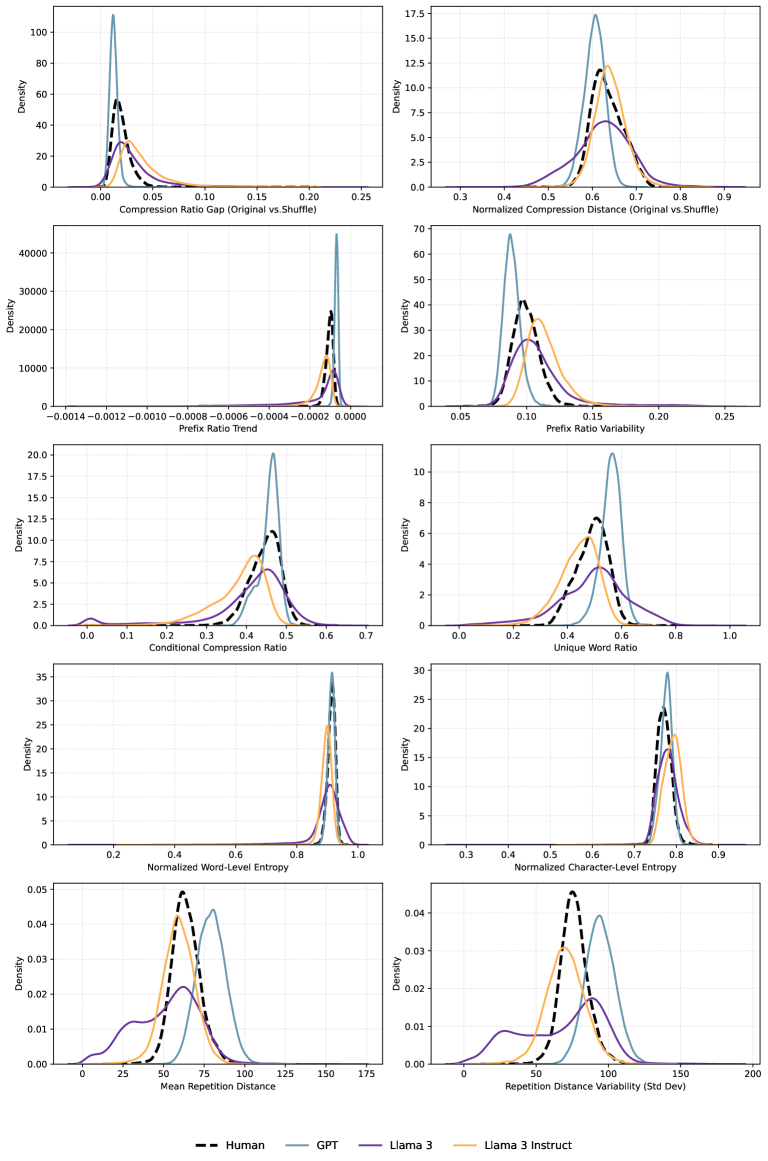
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择不同的信息生态系统,包括受控的人类-LLM延续、知识基础设施的生成调解和完全合成的社交互动环境。2) 在每个生态系统中收集人类编写的文本和LLM生成的文本。3) 使用无损压缩算法(如LZMA)对文本进行压缩,并计算压缩率。4) 分析不同文本类型的压缩率差异,并评估其区分LLM生成文本和人类文本的能力。
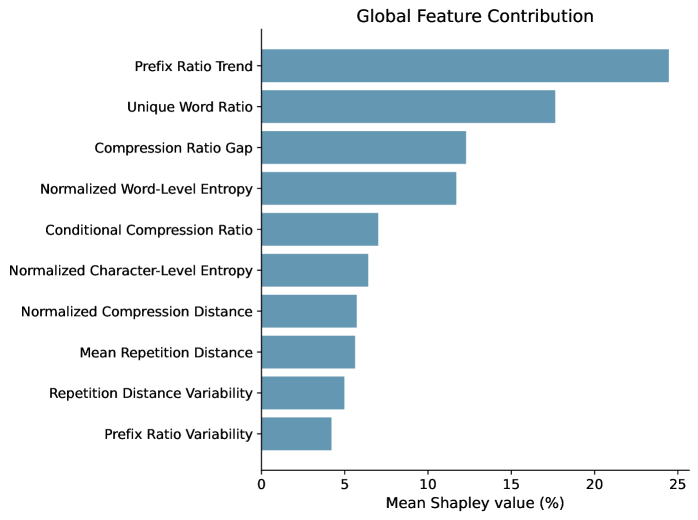
关键创新:论文的关键创新在于提出了一种基于无损压缩的、模型无关的文本区分方法。与依赖模型内部信息或语义分析的方法相比,该方法更加简单、通用和可解释。此外,论文还揭示了LLM生成文本的统计特征在不同信息生态系统中的尺度依赖性,这为理解LLM的生成机制提供了新的视角。
关键设计:论文使用了LZMA压缩算法,并采用压缩率作为衡量文本可压缩性的指标。实验中,作者精心设计了不同的信息生态系统,以模拟真实世界中的文本生成环境。此外,作者还对实验结果进行了统计分析,以验证其方法的有效性和鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在受控和调解的上下文中,LLM生成的文本比人类编写的文本具有更高的可压缩性。例如,在维基百科与Grokipedia的对比实验中,LLM生成的文本的压缩率明显高于人类编写的文本。然而,在Moltbook与Reddit等分散的交互环境中,这种差异减弱,表明在小尺度上表面水平可区分性的根本限制。
🎯 应用场景
该研究成果可应用于检测虚假信息、识别自动化内容生成、评估LLM的生成质量等方面。通过分析文本的可压缩性,可以帮助识别潜在的恶意内容,并提高信息安全水平。此外,该方法还可以用于评估不同LLM的生成能力,并指导模型优化。
📄 摘要(原文)
Large language models generate text through probabilistic sampling from high-dimensional distributions, yet how this process reshapes the structural statistical organization of language remains incompletely characterized. Here we show that lossless compression provides a simple, model-agnostic measure of statistical regularity that differentiates generative regimes directly from surface text. We analyze compression behavior across three progressively more complex information ecosystems: controlled human-LLM continuations, generative mediation of a knowledge infrastructure (Wikipedia vs. Grokipedia), and fully synthetic social interaction environments (Moltbook vs. Reddit). Across settings, compression reveals a persistent structural signature of probabilistic generation. In controlled and mediated contexts, LLM-produced language exhibits higher structural regularity and compressibility than human-written text, consistent with a concentration of output within highly recurrent statistical patterns. However, this signature shows scale dependence: in fragmented interaction environments the separation attenuates, suggesting a fundamental limit to surface-level distinguishability at small scales. This compressibility-based separation emerges consistently across models, tasks, and domains and can be observed directly from surface text without relying on model internals or semantic evaluation. Overall, our findings introduce a simple and robust framework for quantifying how generative systems reshape textual production, offering a structural perspective on the evolving complexity of communication.