Agentic Adversarial QA for Improving Domain-Specific LLMs
作者: Vincent Grari, Ciprian Tomoiaga, Sylvain Lamprier, Tatsunori Hashimoto, Marcin Detyniecki
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-20
备注: 9 pages, 1 Figure
💡 一句话要点
提出Agentic对抗问答框架,提升领域特定LLM的性能和样本效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 领域特定LLM 对抗性问答 数据增强 合成数据生成 样本效率 LegalBench 微调
📋 核心要点
- 现有方法在领域特定LLM微调中,生成的合成数据缺乏解释性推理能力,且冗余度高,导致样本效率低。
- 提出一种对抗性问题生成框架,通过比较待适应模型和专家模型的输出来生成语义上具有挑战性的问题。
- 在LegalBench语料库上的实验表明,该方法能够以更少的合成样本实现更高的准确性,提升了样本效率。
📝 摘要(中文)
大型语言模型(LLMs)虽然经过了广泛的互联网语料预训练,但通常难以有效地适应特定领域。微调这些模型以适应这些领域的需求越来越受到关注;然而,高质量、任务相关数据的稀缺性和覆盖范围有限性制约了这一进展。为了解决这个问题,通常采用释义或知识提取等合成数据生成方法。虽然这些方法擅长事实回忆和概念知识,但它们存在两个关键缺陷:(i)它们对这些专门领域的解释性推理能力提供的支持极少,(ii)它们通常产生过于庞大和冗余的合成语料库,导致样本效率低下。为了克服这些差距,我们提出了一种对抗性问题生成框架,该框架生成一组紧凑的、语义上具有挑战性的问题。这些问题是通过比较待适应模型和基于参考文档的鲁棒专家模型的输出而构建的,使用迭代的、反馈驱动的过程,旨在揭示和解决理解差距。在LegalBench语料库的专门子集上的评估表明,我们的方法以明显更少的合成样本实现了更高的准确性。
🔬 方法详解
问题定义:论文旨在解决领域特定大型语言模型(LLMs)微调时,高质量训练数据稀缺且现有合成数据生成方法存在不足的问题。现有方法,如释义和知识抽取,生成的合成数据通常缺乏解释性推理能力,并且数据冗余度高,导致模型训练的样本效率低下。
核心思路:论文的核心思路是利用对抗性问答生成框架,生成更具挑战性和信息量的合成数据,从而提高领域特定LLMs的微调效果和样本效率。通过比较待适应模型和专家模型的输出,迭代生成能够揭示模型理解差距的问题,并利用这些问题进行训练。
技术框架:整体框架包含以下几个主要模块:1) 专家模型:一个在领域知识上表现良好的模型,作为生成对抗样本的基准。2) 待适应模型:需要进行领域特定微调的LLM。3) 问题生成器:根据专家模型和待适应模型的输出差异,生成具有挑战性的问题。4) 反馈机制:迭代地生成问题,并根据模型的表现调整问题生成策略。流程上,首先利用专家模型和待适应模型对同一文档进行问答,然后比较两者的答案。如果答案不一致,则问题生成器会生成新的问题,旨在区分两个模型的理解能力。这些新生成的问题被用于训练待适应模型,从而提高其在特定领域的理解能力。
关键创新:最重要的技术创新点在于对抗性问题生成策略。与传统的合成数据生成方法不同,该方法不是简单地复制或释义现有数据,而是通过比较模型之间的差异,主动挖掘模型理解上的薄弱环节,并生成针对性的训练数据。这种方法能够更有效地利用有限的训练数据,提高模型的泛化能力。
关键设计:论文的关键设计包括:1) 问题生成策略:如何根据模型输出的差异生成具有挑战性的问题。具体策略未知。2) 专家模型的选择:选择合适的专家模型至关重要,专家模型的性能直接影响对抗样本的质量。具体选择策略未知。3) 迭代训练过程:如何平衡问题生成和模型训练,避免模型陷入局部最优。具体平衡策略未知。
🖼️ 关键图片
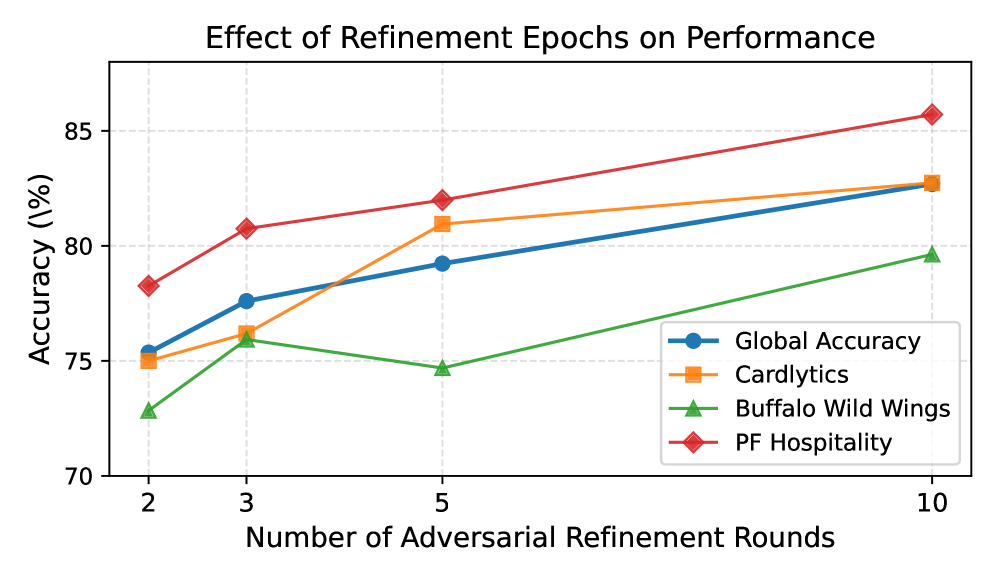
📊 实验亮点
该方法在LegalBench语料库的专门子集上进行了评估,实验结果表明,与传统的合成数据生成方法相比,该方法能够以更少的合成样本实现更高的准确性。具体的性能提升数据未知,但强调了样本效率的显著提升。
🎯 应用场景
该研究成果可广泛应用于需要领域知识的LLM微调场景,例如法律、金融、医疗等领域。通过更有效地利用有限的领域数据,可以降低模型训练成本,提高模型在特定领域的性能,从而促进LLM在专业领域的应用。
📄 摘要(原文)
Large Language Models (LLMs), despite extensive pretraining on broad internet corpora, often struggle to adapt effectively to specialized domains. There is growing interest in fine-tuning these models for such domains; however, progress is constrained by the scarcity and limited coverage of high-quality, task-relevant data. To address this, synthetic data generation methods such as paraphrasing or knowledge extraction are commonly applied. Although these approaches excel at factual recall and conceptual knowledge, they suffer from two critical shortcomings: (i) they provide minimal support for interpretive reasoning capabilities in these specialized domains, and (ii) they often produce synthetic corpora that are excessively large and redundant, resulting in poor sample efficiency. To overcome these gaps, we propose an adversarial question-generation framework that produces a compact set of semantically challenging questions. These questions are constructed by comparing the outputs of the model to be adapted and a robust expert model grounded in reference documents, using an iterative, feedback-driven process designed to reveal and address comprehension gaps. Evaluation on specialized subsets of the LegalBench corpus demonstrates that our method achieves greater accuracy with substantially fewer synthetic samples.