Using LLMs for Knowledge Component-level Correctness Labeling in Open-ended Coding Problems
作者: Zhangqi Duan, Arnav Kankaria, Dhruv Kartik, Andrew Lan
分类: cs.CL, cs.CY
发布日期: 2026-02-19
💡 一句话要点
利用大语言模型为开放式编程问题中的知识组件进行正确性标注
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识组件标注 大型语言模型 开放式编程 学生建模 学习分析 代码理解 时间上下文感知
📋 核心要点
- 开放式编程任务中缺乏细粒度的知识组件(KC)级别的正确性标注,阻碍了对学生掌握情况的准确评估。
- 该论文提出利用大型语言模型(LLM)自动标注学生代码中KC级别的正确性,并引入时间上下文感知的Code-KC映射机制。
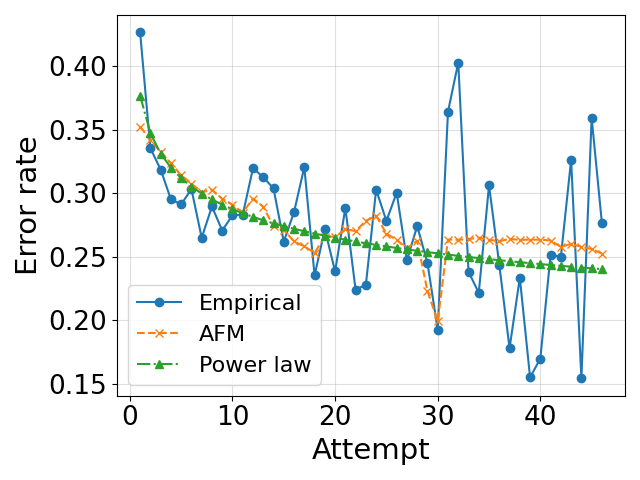
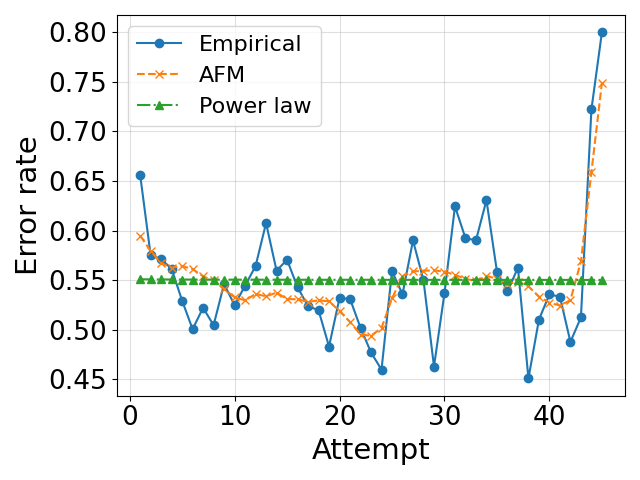
- 实验表明,该框架生成的KC级别标签能够产生更符合认知理论的学习曲线,并提升预测性能,且与专家标注高度一致。
📝 摘要(中文)
细粒度的技能表示,通常被称为知识组件(KCs),是学生建模和学习分析中许多方法的基础。然而,在真实世界的数据集中,KC级别的正确性标签很少可用,特别是对于开放式编程任务,因为其解决方案通常涉及多个KC。简单地将问题级别的正确性传播到所有相关的KC会模糊部分掌握情况,并经常导致拟合不良的学习曲线。为了解决这个挑战,我们提出了一个自动化框架,该框架利用大型语言模型(LLM)直接从学生编写的代码中标记KC级别的正确性。我们的方法评估每个KC是否被正确应用,并进一步引入时间上下文感知的Code-KC映射机制,以更好地将KC与单个学生代码对齐。我们使用实践的幂律和加性因子模型,从学习曲线拟合和预测性能方面评估生成的KC级别正确性标签。实验结果表明,与基线相比,我们的框架产生了与认知理论更一致的学习曲线,并提高了预测性能。人工评估进一步证明了LLM和专家注释之间的高度一致性。
🔬 方法详解
问题定义:现有学生建模和学习分析方法依赖于细粒度的知识组件(KC)表示。然而,在开放式编程任务中,获取KC级别的正确性标注非常困难。简单地将问题级别的正确性传播到所有相关KC会导致对学生掌握情况的错误评估,影响学习曲线的拟合和预测。
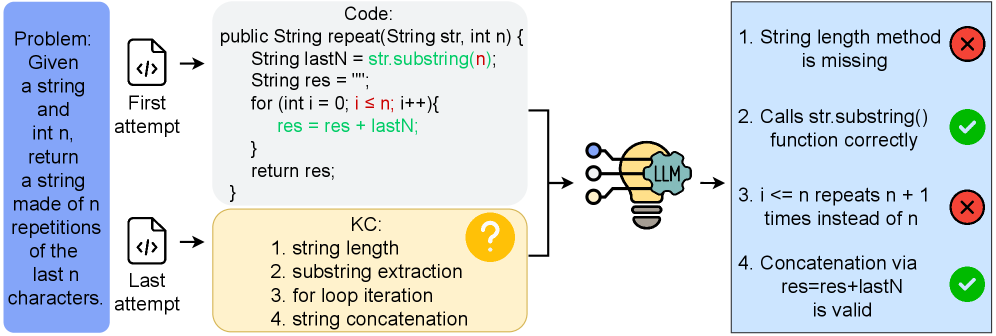
核心思路:利用大型语言模型(LLM)的强大代码理解能力,直接从学生编写的代码中推断出每个KC是否被正确应用。通过分析代码片段,判断其是否正确实现了特定的知识点。
技术框架:该框架包含以下几个主要步骤:1) 收集学生编写的代码和对应的KC列表;2) 使用LLM对每个代码片段进行分析,判断其是否正确应用了对应的KC;3) 引入时间上下文感知的Code-KC映射机制,根据学生的历史代码表现,动态调整KC与代码片段的对应关系;4) 使用标注后的KC级别正确性标签进行学生建模和学习分析。
关键创新:该方法的核心创新在于利用LLM进行细粒度的KC级别正确性标注,克服了传统方法中人工标注成本高昂和自动标注精度不足的问题。时间上下文感知的Code-KC映射机制进一步提升了标注的准确性。
关键设计:时间上下文感知的Code-KC映射机制的具体实现方式未知,论文中可能涉及特定的prompt设计,用于指导LLM进行KC级别的正确性判断。此外,损失函数和网络结构等技术细节也可能影响最终的标注效果,但论文中未明确说明。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用该框架生成的KC级别正确性标签,能够产生更符合认知理论的学习曲线,并提升预测性能。与基线方法相比,该框架在学习曲线拟合和预测准确率方面均取得了显著提升。人工评估结果显示,LLM的标注结果与专家标注结果具有高度一致性,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于在线教育平台、编程学习工具和智能辅导系统等领域。通过自动标注学生代码中的知识组件掌握情况,可以更准确地评估学生的学习进度和薄弱环节,从而提供个性化的学习建议和辅导,提升学习效果。此外,该方法还可以用于评估编程课程的教学效果,为课程改进提供数据支持。
📄 摘要(原文)
Fine-grained skill representations, commonly referred to as knowledge components (KCs), are fundamental to many approaches in student modeling and learning analytics. However, KC-level correctness labels are rarely available in real-world datasets, especially for open-ended programming tasks where solutions typically involve multiple KCs simultaneously. Simply propagating problem-level correctness to all associated KCs obscures partial mastery and often leads to poorly fitted learning curves. To address this challenge, we propose an automated framework that leverages large language models (LLMs) to label KC-level correctness directly from student-written code. Our method assesses whether each KC is correctly applied and further introduces a temporal context-aware Code-KC mapping mechanism to better align KCs with individual student code. We evaluate the resulting KC-level correctness labels in terms of learning curve fit and predictive performance using the power law of practice and the Additive Factors Model. Experimental results show that our framework leads to learning curves that are more consistent with cognitive theory and improves predictive performance, compared to baselines. Human evaluation further demonstrates substantial agreement between LLM and expert annotations.