Same Meaning, Different Scores: Lexical and Syntactic Sensitivity in LLM Evaluation
作者: Bogdan Kostić, Conor Fallon, Julian Risch, Alexander Löser
分类: cs.CL, cs.AI
发布日期: 2026-02-19
备注: Accepted at LREC 2026
💡 一句话要点
揭示LLM在词汇和句法扰动下的脆弱性,强调鲁棒性测试的重要性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 鲁棒性评估 词汇扰动 句法扰动 模型评估 自然语言处理 对抗性样本 语言理解
📋 核心要点
- 现有LLM评测基准对输入提示的浅层变化敏感,导致模型性能评估的可靠性受到质疑。
- 该研究通过词汇和句法扰动,分析LLM在保持语义不变的情况下对输入变化的鲁棒性。
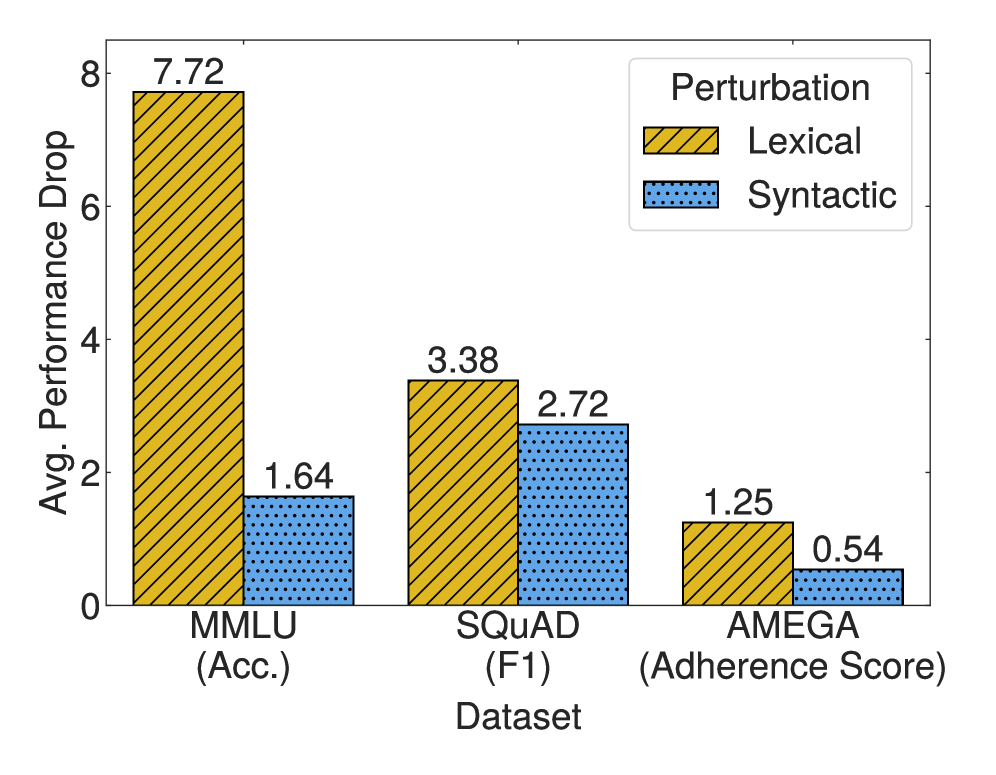
- 实验表明,词汇扰动显著降低LLM性能,句法扰动影响不一,且模型鲁棒性与模型大小并非线性相关。
📝 摘要(中文)
大型语言模型(LLM)的快速发展使得标准化评测基准成为模型比较的主要工具。然而,由于对输入提示中浅层变化的敏感性,其可靠性日益受到质疑。本文研究了受控的、真值条件等价的词汇和句法扰动如何影响23个当代LLM在MMLU、SQuAD和AMEGA三个基准测试中的绝对性能和相对排名。我们采用两种语言学原理的流程来生成保持语义的变体:一种执行同义词替换以进行词汇更改,另一种使用依存关系解析来确定适用的句法转换。结果表明,词汇扰动始终会导致几乎所有模型和任务的性能显著下降,而句法扰动具有更异构的影响,有时会提高结果。两种扰动类型都会破坏复杂任务上的模型排行榜。此外,模型鲁棒性并未始终随模型大小而扩展,揭示了很强的任务依赖性。总体而言,研究结果表明,LLM更多地依赖于表面词汇模式,而不是抽象的语言能力,强调了将鲁棒性测试作为LLM评估的标准组成部分的需求。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)评估方法,主要依赖于标准化的评测基准。然而,这些基准测试容易受到输入提示的微小变化的影响,即使这些变化并不改变句子的语义。这使得模型之间的比较变得不可靠,难以准确评估模型的真实语言理解能力。现有方法的痛点在于缺乏对模型鲁棒性的有效评估,即模型在面对语义等价但表达不同的输入时,能否保持一致的性能。
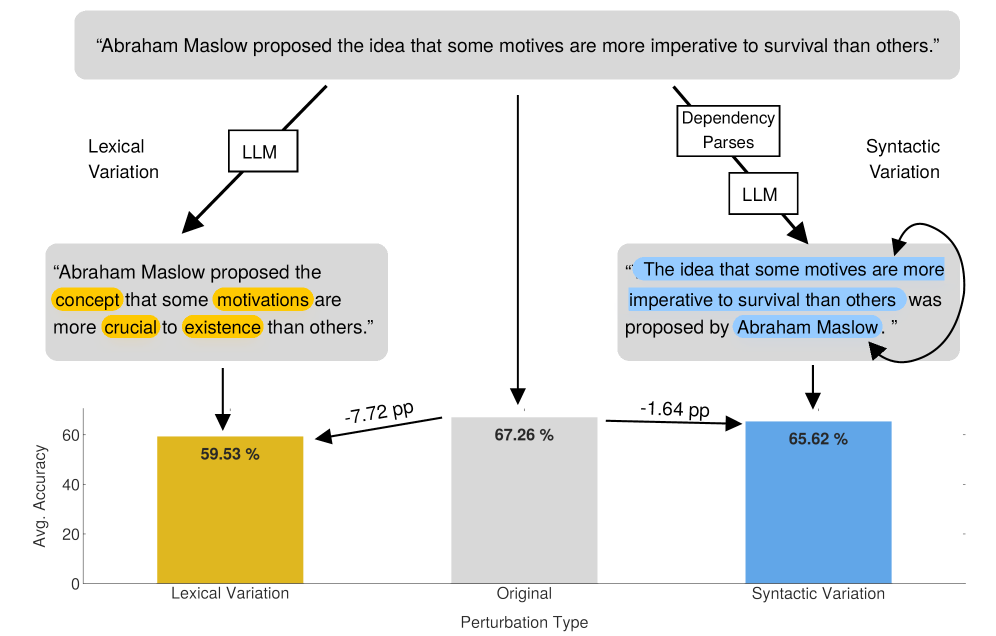
核心思路:本文的核心思路是通过引入受控的、语义保持的词汇和句法扰动,来测试LLM对输入变化的敏感程度。通过观察模型在原始输入和扰动输入下的性能差异,可以评估模型的鲁棒性,并揭示模型是否过度依赖于表面词汇模式,而非真正的语言理解。
技术框架:该研究的技术框架主要包括以下几个步骤:1. 选择三个常用的LLM评测基准:MMLU、SQuAD和AMEGA。2. 选择23个当代LLM进行评估。3. 构建两个语言学原理的扰动生成pipeline:一个用于生成词汇扰动(同义词替换),另一个用于生成句法扰动(基于依存关系解析的句法转换)。4. 使用原始输入和扰动输入分别对LLM进行测试,并记录性能指标。5. 分析性能差异,评估模型的鲁棒性,并比较不同模型之间的表现。
关键创新:该研究的关键创新在于:1. 系统性地研究了词汇和句法扰动对LLM性能的影响。2. 使用了语言学原理的扰动生成方法,保证了扰动的语义保持性。3. 揭示了LLM对表面词汇模式的过度依赖,以及鲁棒性与模型大小之间非线性关系。4. 强调了鲁棒性测试在LLM评估中的重要性。
关键设计:在词汇扰动方面,使用了WordNet等词典资源进行同义词替换,并根据词性进行过滤,以保证替换的合理性。在句法扰动方面,使用了Stanford CoreNLP等工具进行依存关系解析,并根据解析结果进行句法转换,例如主动语态和被动语态的转换、句子成分的调换等。在实验设置方面,对每个模型和每个任务都进行了多次重复实验,以保证结果的统计显著性。性能指标主要包括准确率、F1值等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,词汇扰动对几乎所有模型和任务都造成了显著的性能下降,而句法扰动的影响则较为复杂,有时甚至能提升性能。在MMLU基准测试中,词汇扰动平均导致模型性能下降5-10个百分点。此外,研究还发现,模型的鲁棒性与模型大小并非线性相关,一些较小的模型在特定任务上表现出比大型模型更好的鲁棒性。
🎯 应用场景
该研究成果可应用于LLM的鲁棒性评估和提升。通过引入对抗性样本,可以训练更鲁棒的LLM,提高其在真实世界复杂场景中的应用性能。此外,该研究也为LLM评测基准的改进提供了思路,可以设计更全面的评测方法,更准确地评估模型的语言理解能力。
📄 摘要(原文)
The rapid advancement of Large Language Models (LLMs) has established standardized evaluation benchmarks as the primary instrument for model comparison. Yet, their reliability is increasingly questioned due to sensitivity to shallow variations in input prompts. This paper examines how controlled, truth-conditionally equivalent lexical and syntactic perturbations affect the absolute performance and relative ranking of 23 contemporary LLMs across three benchmarks: MMLU, SQuAD, and AMEGA. We employ two linguistically principled pipelines to generate meaning-preserving variations: one performing synonym substitution for lexical changes, and another using dependency parsing to determine applicable syntactic transformations. Results show that lexical perturbations consistently induce substantial, statistically significant performance degradation across nearly all models and tasks, while syntactic perturbations have more heterogeneous effects, occasionally improving results. Both perturbation types destabilize model leaderboards on complex tasks. Furthermore, model robustness did not consistently scale with model size, revealing strong task dependence. Overall, the findings suggest that LLMs rely more on surface-level lexical patterns than on abstract linguistic competence, underscoring the need for robustness testing as a standard component of LLM evaluation.