Scaling Open Discrete Audio Foundation Models with Interleaved Semantic, Acoustic, and Text Tokens
作者: Potsawee Manakul, Woody Haosheng Gan, Martijn Bartelds, Guangzhi Sun, William Held, Diyi Yang
分类: cs.SD, cs.CL, eess.AS
发布日期: 2026-02-18
💡 一句话要点
提出SODA:通过交错语义、声学和文本token扩展开放离散音频基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频语言模型 离散音频建模 缩放定律 多模态学习 语音翻译
📋 核心要点
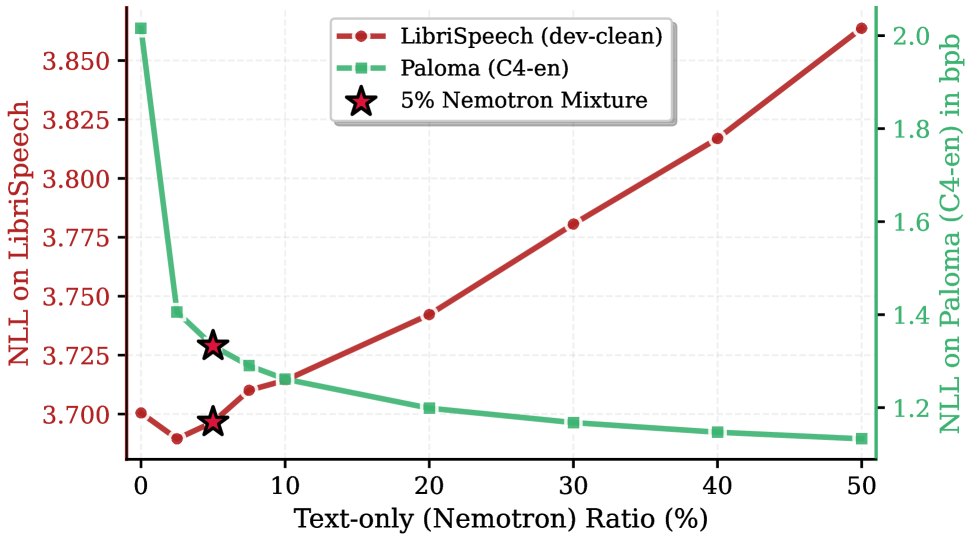
- 现有音频语言模型主要以文本为先,限制了通用音频建模能力,无法充分捕捉音频的细粒度信息。
- 论文提出SODA模型,通过联合建模语义、声学和文本token,实现更全面的音频理解和生成能力。
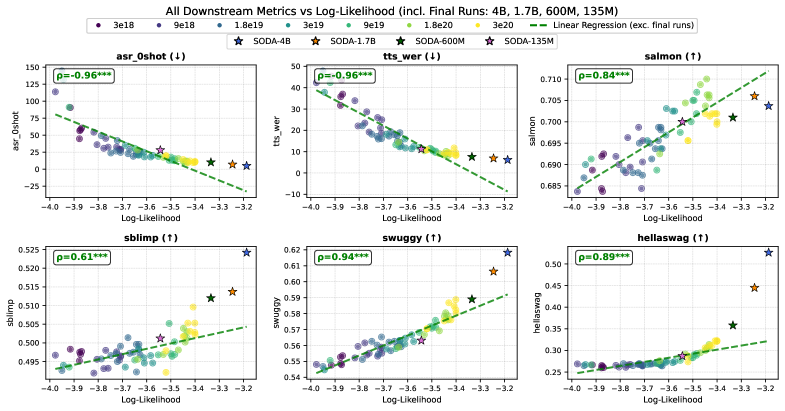
- 通过IsoFLOP分析,揭示了离散音频模型缩放定律,并训练了参数规模从1.35亿到40亿的SODA模型套件。
📝 摘要(中文)
本文提出了一种原生音频基础模型,通过联合建模语义内容、声学细节和文本,以支持通用音频生成和跨模态能力。该模型采用next-token预测方法,并对音频进行大规模建模。本文对构建此类模型提供了全面的经验性见解:(1) 系统地研究了数据来源、文本混合比例和token组成等设计选择,建立了一个经过验证的训练方案。(2) 通过对64个模型进行IsoFLOP分析,首次对离散音频模型进行了缩放定律研究,发现最佳数据增长速度比最佳模型大小快1.6倍。(3) 应用这些经验训练了SODA (Scaling Open Discrete Audio) 模型套件,参数规模从1.35亿到40亿,并在5000亿个token上进行训练,并将其与缩放预测和现有模型进行比较。SODA可以作为各种音频/文本任务的灵活骨干网络,并通过微调用于语音保留的语音到语音翻译来证明这一点,使用相同的统一架构。
🔬 方法详解
问题定义:现有音频语言模型主要依赖于文本信息或仅使用语义token,无法充分捕捉音频的声学细节,限制了其在通用音频建模方面的能力。现有方法难以同时处理音频的语义内容、声学细节和文本信息,导致跨模态任务的性能受限。
核心思路:论文的核心思路是构建一个原生音频基础模型,该模型能够同时处理音频的语义内容、声学细节和文本信息。通过联合建模这三种信息,模型可以更好地理解音频的各个方面,从而支持更广泛的音频生成和跨模态任务。这种设计旨在克服现有模型对文本或语义信息的过度依赖,从而提高模型的通用性和性能。
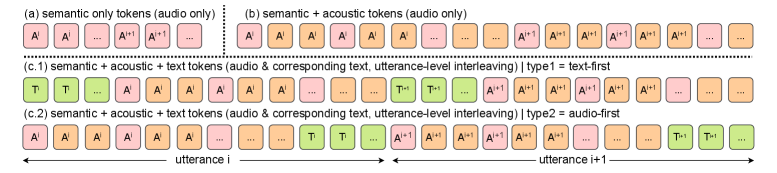
技术框架:SODA模型的整体架构基于next-token预测。模型接收交错的语义、声学和文本token作为输入,并预测序列中的下一个token。训练过程涉及大规模的音频和文本数据集。模型架构采用Transformer结构,并针对音频数据的特性进行了优化。
关键创新:该论文的关键创新在于提出了一个能够同时处理语义、声学和文本token的统一模型架构。与现有模型相比,SODA模型能够更全面地理解音频信息,从而在各种音频任务中实现更好的性能。此外,该论文还首次对离散音频模型进行了缩放定律研究,为未来模型的开发提供了指导。
关键设计:论文中关键的设计包括:(1) 数据选择和混合策略,包括音频和文本数据的比例;(2) token组成方式,如何将语义、声学和文本信息编码为token;(3) 模型缩放策略,如何根据计算资源和数据量选择合适的模型大小;(4) 损失函数的设计,如何平衡不同类型token的预测精度。
🖼️ 关键图片
📊 实验亮点
论文通过IsoFLOP分析,揭示了离散音频模型的缩放定律,发现最佳数据增长速度比最佳模型大小快1.6倍。训练的SODA模型套件,参数规模从1.35亿到40亿,并在5000亿个token上进行训练,并在语音保留的语音到语音翻译任务上进行了微调,验证了其作为灵活骨干网络的有效性。
🎯 应用场景
该研究成果可广泛应用于语音合成、语音识别、音乐生成、音频编辑等领域。SODA模型作为灵活的骨干网络,能够支持各种音频/文本任务,例如语音翻译、语音克隆、跨模态信息检索等。该研究有助于推动通用音频智能的发展,并为未来的音频应用提供更强大的技术支持。
📄 摘要(原文)
Current audio language models are predominantly text-first, either extending pre-trained text LLM backbones or relying on semantic-only audio tokens, limiting general audio modeling. This paper presents a systematic empirical study of native audio foundation models that apply next-token prediction to audio at scale, jointly modeling semantic content, acoustic details, and text to support both general audio generation and cross-modal capabilities. We provide comprehensive empirical insights for building such models: (1) We systematically investigate design choices -- data sources, text mixture ratios, and token composition -- establishing a validated training recipe. (2) We conduct the first scaling law study for discrete audio models via IsoFLOP analysis on 64 models spanning $3{\times}10^{18}$ to $3{\times}10^{20}$ FLOPs, finding that optimal data grows 1.6$\times$ faster than optimal model size. (3) We apply these lessons to train SODA (Scaling Open Discrete Audio), a suite of models from 135M to 4B parameters on 500B tokens, comparing against our scaling predictions and existing models. SODA serves as a flexible backbone for diverse audio/text tasks -- we demonstrate this by fine-tuning for voice-preserving speech-to-speech translation, using the same unified architecture.