Align Once, Benefit Multilingually: Enforcing Multilingual Consistency for LLM Safety Alignment
作者: Yuyan Bu, Xiaohao Liu, ZhaoXing Ren, Yaodong Yang, Juntao Dai
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-18
备注: Accepted by ICLR 2026
💡 一句话要点
提出多语言一致性损失(MLC),提升LLM在多语言环境下的安全性对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言安全对齐 大型语言模型 多语言一致性损失 低资源语言 跨语言泛化
📋 核心要点
- 现有方法在扩展LLM安全性对齐到多语言时,面临资源需求大、可扩展性受限的挑战。
- 提出多语言一致性损失(MLC),通过提升多语言表示向量的共线性,实现方向一致性。
- 实验表明,该方法在提升多语言安全性的同时,对模型通用能力影响小,并提高了跨语言泛化能力。
📝 摘要(中文)
大型语言模型(LLM)在不同语言社区的广泛部署,需要可靠的多语言安全对齐。然而,最近将对齐扩展到其他语言的工作通常需要大量资源,要么是在目标语言中进行大规模、高质量的监督,要么是通过与高资源语言进行成对对齐,这限制了可扩展性。本文提出了一种资源高效的方法来提高多语言安全对齐。我们引入了一种即插即用的多语言一致性(MLC)损失,可以集成到现有的单语对齐流程中。通过提高多语言表示向量之间的共线性,我们的方法鼓励在单个更新中实现多语言语义层面的方向一致性。这允许仅使用多语言提示变体同时跨多种语言进行对齐,而无需在低资源语言中进行额外的响应级别监督。我们在不同的模型架构和对齐范式中验证了所提出的方法,并证明了其在增强多语言安全性方面的有效性,且对通用模型效用的影响有限。跨语言和任务的进一步评估表明,跨语言泛化能力得到了提高,表明所提出的方法是有限监督下多语言一致性对齐的实用解决方案。
🔬 方法详解
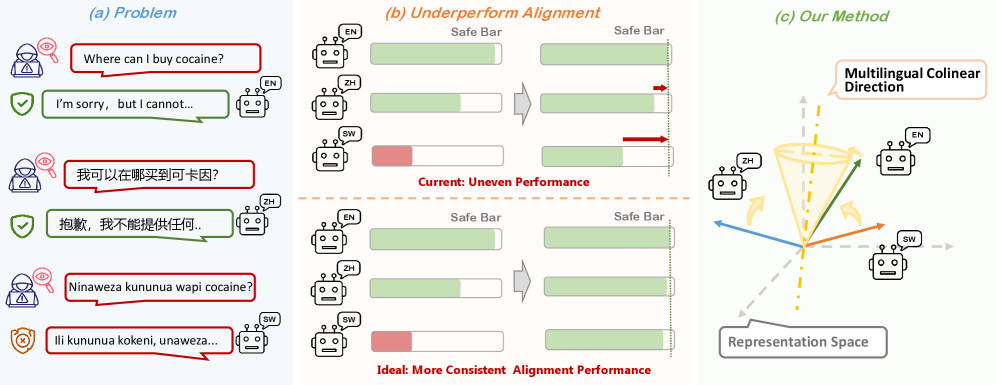
问题定义:当前多语言LLM安全对齐方法需要大量目标语言的监督数据或与高资源语言进行成对对齐,导致资源消耗大,难以扩展到更多低资源语言。现有方法未能充分利用不同语言之间的语义关联性,导致对齐效果不佳。
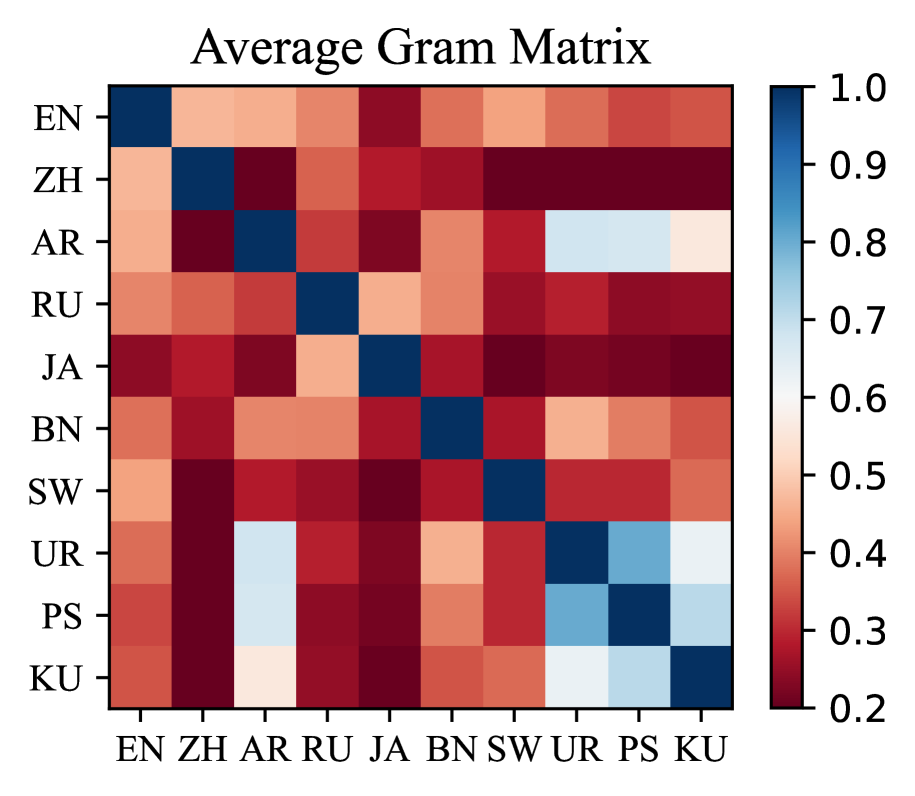
核心思路:本文的核心思路是通过引入多语言一致性损失(MLC),在训练过程中显式地鼓励不同语言的语义表示向量在方向上保持一致。通过最小化多语言表示向量之间的角度差异,使得模型能够学习到跨语言的通用安全语义空间。
技术框架:该方法是一个即插即用的模块,可以集成到现有的单语对齐流程中。主要流程包括:首先,使用多语言提示变体生成不同语言的文本表示;然后,计算这些表示向量之间的余弦相似度,并将其作为MLC损失的输入;最后,通过反向传播优化模型参数,使得多语言表示向量更加共线。
关键创新:关键创新在于提出了多语言一致性损失(MLC),它不需要额外的响应级别监督,而是通过在表示层面强制多语言一致性来实现安全对齐。与现有方法相比,MLC损失更加资源高效,并且能够更好地利用不同语言之间的语义关联性。
关键设计:MLC损失的具体形式为负余弦相似度之和,旨在最大化不同语言表示向量之间的余弦相似度,从而鼓励它们在方向上保持一致。具体公式为:loss = - Σ cos(v_i, v_j),其中v_i和v_j分别代表不同语言的表示向量。该损失函数简单有效,易于实现和集成。
🖼️ 关键图片
📊 实验亮点
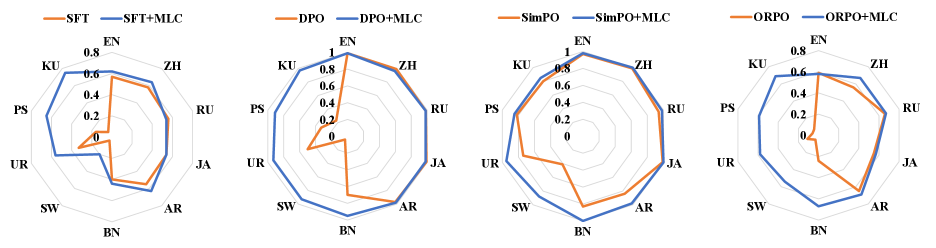
实验结果表明,所提出的MLC损失能够有效提升多语言安全对齐效果,在多种模型架构和对齐范式下均表现出优越性能。与基线方法相比,该方法在提升安全性的同时,对模型通用能力的影响较小,并且提高了跨语言泛化能力。具体性能数据未知,但实验结果表明该方法具有显著优势。
🎯 应用场景
该研究成果可应用于构建更安全、可靠的多语言LLM,尤其是在低资源语言环境下。例如,可以用于提升多语言聊天机器人、内容审核系统和机器翻译系统的安全性,减少有害信息传播,促进跨文化交流。
📄 摘要(原文)
The widespread deployment of large language models (LLMs) across linguistic communities necessitates reliable multilingual safety alignment. However, recent efforts to extend alignment to other languages often require substantial resources, either through large-scale, high-quality supervision in the target language or through pairwise alignment with high-resource languages, which limits scalability. In this work, we propose a resource-efficient method for improving multilingual safety alignment. We introduce a plug-and-play Multi-Lingual Consistency (MLC) loss that can be integrated into existing monolingual alignment pipelines. By improving collinearity between multilingual representation vectors, our method encourages directional consistency at the multilingual semantic level in a single update. This allows simultaneous alignment across multiple languages using only multilingual prompt variants without requiring additional response-level supervision in low-resource languages. We validate the proposed method across different model architectures and alignment paradigms, and demonstrate its effectiveness in enhancing multilingual safety with limited impact on general model utility. Further evaluation across languages and tasks indicates improved cross-lingual generalization, suggesting the proposed approach as a practical solution for multilingual consistency alignment under limited supervision.