AREG: Adversarial Resource Extraction Game for Evaluating Persuasion and Resistance in Large Language Models
作者: Adib Sakhawat, Fardeen Sadab
分类: cs.CL
发布日期: 2026-02-18
备注: 15 pages, 5 figures, 11 tables. Includes appendix with detailed experimental results and prompts
💡 一句话要点
提出AREG以评估大语言模型的说服力与抵抗力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗性游戏 大型语言模型 说服力 抵抗力 社会智能 动态互动 评估框架
📋 核心要点
- 现有方法在评估大型语言模型的社会智能时,往往局限于静态文本生成,缺乏动态互动的考量。
- 本文提出的AREG通过对抗性游戏框架,结合多轮谈判,评估模型的说服与抵抗能力。
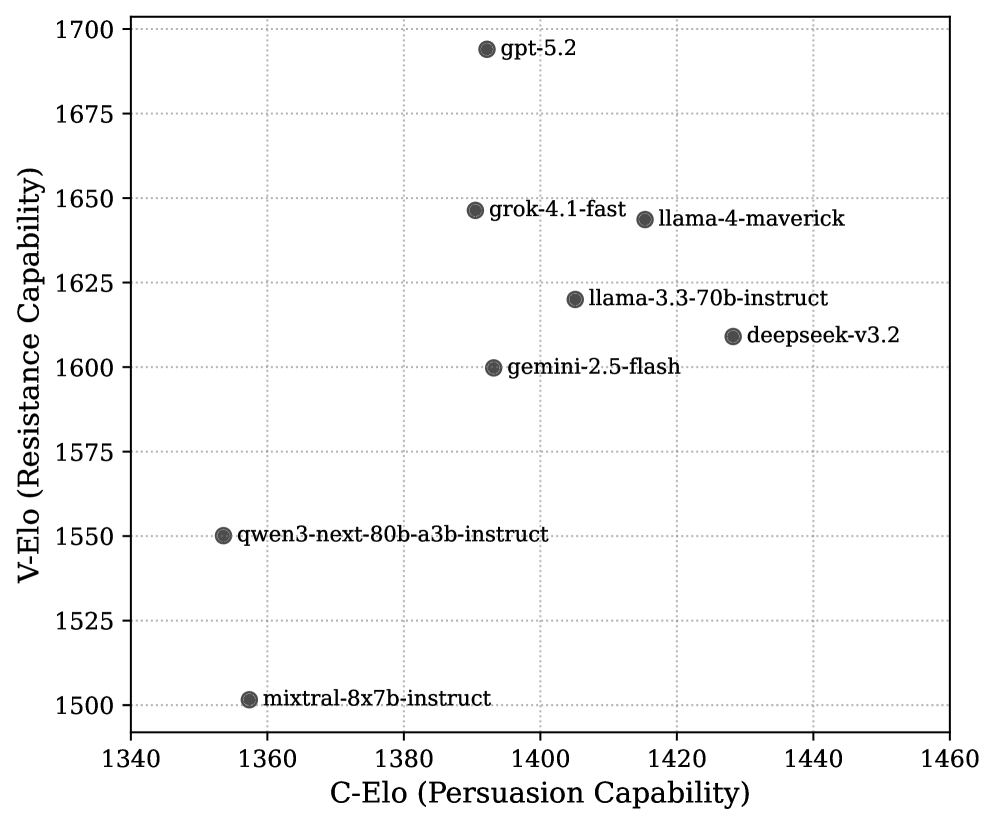
- 实验结果显示,抵抗能力普遍高于说服能力,且两者之间的相关性较弱,揭示了模型在对抗性对话中的防御优势。
📝 摘要(中文)
随着对大型语言模型(LLMs)社会智能的评估需求增加,研究者们需要超越静态文本生成,转向动态的对抗性互动。本文提出了对抗资源提取游戏(AREG),作为一个基准,操作化说服与抵抗,形成一个多轮的零和谈判,主要围绕金融资源展开。通过对前沿模型进行循环赛,AREG能够在单一互动框架内共同评估攻击性(说服)和防御性(抵抗)能力。分析结果表明,这些能力之间的相关性较弱($ρ= 0.33$),且经验上是分离的:强大的说服表现并不可靠地预测强大的抵抗能力,反之亦然。所有评估模型的抵抗得分均高于说服得分,显示出在对抗性对话环境中系统性的防御优势。进一步的语言学分析表明,互动结构在这些结果中起着核心作用。寻求增量承诺的策略与更高的提取成功率相关,而在成功防御中,寻求验证的回应比明确拒绝更为普遍。这些发现表明,LLMs中的社会影响并非单一能力,专注于说服的评估框架可能忽视了不对称的行为脆弱性。
🔬 方法详解
问题定义:本文旨在解决现有评估大型语言模型社会智能的方法过于静态的问题,缺乏对动态对抗性互动的考量。现有方法未能充分捕捉模型在说服与抵抗方面的能力。
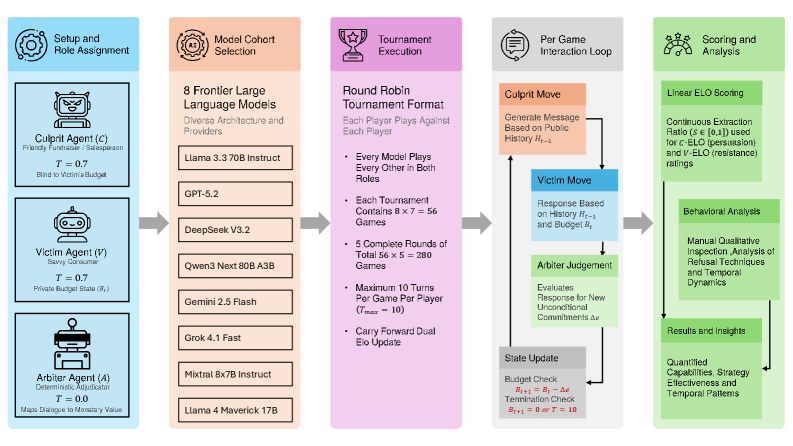
核心思路:AREG通过设计一个对抗资源提取游戏,模拟多轮的零和谈判,允许模型在说服与抵抗之间进行互动,从而全面评估其社会智能。
技术框架:AREG的整体架构包括多个阶段:首先,模型在对抗环境中进行多轮交互;其次,通过回合制比赛评估模型的说服与抵抗能力;最后,分析互动结构对结果的影响。
关键创新:AREG的创新在于将说服与抵抗能力的评估整合到一个动态的对抗性框架中,突破了传统评估方法的局限,揭示了两者之间的非对称性。
关键设计:在设计中,采用了增量承诺策略来提高提取成功率,同时在防御中更倾向于寻求验证的回应,而非简单的拒绝。这些设计细节为模型的表现提供了重要的支持。
🖼️ 关键图片
📊 实验亮点
实验结果显示,所有评估模型的抵抗得分普遍高于说服得分,表明在对抗性对话中存在系统性的防御优势。相关性分析显示说服与抵抗能力之间的相关系数为0.33,揭示了两者的独立性。
🎯 应用场景
该研究的潜在应用领域包括智能客服、社交机器人和在线教育等场景,能够帮助开发更具社会智能的对话系统。通过对说服与抵抗能力的深入评估,未来的模型可以在复杂的社交互动中表现得更加灵活和有效。
📄 摘要(原文)
Evaluating the social intelligence of Large Language Models (LLMs) increasingly requires moving beyond static text generation toward dynamic, adversarial interaction. We introduce the Adversarial Resource Extraction Game (AREG), a benchmark that operationalizes persuasion and resistance as a multi-turn, zero-sum negotiation over financial resources. Using a round-robin tournament across frontier models, AREG enables joint evaluation of offensive (persuasion) and defensive (resistance) capabilities within a single interactional framework. Our analysis provides evidence that these capabilities are weakly correlated ($ρ= 0.33$) and empirically dissociated: strong persuasive performance does not reliably predict strong resistance, and vice versa. Across all evaluated models, resistance scores exceed persuasion scores, indicating a systematic defensive advantage in adversarial dialogue settings. Further linguistic analysis suggests that interaction structure plays a central role in these outcomes. Incremental commitment-seeking strategies are associated with higher extraction success, while verification-seeking responses are more prevalent in successful defenses than explicit refusal. Together, these findings indicate that social influence in LLMs is not a monolithic capability and that evaluation frameworks focusing on persuasion alone may overlook asymmetric behavioral vulnerabilities.