CitiLink-Summ: Summarization of Discussion Subjects in European Portuguese Municipal Meeting Minutes
作者: Miguel Marques, Ana Luísa Fernandes, Ana Filipa Pacheco, Rute Rebouças, Inês Cantante, José Isidro, Luís Filipe Cunha, Alípio Jorge, Nuno Guimarães, Sérgio Nunes, António Leal, Purificação Silvano, Ricardo Campos
分类: cs.CL
发布日期: 2026-02-18
💡 一句话要点
CitiLink-Summ:提出欧洲葡萄牙语市政会议记录讨论主题的自动摘要数据集与基线方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动摘要 市政会议记录 欧洲葡萄牙语 低资源语言 数据集构建
📋 核心要点
- 现有市政会议记录冗长复杂,缺乏高质量摘要数据集,阻碍了低资源语言(如欧洲葡萄牙语)的自动摘要研究。
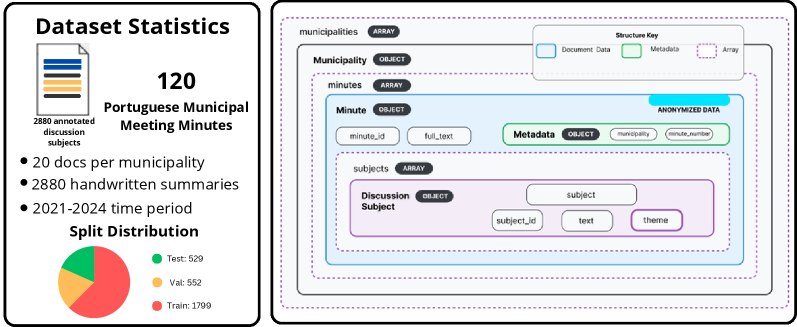
- CitiLink-Summ 提出了一个包含 100 份文档和 2,322 份人工摘要的欧洲葡萄牙语市政会议记录语料库。
- 该研究利用 CitiLink-Summ 数据集,采用 BART、PRIMERA 等模型,建立了自动摘要的基线结果,并使用多种指标进行评估。
📝 摘要(中文)
市政会议记录是记录地方政府讨论和决策的正式文件,但其内容通常冗长、密集,难以供公民查阅。自动摘要可以通过为每个讨论主题生成简洁的摘要来帮助解决这一挑战。尽管具有潜力,但对市政会议记录中讨论主题的摘要研究在很大程度上仍未被探索,尤其是在低资源语言中,这些文档固有的复杂性增加了进一步的挑战。一个主要的瓶颈是缺乏包含高质量、人工编写摘要的数据集,这限制了该领域有效摘要模型的开发和评估。在本文中,我们提出了 CitiLink-Summ,一个新的欧洲葡萄牙语市政会议记录语料库,包含 100 份文档和 2,322 份手动编写的摘要,每个摘要对应于一个不同的讨论主题。利用该数据集,我们为该领域的自动摘要建立了基线结果,采用最先进的生成模型(例如,BART、PRIMERA)以及大型语言模型(LLM),并使用词汇和语义指标(如 ROUGE、BLEU、METEOR 和 BERTScore)进行评估。CitiLink-Summ 为欧洲葡萄牙语市政领域的摘要提供了第一个基准,为推进复杂行政文本的 NLP 研究提供了宝贵的资源。
🔬 方法详解
问题定义:论文旨在解决欧洲葡萄牙语市政会议记录的自动摘要问题。现有方法在低资源语言环境下表现不佳,主要原因是缺乏高质量的标注数据集,难以训练和评估有效的摘要模型。现有的市政会议记录内容冗长,普通公民难以快速获取关键信息。
核心思路:论文的核心思路是构建一个高质量的欧洲葡萄牙语市政会议记录摘要数据集(CitiLink-Summ),并基于此数据集训练和评估现有的摘要模型,为后续研究提供基准。通过人工编写摘要,确保摘要的质量和准确性,从而克服低资源语言环境下的数据稀缺问题。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集:收集欧洲葡萄牙语市政会议记录;2) 数据标注:人工编写每个讨论主题的摘要;3) 模型训练:使用 CitiLink-Summ 数据集训练现有的摘要模型,包括 BART、PRIMERA 等;4) 模型评估:使用 ROUGE、BLEU、METEOR 和 BERTScore 等指标评估模型的性能。
关键创新:该研究的关键创新在于构建了 CitiLink-Summ 数据集,这是第一个用于欧洲葡萄牙语市政会议记录摘要的公开数据集。该数据集的发布填补了低资源语言环境下高质量摘要数据集的空白,为后续研究提供了宝贵的资源。
关键设计:数据集包含100份文档和2322份人工摘要,摘要的质量通过人工审核保证。研究中使用了多种先进的生成式摘要模型,包括BART和PRIMERA,并采用了多种评估指标,包括词汇重叠度量(ROUGE、BLEU、METEOR)和语义相似度量(BERTScore),以全面评估模型的性能。具体参数设置和训练细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
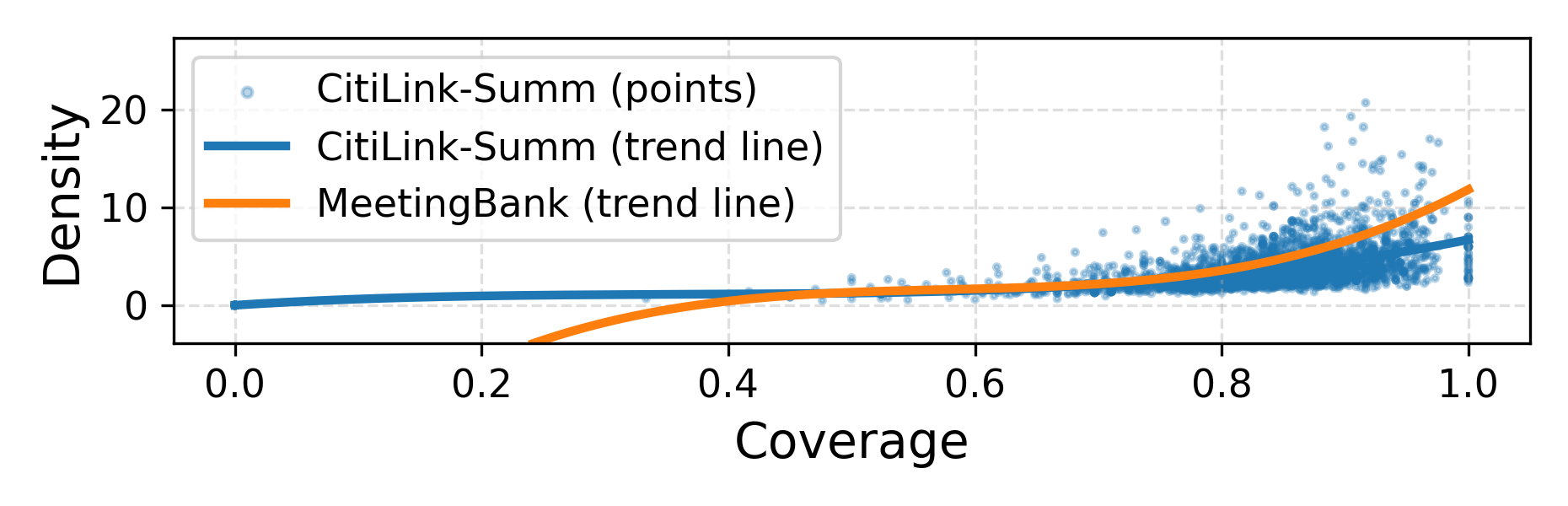
研究构建了包含2322份人工摘要的CitiLink-Summ数据集,并基于此数据集评估了BART和PRIMERA等模型的性能。实验结果表明,现有模型在市政会议记录摘要任务上仍有提升空间,为后续研究提供了明确的方向。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于构建智能市政服务平台,帮助公民快速了解市政会议内容,提高政府透明度。此外,该数据集和基线方法可促进低资源语言的自然语言处理研究,尤其是在行政文本摘要领域。未来可扩展到其他政府文档的自动摘要,提升政务效率。
📄 摘要(原文)
Municipal meeting minutes are formal records documenting the discussions and decisions of local government, yet their content is often lengthy, dense, and difficult for citizens to navigate. Automatic summarization can help address this challenge by producing concise summaries for each discussion subject. Despite its potential, research on summarizing discussion subjects in municipal meeting minutes remains largely unexplored, especially in low-resource languages, where the inherent complexity of these documents adds further challenges. A major bottleneck is the scarcity of datasets containing high-quality, manually crafted summaries, which limits the development and evaluation of effective summarization models for this domain. In this paper, we present CitiLink-Summ, a new corpus of European Portuguese municipal meeting minutes, comprising 100 documents and 2,322 manually hand-written summaries, each corresponding to a distinct discussion subject. Leveraging this dataset, we establish baseline results for automatic summarization in this domain, employing state-of-the-art generative models (e.g., BART, PRIMERA) as well as large language models (LLMs), evaluated with both lexical and semantic metrics such as ROUGE, BLEU, METEOR, and BERTScore. CitiLink-Summ provides the first benchmark for municipal-domain summarization in European Portuguese, offering a valuable resource for advancing NLP research on complex administrative texts.