Optimizing Soft Prompt Tuning via Structural Evolution
作者: Zhenzhen Huang, Chaoning Zhang, Haoyu Bian, Songbo Zhang, Chi-lok Andy Tai, Jiaquan Zhang, Caiyan Qin, Jingjing Qu, Yalan Ye, Yang Yang, Heng Tao Shen
分类: cs.CL
发布日期: 2026-02-18
备注: This manuscript has been submitted to IEEE Transactions on Knowledge and Data Engineering (TKDE) for peer review
💡 一句话要点
提出基于结构演化的软提示优化方法,提升大语言模型微调性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 软提示微调 拓扑数据分析 持久同调 预训练语言模型 少样本学习
📋 核心要点
- 软提示微调缺乏可解释性,其高维隐式表示限制了对训练过程的理解和优化。
- 利用拓扑数据分析量化软提示的结构信息,设计拓扑软提示损失函数(TSLoss)引导模型学习。
- 实验表明,TSLoss能够加速收敛,提升微调性能,并提供结构和拓扑视角的可解释性。
📝 摘要(中文)
软提示微调利用连续嵌入在大规模预训练语言模型(LLMs)中捕获特定任务的信息,在少样本设置中取得了有竞争力的性能。然而,软提示依赖于高维、隐式的表示,缺乏显式的语义和可追踪的训练行为,这限制了它们的可解释性。为了解决这个限制,我们提出了一种基于拓扑形态演化的软提示微调优化方法。具体来说,我们采用拓扑数据分析(TDA)中的持久同调来量化连续参数空间中软提示的结构表示及其训练过程演化。定量分析表明,拓扑稳定的、紧凑的软提示能够实现更好的下游性能。基于这一经验观察,我们构建了一个用于优化软提示微调的损失函数,称为拓扑软提示损失(TSLoss)。TSLoss通过量化参数间的连通性和冗余性,引导模型学习结构稳定的适应。大量的实验表明,使用TSLoss进行训练可以加速收敛并提高微调性能,从而提供了一种可解释的方法,从结构和拓扑的角度理解和优化软提示微调。
🔬 方法详解
问题定义:软提示微调虽然在少样本学习中表现出色,但其内部机制难以理解。软提示本质上是高维连续向量,缺乏明确的语义,训练过程也难以追踪,这阻碍了我们深入理解和优化软提示微调。
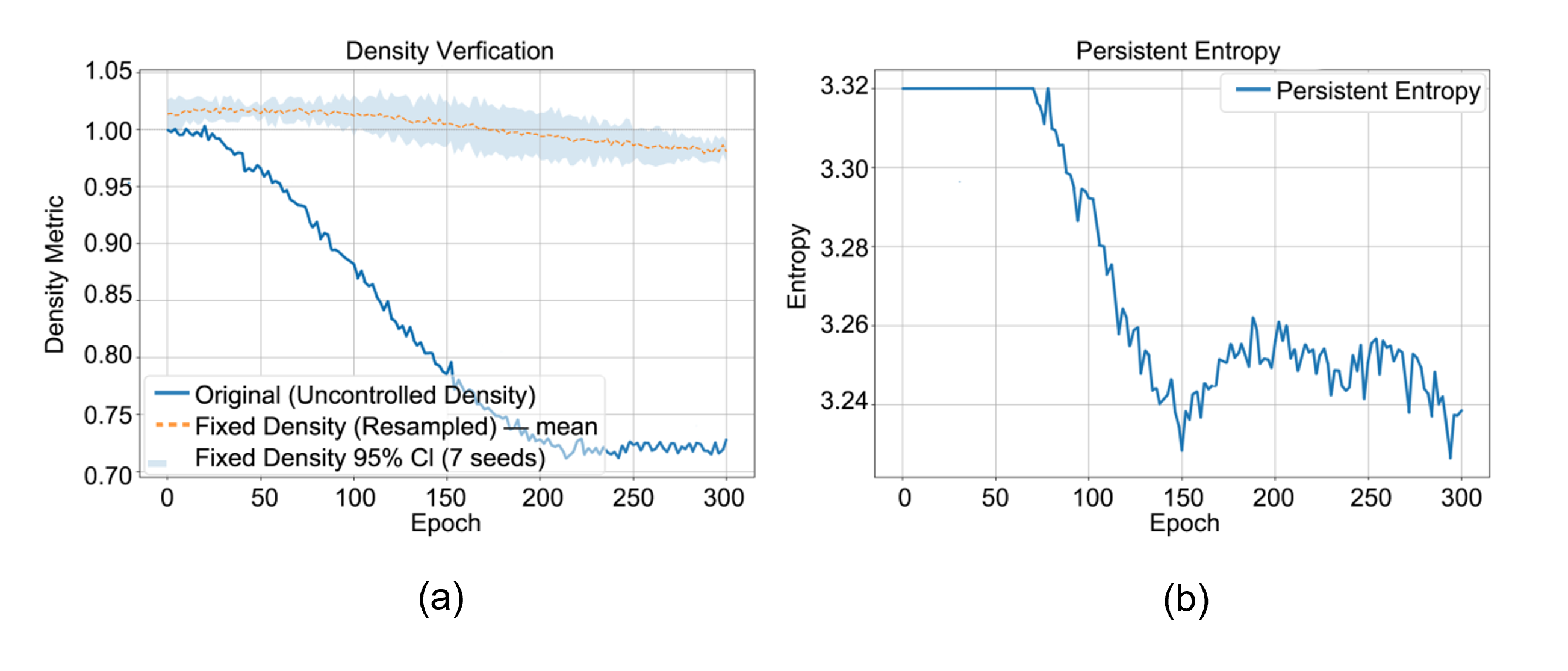
核心思路:论文的核心思路是利用拓扑数据分析(TDA)中的持久同调来量化软提示的结构信息。通过分析软提示在训练过程中的拓扑结构演化,可以识别出稳定且紧凑的结构,并将其作为优化目标。作者假设,拓扑结构更稳定的软提示能够更好地泛化到下游任务。
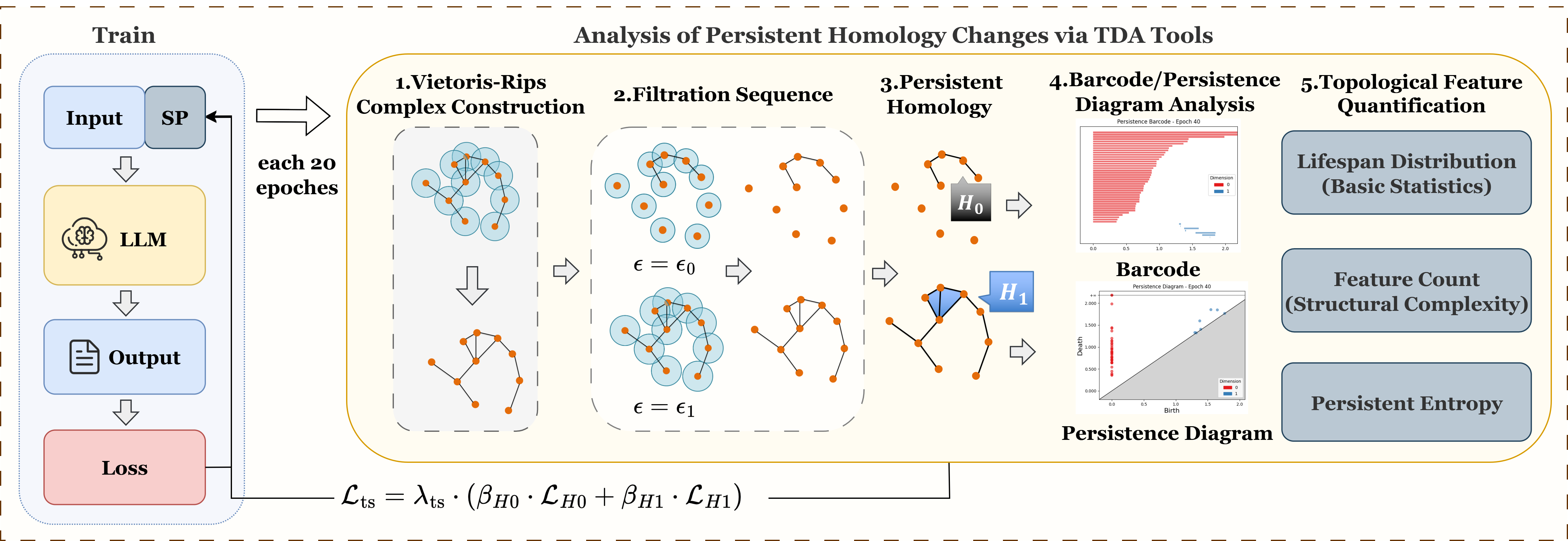
技术框架:该方法主要包含以下几个阶段:1) 使用预训练语言模型和软提示进行微调;2) 在训练过程中,利用持久同调分析软提示的拓扑结构,提取拓扑特征;3) 基于拓扑特征构建拓扑软提示损失(TSLoss);4) 将TSLoss与原始的微调损失函数结合,共同优化软提示。
关键创新:该方法最重要的创新点在于将拓扑数据分析引入到软提示微调的优化过程中。通过量化软提示的结构信息,并将其作为优化目标,可以有效地提高软提示的可解释性和泛化能力。与传统的优化方法相比,该方法能够从结构和拓扑的角度理解和优化软提示微调。
关键设计:TSLoss是该方法中的关键设计。它基于持久同调计算得到的拓扑特征,量化了软提示参数之间的连通性和冗余性。具体来说,TSLoss鼓励软提示学习具有较少孔洞(即拓扑结构更简单)且参数之间连接更紧密的结构。TSLoss的具体形式未知,但其目标是最小化软提示的拓扑复杂度,从而提高其稳定性和泛化能力。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了TSLoss的有效性。实验结果表明,使用TSLoss进行训练可以加速收敛,并提高微调性能。具体性能提升数据未知,但论文强调TSLoss能够提供一种可解释的方法,从结构和拓扑的角度理解和优化软提示微调。
🎯 应用场景
该研究成果可应用于各种需要利用预训练语言模型进行少样本学习的任务中,例如文本分类、情感分析、命名实体识别等。通过优化软提示的结构,可以提高模型在资源受限场景下的性能,并为理解和改进软提示微调提供新的思路。
📄 摘要(原文)
Soft prompt tuning leverages continuous embeddings to capture task-specific information in large pre-trained language models (LLMs), achieving competitive performance in few-shot settings. However, soft prompts rely on high-dimensional, implicit representations and lack explicit semantics and traceable training behaviors, which limits their interpretability. To address this limitation, we propose a soft prompt tuning optimization method based on topological morphological evolution. Specifically, we employ persistent homology from topological data analysis (TDA) to quantify the structural representations of soft prompts in continuous parameter space and their training process evolution. Quantitative analysis shows that topologically stable and compact soft prompts achieve better downstream performance. Based on this empirical observation, we construct a loss function for optimizing soft prompt tuning, termed Topological Soft Prompt Loss (TSLoss). TSLoss guides the model to learn structurally stable adaptations by quantifying inter-parameter connectivity and redundancy. Extensive experiments show that training with TSLoss accelerates convergence and improves tuning performance, providing an interpretable method to understand and optimize soft prompt tuning from structural and topological perspectives.