MultiCW: A Large-Scale Balanced Benchmark Dataset for Training Robust Check-Worthiness Detection Models
作者: Martin Hyben, Sebastian Kula, Jan Cegin, Jakub Simko, Ivan Srba, Robert Moro
分类: cs.CL
发布日期: 2026-02-18
备注: 18 pages, 8 figures, 19 tables, EACL-2026
💡 一句话要点
提出MultiCW大规模多语言平衡基准数据集,用于训练鲁棒的Check-Worthiness检测模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Check-Worthiness检测 事实核查 多语言数据集 大型语言模型 Transformer模型
📋 核心要点
- 现有自动事实核查中,check-worthy声明检测的自动化支持仍然不足,限制了效率。
- 构建大规模、多语言、平衡的数据集,以促进check-worthy声明检测模型的训练和评估。
- 实验表明,微调的多语言Transformer模型优于零样本LLM,并具有良好的跨语言泛化能力。
📝 摘要(中文)
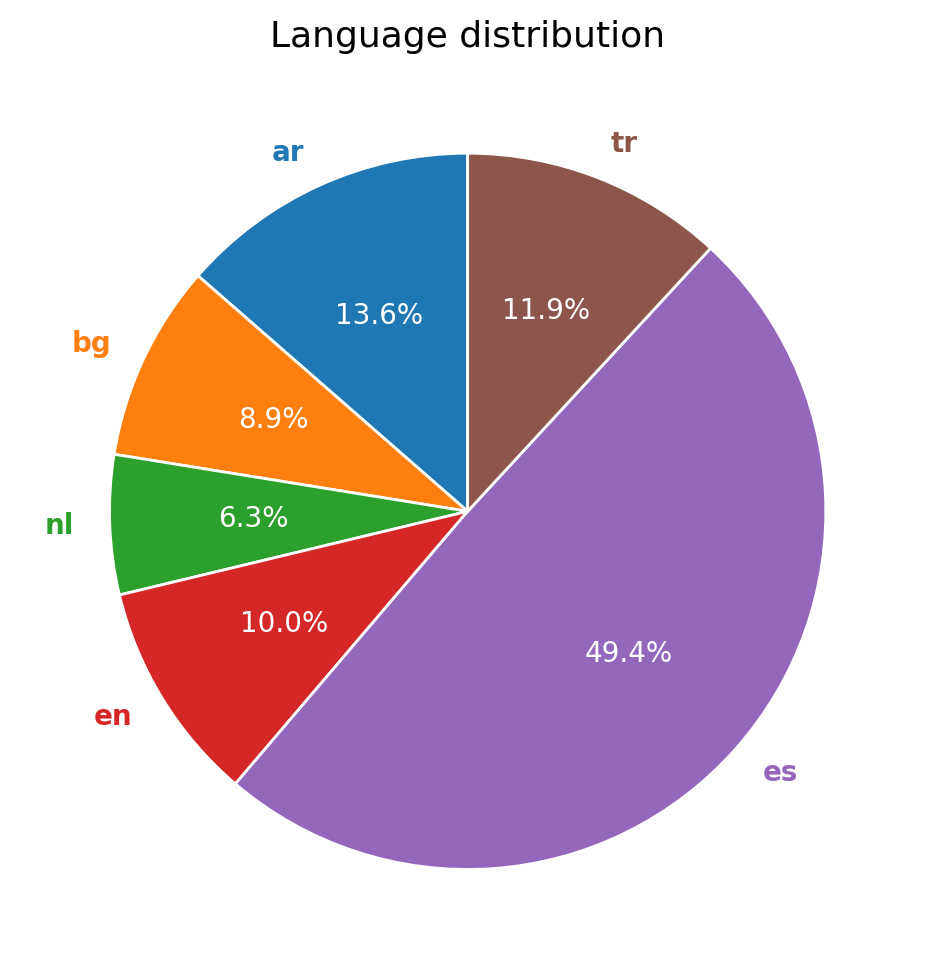
大型语言模型(LLMs)正在重塑媒体专业人士验证信息的方式,但自动支持检测check-worthy声明(事实核查过程中的关键步骤)仍然有限。我们推出了Multi-Check-Worthy(MultiCW)数据集,这是一个平衡的多语言基准,用于check-worthy声明检测,涵盖16种语言、7个主题领域和2种写作风格。它包含123,722个样本,在嘈杂(非正式)和结构化(正式)文本之间均匀分布,并在所有语言中平衡了check-worthy和非check-worthy类的表示。为了探测鲁棒性,我们还引入了一个同样平衡的、包含4种额外语言的、由27,761个样本组成的分布外评估集。为了提供基线,我们针对15个商业和开源LLM在零样本设置下,对3个常见的微调多语言transformer进行了基准测试。我们的研究结果表明,微调模型在声明分类方面始终优于零样本LLM,并在语言、领域和风格上表现出强大的分布外泛化能力。MultiCW为推进自动事实核查提供了一个严谨的多语言资源,并能够对微调模型和最先进的LLM在check-worthy声明检测任务上进行系统比较。
🔬 方法详解
问题定义:论文旨在解决check-worthy声明检测问题,即判断一个声明是否值得进行事实核查。现有方法缺乏大规模、多语言、平衡的数据集,导致模型在不同语言、领域和写作风格上的泛化能力不足。
核心思路:论文的核心思路是构建一个大规模、多语言、平衡的基准数据集MultiCW,该数据集涵盖多种语言、主题领域和写作风格,并平衡了check-worthy和非check-worthy声明的比例。通过在该数据集上训练和评估模型,可以提高模型在实际应用中的鲁棒性和泛化能力。
技术框架:MultiCW数据集的构建流程包括数据收集、标注和平衡。数据来源于多种渠道,包括新闻文章、社交媒体帖子等。标注由人工完成,标注人员根据预定义的标准判断声明是否check-worthy。为了保证数据集的平衡性,论文采用了过采样和欠采样等技术。此外,论文还提供了一个分布外评估集,用于评估模型在未见过的语言上的泛化能力。
关键创新:MultiCW数据集的关键创新在于其大规模、多语言和平衡性。与现有数据集相比,MultiCW数据集涵盖了更多的语言和主题领域,并且平衡了check-worthy和非check-worthy声明的比例。这使得MultiCW数据集能够更好地反映实际应用中的情况,并促进check-worthy声明检测模型的发展。
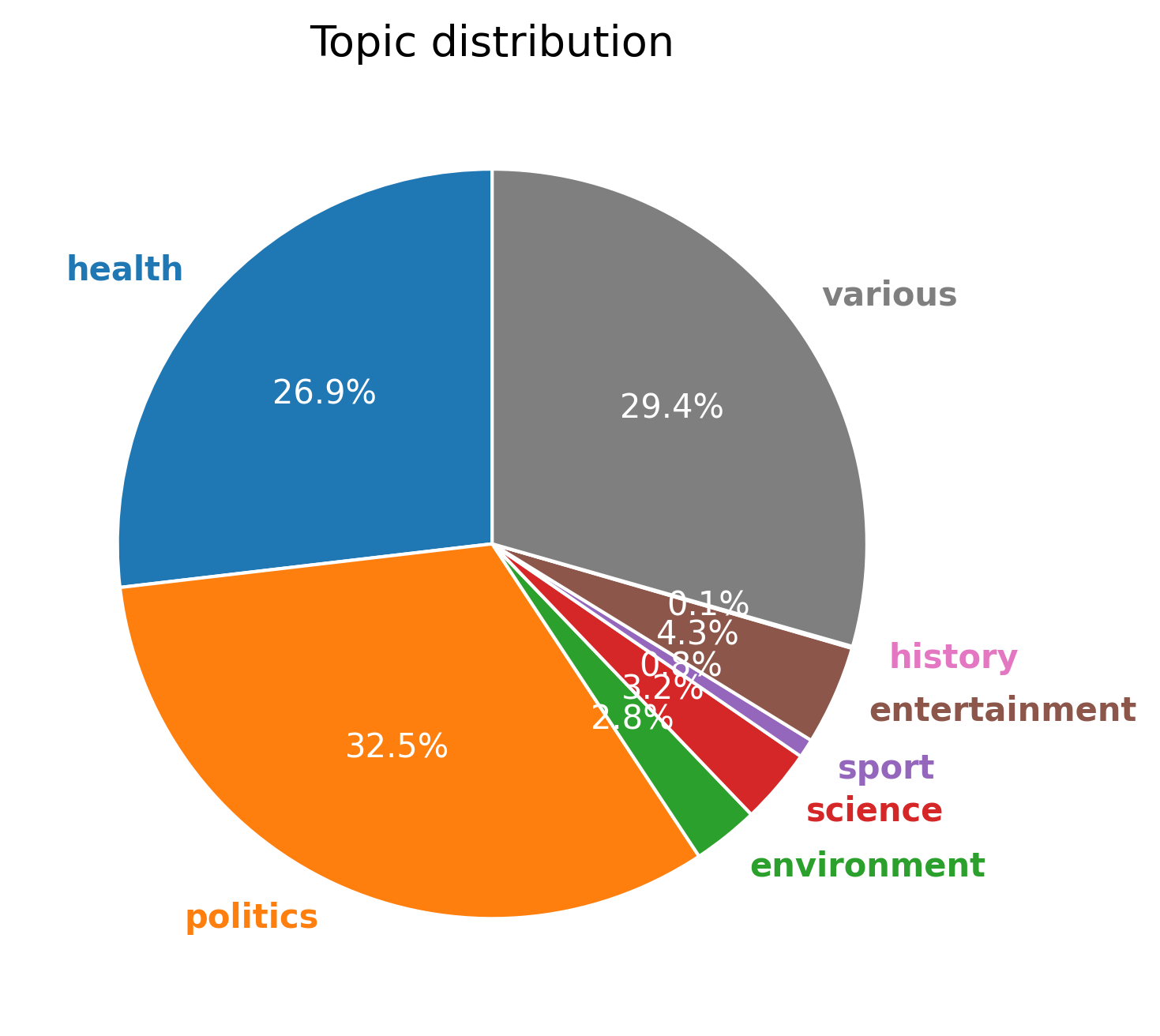
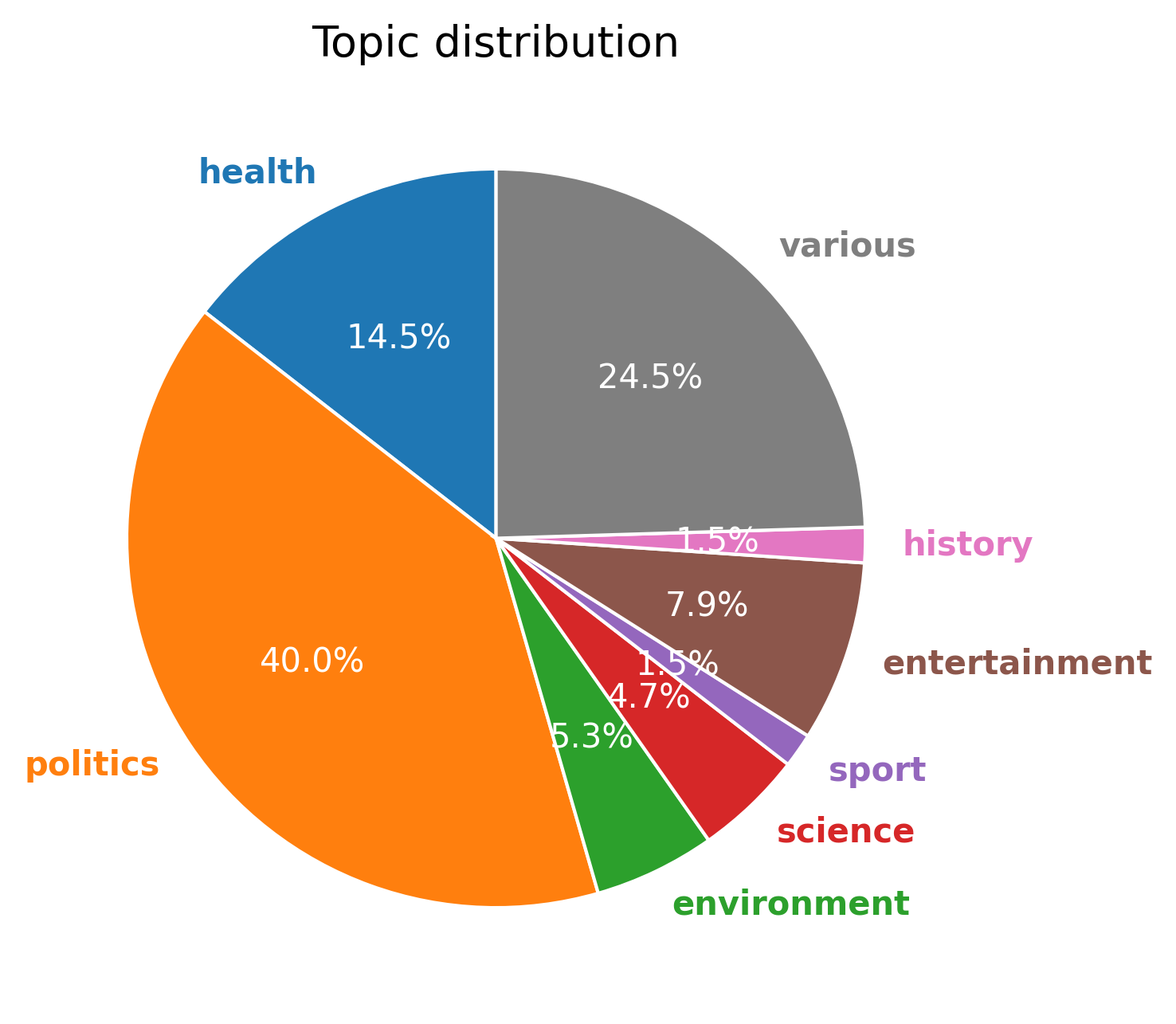
关键设计:MultiCW数据集包含16种语言,7个主题领域和2种写作风格。数据集分为训练集、验证集和测试集,其中训练集包含123,722个样本,测试集包含27,761个样本。论文还提供了3个微调的多语言Transformer模型作为基线,并与15个商业和开源LLM在零样本设置下进行了比较。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在MultiCW数据集上微调的多语言Transformer模型在check-worthy声明检测任务上优于零样本LLM。微调模型在跨语言、跨领域和跨风格的泛化能力方面表现出色,证明了MultiCW数据集的有效性和价值。具体而言,微调模型在分布外评估集上仍然保持了较高的性能。
🎯 应用场景
该研究成果可应用于自动事实核查系统,帮助媒体专业人士快速识别需要核实的声明,提高事实核查的效率和准确性。此外,该数据集也可用于训练和评估其他自然语言处理模型,例如文本分类、信息检索等,具有广泛的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) are beginning to reshape how media professionals verify information, yet automated support for detecting check-worthy claims a key step in the fact-checking process remains limited. We introduce the Multi-Check-Worthy (MultiCW) dataset, a balanced multilingual benchmark for check-worthy claim detection spanning 16 languages, 7 topical domains, and 2 writing styles. It consists of 123,722 samples, evenly distributed between noisy (informal) and structured (formal) texts, with balanced representation of check-worthy and non-check-worthy classes across all languages. To probe robustness, we also introduce an equally balanced out-of-distribution evaluation set of 27,761 samples in 4 additional languages. To provide baselines, we benchmark 3 common fine-tuned multilingual transformers against a diverse set of 15 commercial and open LLMs under zero-shot settings. Our findings show that fine-tuned models consistently outperform zero-shot LLMs on claim classification and show strong out-of-distribution generalization across languages, domains, and styles. MultiCW provides a rigorous multilingual resource for advancing automated fact-checking and enables systematic comparisons between fine-tuned models and cutting-edge LLMs on the check-worthy claim detection task.