Balancing Faithfulness and Performance in Reasoning via Multi-Listener Soft Execution
作者: Nithin Sivakumaran, Shoubin Yu, Hyunji Lee, Yue Zhang, Ali Payani, Mohit Bansal, Elias Stengel-Eskin
分类: cs.CL, cs.AI
发布日期: 2026-02-18
备注: Code: https://github.com/nsivaku/remul
💡 一句话要点
提出REMUL,通过多方监听软执行提升LLM推理的忠实性和性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 链式思考 大型语言模型 推理忠实性 强化学习 多方参与 可解释性 知识推理
📋 核心要点
- 现有CoT推理难以保证大型语言模型推理过程的忠实性,影响了解释能力,且优化忠实性常导致性能下降。
- REMUL通过多方强化学习,让speaker生成listener易于理解的推理过程,从而提高推理的忠实性。
- 实验表明,REMUL在多个推理基准上显著提升了忠实性指标和准确性,并生成更短更直接的推理链。
📝 摘要(中文)
链式思考(CoT)推理有时不能忠实地反映大型语言模型(LLM)的真实计算过程,从而降低了其在解释LLM如何得出答案方面的效用。此外,在推理中优化忠实性和可解释性通常会降低任务性能。为了解决这种权衡并提高CoT的忠实性,我们提出了一种基于多方强化学习的方法,即多监听器推理执行(REMUL)。REMUL建立在这样的假设之上:其他方可以遵循的推理轨迹将更加忠实。一个speaker模型生成一个推理轨迹,该轨迹被截断并传递给一个listener模型池,这些模型“执行”该轨迹,从而将轨迹延续到答案。speaker因产生对listener清晰的推理而获得奖励,并通过掩码监督微调进行额外的正确性正则化,以抵消忠实性和性能之间的权衡。在多个推理基准(BIG-Bench Extra Hard、MuSR、ZebraLogicBench和FOLIO)上,REMUL始终且大幅度地提高了三个忠实性指标——提示归因、提前回答曲线下面积(AOC)和错误注入AOC——同时也提高了准确性。我们的分析发现,这些收益在训练领域中具有鲁棒性,可以转化为可读性收益,并且与更短、更直接的CoT相关。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在链式思考(CoT)推理中,推理过程不够忠实的问题。现有方法在追求推理的忠实性和可解释性时,往往会牺牲任务的性能,即准确率下降。因此,如何在保证甚至提升性能的同时,提高推理过程的忠实性,是本文要解决的核心问题。
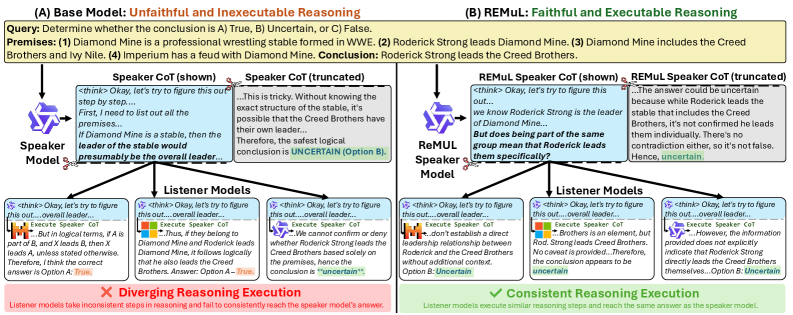
核心思路:论文的核心思路是,如果生成的推理过程能够被多个“listener”理解和执行,那么这个推理过程就更可能是忠实的。类似于代码评审,如果一段代码能被多人理解,那么这段代码出错的可能性就越小。因此,论文设计了一个多方参与的强化学习框架,鼓励speaker生成清晰易懂的推理过程。
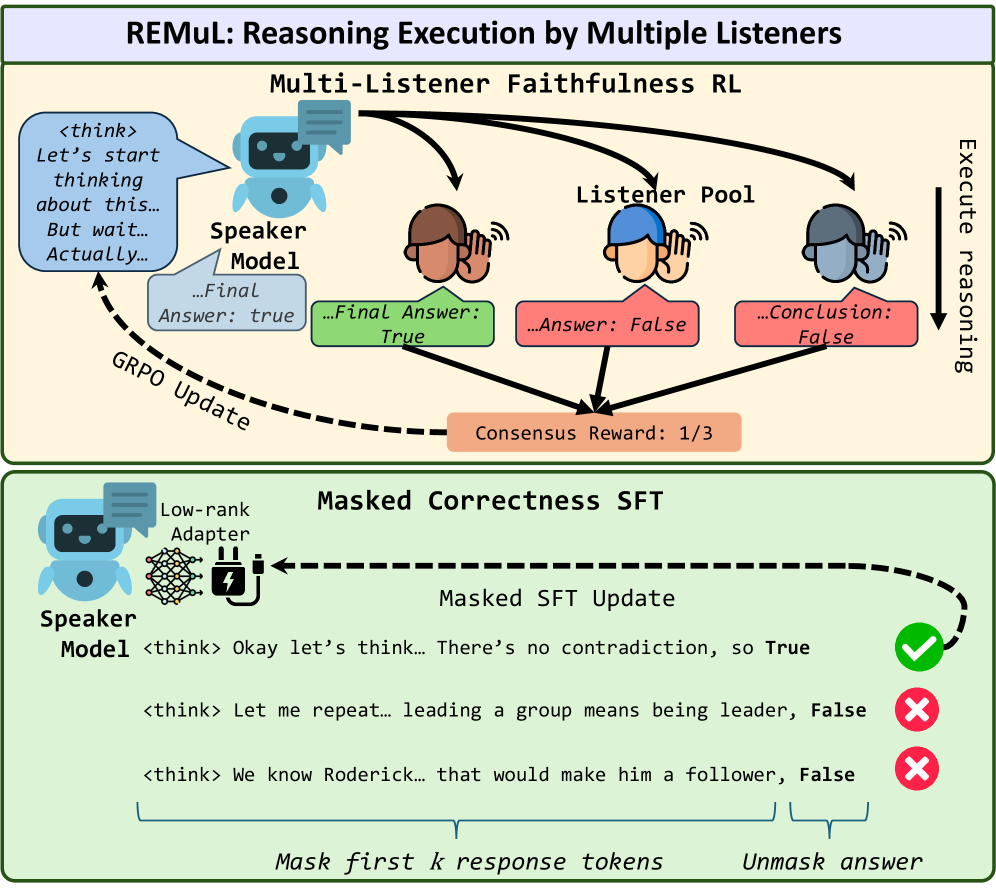
技术框架:REMUL框架包含一个speaker模型和多个listener模型。speaker模型负责生成推理轨迹,该轨迹会被截断并传递给listener模型。listener模型“执行”接收到的部分轨迹,并尝试继续推理直至得到最终答案。整个过程通过强化学习进行优化,speaker的目标是生成listener能够理解的推理过程。
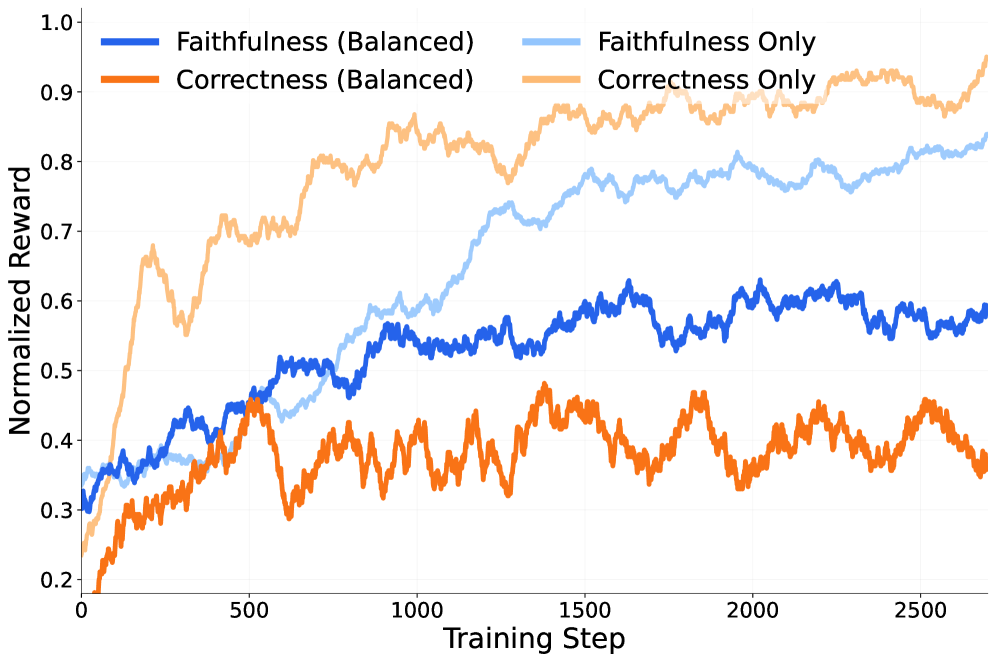
关键创新:REMUL的关键创新在于引入了多方“listener”的概念,并利用强化学习来训练speaker生成对listener友好的推理过程。与传统的CoT方法相比,REMUL不仅仅关注最终答案的正确性,更关注推理过程的可理解性和可追溯性。此外,论文还使用了掩码监督微调(masked supervised finetuning)来平衡忠实性和性能之间的权衡。
关键设计:在训练过程中,speaker会根据listener的反馈获得奖励。奖励函数的设计至关重要,它需要鼓励speaker生成listener能够理解的推理过程,同时也要保证最终答案的正确性。此外,listener模型的选择和数量也会影响最终的性能。论文使用了掩码监督微调来正则化speaker的训练,防止其过度优化忠实性而牺牲了准确率。具体的参数设置和网络结构细节在论文中有更详细的描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,REMUL在BIG-Bench Extra Hard、MuSR、ZebraLogicBench和FOLIO等多个推理基准上,显著提高了提示归因、提前回答曲线下面积(AOC)和错误注入AOC等忠实性指标,同时也提高了准确性。例如,在某些基准测试中,REMUL的准确率提升超过5%,同时忠实性指标也得到了显著改善。
🎯 应用场景
REMUL方法可以应用于需要高可信度和可解释性的人工智能系统中,例如医疗诊断、金融风控等领域。通过提高LLM推理过程的忠实性,可以增强人们对AI决策的信任,并促进AI在关键领域的应用。此外,该方法还可以用于改进LLM的教学和调试,帮助开发者更好地理解和控制LLM的行为。
📄 摘要(原文)
Chain-of-thought (CoT) reasoning sometimes fails to faithfully reflect the true computation of a large language model (LLM), hampering its utility in explaining how LLMs arrive at their answers. Moreover, optimizing for faithfulness and interpretability in reasoning often degrades task performance. To address this tradeoff and improve CoT faithfulness, we propose Reasoning Execution by Multiple Listeners (REMUL), a multi-party reinforcement learning approach. REMUL builds on the hypothesis that reasoning traces which other parties can follow will be more faithful. A speaker model generates a reasoning trace, which is truncated and passed to a pool of listener models who "execute" the trace, continuing the trace to an answer. Speakers are rewarded for producing reasoning that is clear to listeners, with additional correctness regularization via masked supervised finetuning to counter the tradeoff between faithfulness and performance. On multiple reasoning benchmarks (BIG-Bench Extra Hard, MuSR, ZebraLogicBench, and FOLIO), REMUL consistently and substantially improves three measures of faithfulness -- hint attribution, early answering area over the curve (AOC), and mistake injection AOC -- while also improving accuracy. Our analysis finds that these gains are robust across training domains, translate to legibility gains, and are associated with shorter and more direct CoTs.