ViTaB-A: Evaluating Multimodal Large Language Models on Visual Table Attribution
作者: Yahia Alqurnawi, Preetom Biswas, Anmol Rao, Tejas Anvekar, Chitta Baral, Vivek Gupta
分类: cs.CL
发布日期: 2026-02-17
💡 一句话要点
ViTaB-A:评估多模态大语言模型在视觉表格归因任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 表格归因 结构化数据 可解释性 基准数据集
📋 核心要点
- 现有的多模态大语言模型在结构化数据问答中缺乏可信的证据归因能力,限制了其在需要透明性的场景应用。
- 论文核心在于评估mLLMs在不同表格格式和提示策略下,对答案来源进行精准定位(行/列)的能力。
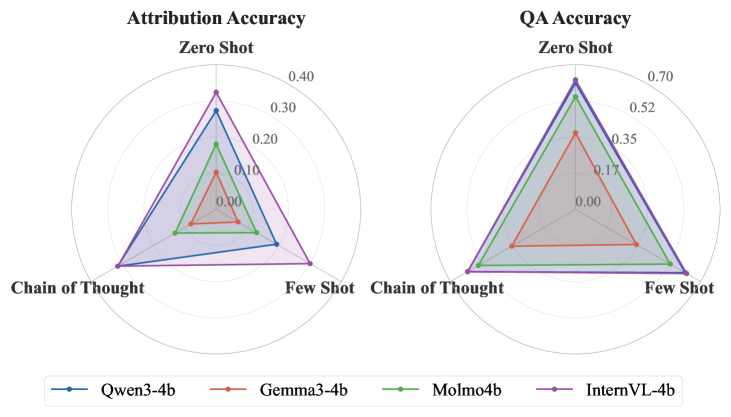
- 实验结果表明,现有mLLMs在表格归因任务上表现不佳,尤其是在JSON格式和列归因方面,性能接近随机。
📝 摘要(中文)
多模态大语言模型(mLLMs)常被用于回答结构化数据中的问题,例如Markdown、JSON和图像格式的表格。虽然这些模型通常能给出正确的答案,但用户也需要知道这些答案的来源。本文研究了结构化数据的归因/引用问题,即模型指出支持答案的具体行和列的能力。我们评估了多个mLLMs在不同表格格式和提示策略下的表现。结果表明,问题回答和证据归因之间存在明显差距。尽管问题回答的准确率尚可,但归因准确率却低得多,对于JSON输入,所有模型的归因准确率都接近随机水平。我们还发现,模型在引用行方面比引用列更可靠,并且在处理文本格式时比处理图像格式更困难。最后,我们观察到不同模型家族之间存在显著差异。总的来说,我们的研究结果表明,当前mLLMs在为结构化数据提供细粒度、可信的归因方面是不可靠的,这限制了它们在需要透明性和可追溯性的应用中的使用。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(mLLMs)在结构化数据(如表格)问答任务中,缺乏可靠的证据归因能力的问题。现有方法虽然可以给出答案,但无法准确指出答案来源于表格中的哪些具体行和列,这导致用户难以信任模型的输出,限制了其在需要透明性和可追溯性的场景中的应用。
核心思路:论文的核心思路是通过构建一个专门用于评估表格归因能力的基准数据集(ViTaB-A),并设计相应的评估指标,来系统性地评估现有mLLMs在不同表格格式和提示策略下的归因性能。通过分析实验结果,揭示mLLMs在表格归因方面的优势和不足,为未来的模型改进提供指导。
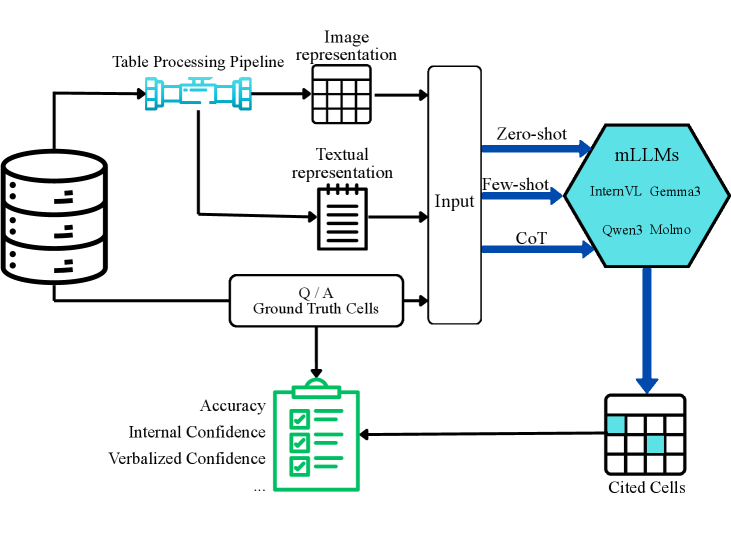
技术框架:论文主要包含以下几个关键部分:1) 构建ViTaB-A数据集,该数据集包含不同格式(Markdown, JSON, Image)的表格和相应的问答对,每个问答对都标注了答案所对应的表格行和列;2) 选择多个代表性的mLLMs进行评估,包括不同模型家族和规模的模型;3) 设计不同的提示策略,以考察提示方式对归因性能的影响;4) 定义评估指标,用于衡量模型在行归因和列归因方面的准确率;5) 分析实验结果,比较不同模型和提示策略的性能,并总结mLLMs在表格归因方面的优势和不足。
关键创新:论文的主要创新在于:1) 提出了一个专门用于评估mLLMs在表格归因任务上的基准数据集ViTaB-A,填补了该领域缺乏标准评估数据集的空白;2) 系统性地评估了多个mLLMs在不同表格格式和提示策略下的归因性能,揭示了现有模型在该任务上的局限性;3) 分析了模型在行归因和列归因方面的差异,以及不同表格格式对归因性能的影响,为未来的模型改进提供了有价值的 insights。
关键设计:论文的关键设计包括:1) ViTaB-A数据集的构建,需要保证数据的多样性和标注的准确性;2) 提示策略的设计,需要考虑不同提示方式对模型性能的影响;3) 评估指标的选择,需要能够准确反映模型在行归因和列归因方面的能力。论文没有涉及具体的网络结构或损失函数的设计,而是侧重于对现有模型的评估和分析。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有mLLMs在表格归因任务上表现不佳,尤其是在JSON格式的表格和列归因方面,性能接近随机水平。模型在引用行方面比引用列更可靠,并且在处理文本格式时比处理图像格式更困难。不同模型家族之间存在显著差异,表明模型架构和训练数据对归因性能有重要影响。
🎯 应用场景
该研究成果可应用于需要透明性和可追溯性的领域,例如金融分析、医疗诊断和法律咨询。通过提高mLLMs在结构化数据问答中的证据归因能力,可以增强用户对模型输出的信任度,并促进其在这些领域的广泛应用。未来的研究可以进一步探索如何利用该研究结果来改进mLLMs的归因能力,例如通过引入专门的归因模块或采用更有效的训练方法。
📄 摘要(原文)
Multimodal Large Language Models (mLLMs) are often used to answer questions in structured data such as tables in Markdown, JSON, and images. While these models can often give correct answers, users also need to know where those answers come from. In this work, we study structured data attribution/citation, which is the ability of the models to point to the specific rows and columns that support an answer. We evaluate several mLLMs across different table formats and prompting strategies. Our results show a clear gap between question answering and evidence attribution. Although question answering accuracy remains moderate, attribution accuracy is much lower, near random for JSON inputs, across all models. We also find that models are more reliable at citing rows than columns, and struggle more with textual formats than images. Finally, we observe notable differences across model families. Overall, our findings show that current mLLMs are unreliable at providing fine-grained, trustworthy attribution for structured data, which limits their usage in applications requiring transparency and traceability.