ChartEditBench: Evaluating Grounded Multi-Turn Chart Editing in Multimodal Language Models
作者: Manav Nitin Kapadnis, Lawanya Baghel, Atharva Naik, Carolyn Rosé
分类: cs.CL, cs.AI
发布日期: 2026-02-17
备注: 16 pages, 13 figures including Supplementary Material
💡 一句话要点
ChartEditBench:评估多模态语言模型中基于视觉的交互式图表编辑能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图表编辑 基准测试 人机交互 可视化 大型语言模型 上下文学习
📋 核心要点
- 现有MLLM在交互式图表编辑中,难以维持多轮对话的上下文一致性,导致编辑效果不佳。
- 提出ChartEditBench基准测试,包含多轮图表编辑任务,并结合执行、视觉和代码验证进行评估。
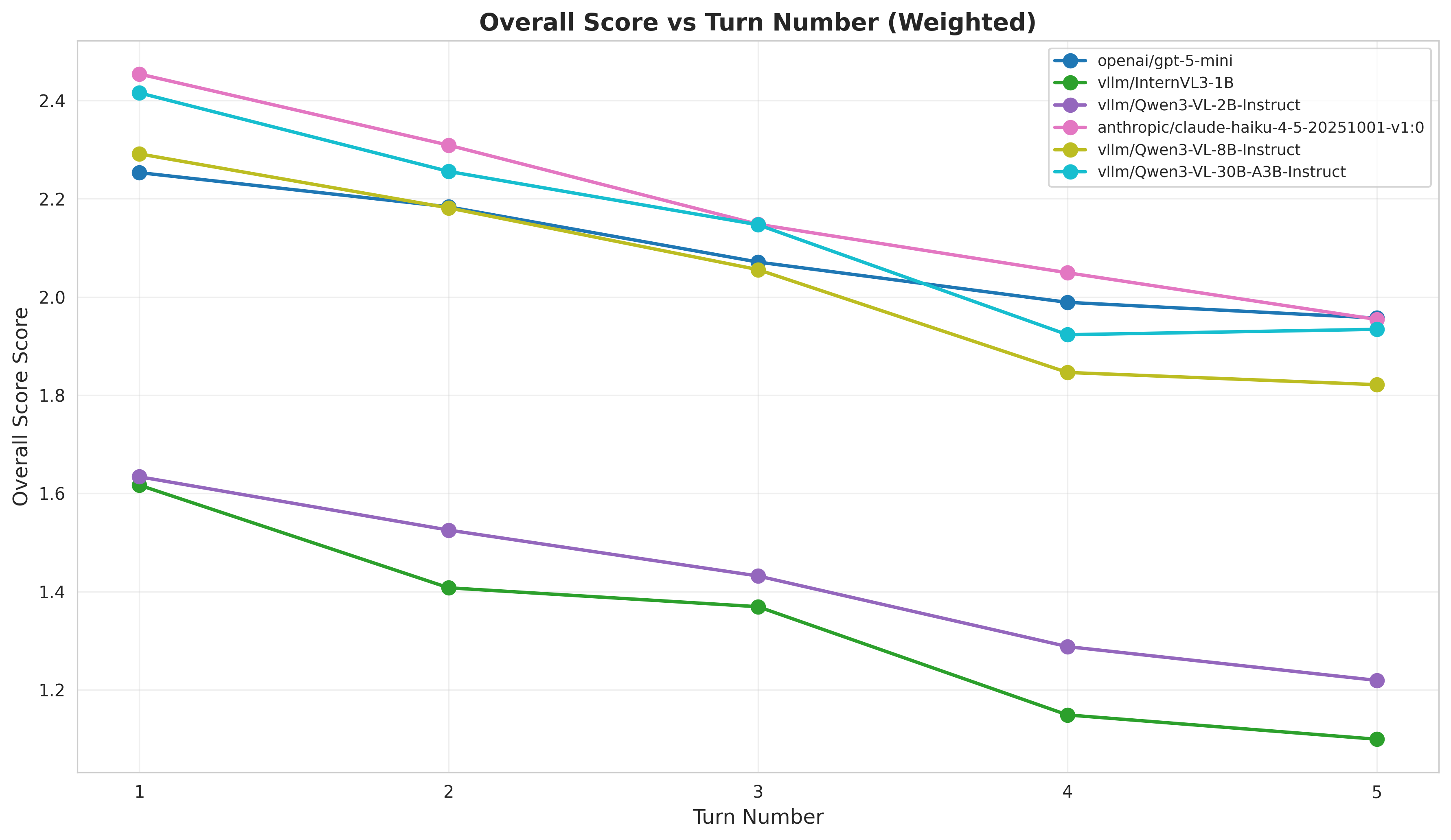
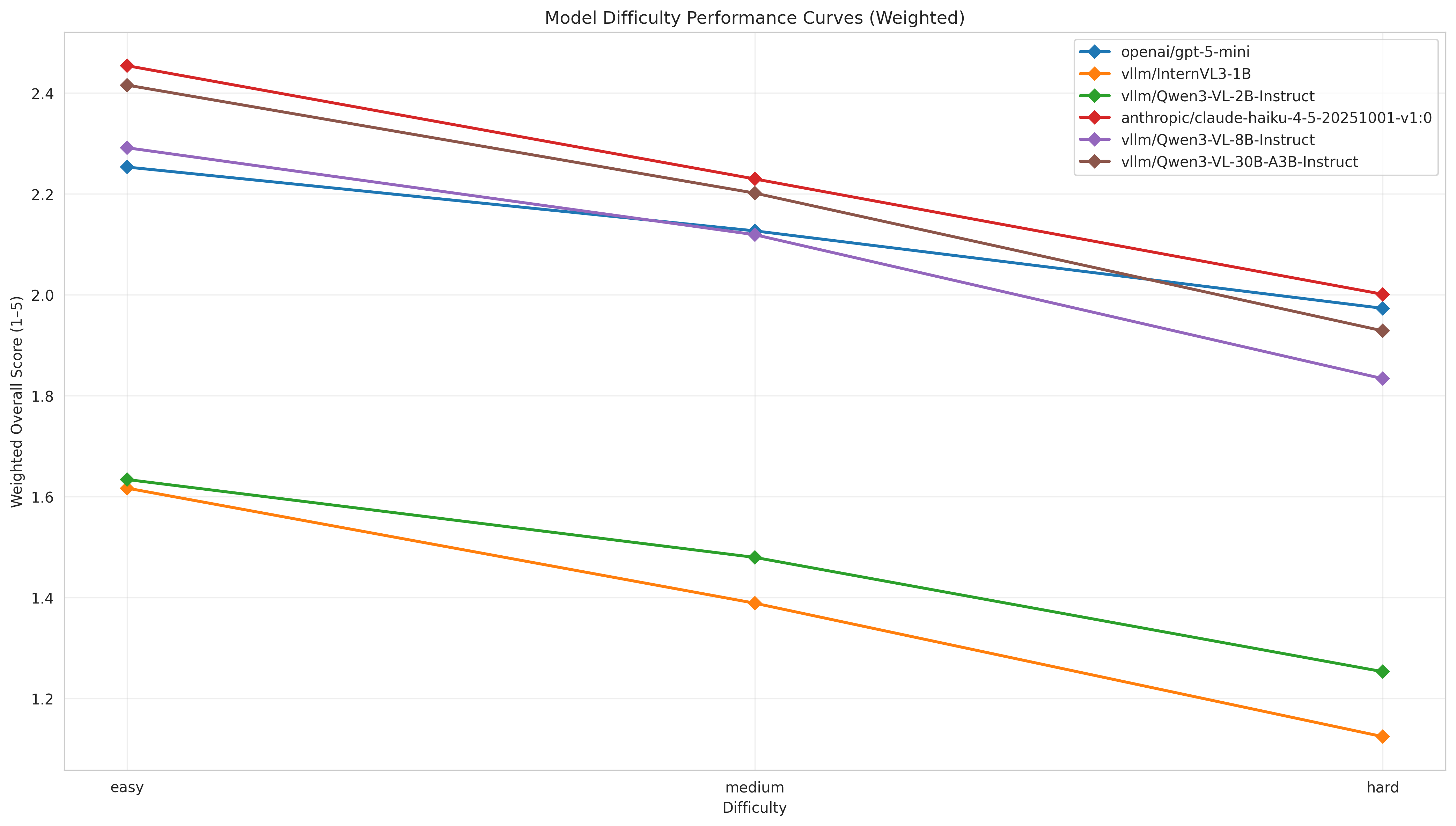
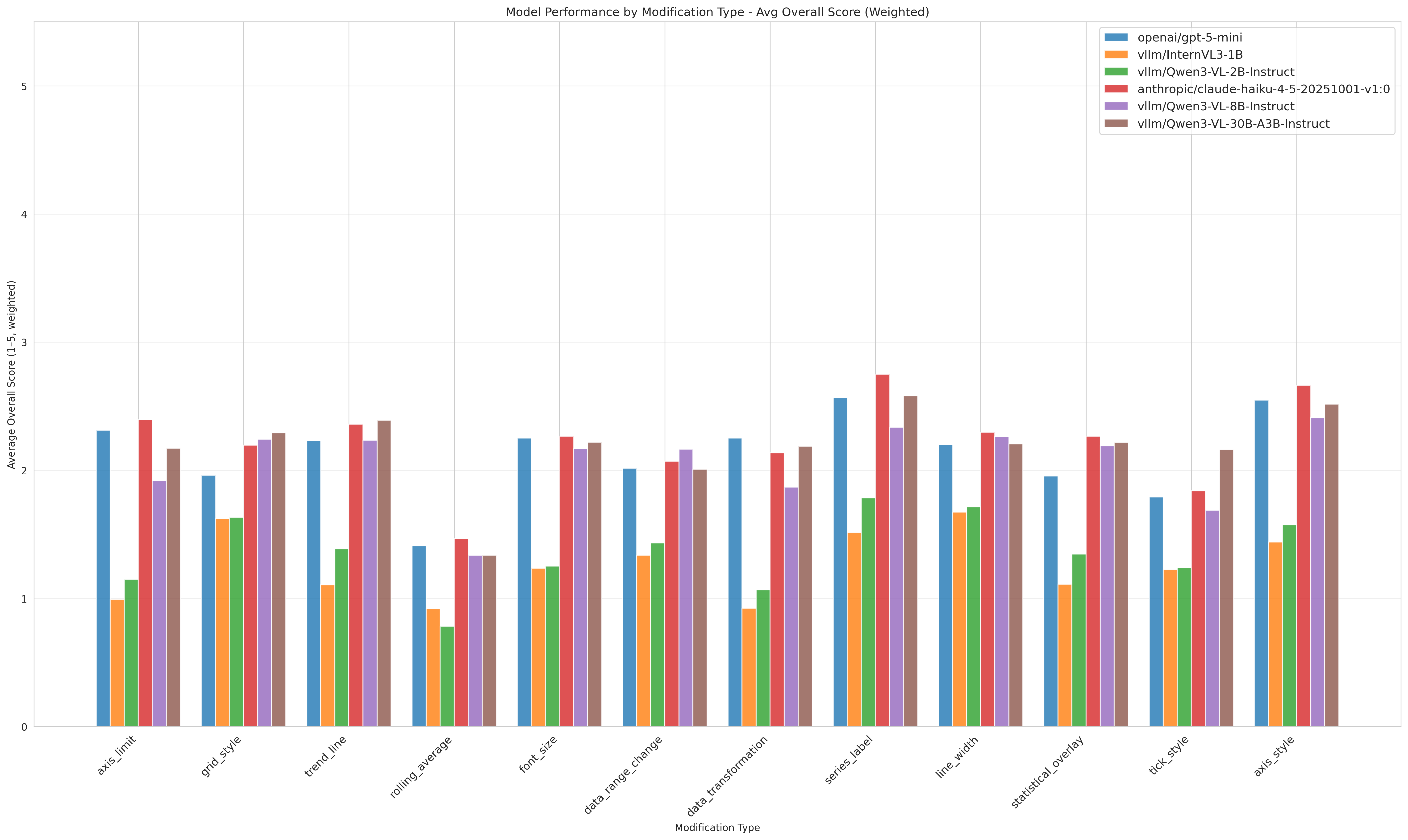
- 实验表明,现有MLLM在多轮编辑中性能显著下降,尤其是在数据驱动的图表修改方面。
📝 摘要(中文)
多模态大型语言模型(MLLM)在单轮图表生成方面表现出色,但它们在支持真实世界探索性数据分析方面的能力仍未得到充分探索。在实践中,用户通过多轮交互迭代地改进可视化效果,这需要保持共同基础、跟踪先前的编辑并适应不断变化的偏好。我们引入了ChartEditBench,这是一个用于通过代码进行增量式、视觉基础图表编辑的基准,包含5,000个难度可控的修改链和一个经过严格人工验证的子集。与先前的单次基准不同,ChartEditBench评估了持续的、上下文感知的编辑。我们进一步提出了一个强大的评估框架,通过整合基于执行的保真度检查、像素级视觉相似性和逻辑代码验证,来缓解LLM-as-a-Judge指标的局限性。对最先进的MLLM的实验表明,由于错误累积和共享上下文的崩溃,多轮设置中的性能显着下降,在样式编辑方面表现出色,但在以数据为中心的转换方面经常出现执行失败。ChartEditBench建立了一个具有挑战性的测试平台,用于基于视觉的、意图感知的多模态编程。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在多轮交互式图表编辑任务中的性能评估问题。现有方法主要集中在单轮图表生成,忽略了真实世界数据分析中用户迭代修改图表的场景。现有评估方法,如LLM-as-a-Judge,存在主观性和不准确性,难以全面评估MLLM在多轮编辑中的能力。
核心思路:论文的核心思路是构建一个更贴近实际应用场景的多轮图表编辑基准测试,并设计一个更客观、更全面的评估框架。通过模拟用户逐步修改图表的过程,考察MLLM在保持上下文一致性、理解用户意图和执行复杂编辑操作方面的能力。
技术框架:ChartEditBench包含5000个难度可控的修改链,每个链代表一个图表编辑的迭代过程。评估框架包含三个主要组成部分:1) 基于执行的保真度检查,验证生成的代码是否能够正确修改图表;2) 像素级视觉相似性,衡量修改后的图表与预期结果的视觉差异;3) 逻辑代码验证,检查生成的代码是否符合语法和逻辑规则。
关键创新:该论文的关键创新在于:1) 提出了一个多轮交互式图表编辑基准测试,更贴近实际应用场景;2) 设计了一个综合性的评估框架,结合了执行、视觉和代码验证,提高了评估的客观性和准确性;3) 揭示了现有MLLM在多轮编辑任务中的局限性,为未来的研究方向提供了指导。
关键设计:ChartEditBench中的修改链涵盖了各种类型的图表编辑操作,包括样式修改、数据过滤、轴标签修改等。评估框架中的视觉相似性度量采用像素级差异,并考虑了图表元素的空间布局。代码验证规则包括语法检查、类型检查和逻辑一致性检查。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有最先进的MLLM在ChartEditBench上的多轮编辑性能显著低于单轮生成性能,尤其是在数据驱动的图表修改方面。例如,在某些修改链中,MLLM的执行成功率仅为30%左右。这表明现有MLLM在处理复杂的多轮交互式任务时,仍然存在很大的提升空间。
🎯 应用场景
该研究成果可应用于智能数据分析、自动化报告生成、辅助可视化设计等领域。通过提升MLLM在多轮交互式图表编辑方面的能力,可以帮助用户更高效地探索数据、发现洞见,并生成更具表现力的可视化报告。未来,该研究可以扩展到其他类型的可视化任务,如地图生成、网络图分析等。
📄 摘要(原文)
While Multimodal Large Language Models (MLLMs) perform strongly on single-turn chart generation, their ability to support real-world exploratory data analysis remains underexplored. In practice, users iteratively refine visualizations through multi-turn interactions that require maintaining common ground, tracking prior edits, and adapting to evolving preferences. We introduce ChartEditBench, a benchmark for incremental, visually grounded chart editing via code, comprising 5,000 difficulty-controlled modification chains and a rigorously human-verified subset. Unlike prior one-shot benchmarks, ChartEditBench evaluates sustained, context-aware editing. We further propose a robust evaluation framework that mitigates limitations of LLM-as-a-Judge metrics by integrating execution-based fidelity checks, pixel-level visual similarity, and logical code verification. Experiments with state-of-the-art MLLMs reveal substantial degradation in multi-turn settings due to error accumulation and breakdowns in shared context, with strong performance on stylistic edits but frequent execution failures on data-centric transformations. ChartEditBench, establishes a challenging testbed for grounded, intent-aware multimodal programming.