A Content-Based Framework for Cybersecurity Refusal Decisions in Large Language Models
作者: Meirav Segal, Noa Linder, Omer Antverg, Gil Gekker, Tomer Fichman, Omri Bodenheimer, Edan Maor, Omer Nevo
分类: cs.CL, cs.AI, cs.CR
发布日期: 2026-02-17
💡 一句话要点
提出基于内容的网络安全拒绝决策框架,提升LLM防御能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 网络安全 拒绝策略 内容分析 攻防权衡
📋 核心要点
- 现有网络安全拒绝方法依赖于宽泛的主题禁令或攻击分类,导致决策不一致,限制防御能力。
- 论文提出基于内容的框架,显式建模攻防风险收益权衡,而非仅依赖意图或攻击分类。
- 该框架通过五个维度刻画请求,解决了现有模型行为的不一致性,并支持构建可调的风险感知策略。
📝 摘要(中文)
大型语言模型(LLM)及其驱动的智能体正日益应用于网络安全任务,这些任务本质上具有双重用途。现有的拒绝方法,包括学术政策框架和商业部署系统,通常依赖于广泛的基于主题的禁令或以攻击为中心的分类。这可能导致决策不一致,过度限制合法的防御者,并在混淆或请求分割下表现脆弱。我们认为,有效的拒绝需要明确地对攻击风险和防御收益之间的权衡进行建模,而不是仅仅依赖于意图或攻击分类。在本文中,我们介绍了一个基于内容的框架,用于设计和审计网络拒绝策略,该框架明确了攻防之间的权衡。该框架从五个维度描述请求:攻击行为贡献、攻击风险、技术复杂性、防御收益以及合法用户的预期频率,这些维度都基于请求的技术实质,而不是声明的意图。我们证明,这种基于内容的方法解决了当前前沿模型行为中的不一致性,并允许组织构建可调整的、具有风险意识的拒绝策略。
🔬 方法详解
问题定义:现有的大型语言模型在网络安全领域的应用面临双重用途的挑战。现有的拒绝机制,如基于主题的封禁或攻击分类,存在决策不一致、过度限制合法防御行为以及容易被混淆攻击绕过等问题。因此,如何设计一种更有效、更细粒度的拒绝策略,以平衡攻击风险和防御收益,是亟待解决的问题。
核心思路:论文的核心思路是转变拒绝决策的依据,从关注请求的意图或所属主题,转向关注请求内容的实质。通过分析请求的技术细节,评估其潜在的攻击风险和防御价值,从而做出更明智的拒绝决策。这种基于内容的分析方法能够更准确地识别恶意请求,同时避免误判合法的防御行为。
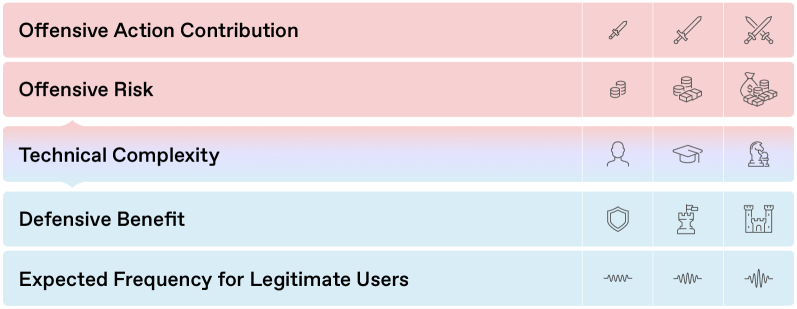
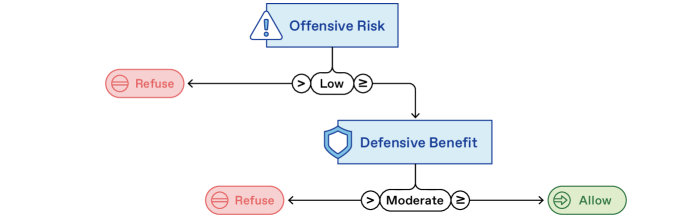
技术框架:该框架包含五个关键维度来描述网络安全相关的请求:1) 攻击行为贡献:请求对潜在攻击行为的贡献程度;2) 攻击风险:请求被用于恶意目的的风险;3) 技术复杂性:执行请求所需的技术难度;4) 防御收益:请求对防御方带来的潜在好处;5) 合法用户预期频率:合法用户提出类似请求的频率。通过对这五个维度进行评估,可以更全面地了解请求的性质,并做出更合理的拒绝决策。
关键创新:该论文最重要的创新在于提出了基于内容的拒绝决策框架,该框架不再依赖于对请求意图的推断,而是直接分析请求的技术内容,从而更准确地评估其潜在的风险和收益。这种方法能够有效解决现有方法中存在的决策不一致和过度限制等问题。
关键设计:框架的关键设计在于五个维度的选择和评估方法。每个维度都需要根据具体的应用场景进行定义和量化。例如,攻击风险可以通过分析请求中涉及的漏洞类型、攻击技术等来评估。防御收益可以通过分析请求对安全分析、漏洞修复等方面的帮助来评估。此外,框架还需要设计合理的策略,根据五个维度的评估结果来做出最终的拒绝决策。这些策略可以根据不同的风险偏好进行调整。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,基于内容的框架能够有效解决现有模型行为中的不一致性,并允许组织构建可调整的、具有风险意识的拒绝策略。具体性能数据和对比基线在摘要中未明确给出,但强调了该方法在解决现有模型缺陷方面的有效性。
🎯 应用场景
该研究成果可应用于各种使用LLM进行网络安全任务的场景,例如漏洞分析、恶意代码检测、安全策略生成等。通过采用该框架,可以提高LLM在网络安全领域的安全性和可靠性,降低被恶意利用的风险,并为安全从业者提供更有效的工具。
📄 摘要(原文)
Large language models and LLM-based agents are increasingly used for cybersecurity tasks that are inherently dual-use. Existing approaches to refusal, spanning academic policy frameworks and commercially deployed systems, often rely on broad topic-based bans or offensive-focused taxonomies. As a result, they can yield inconsistent decisions, over-restrict legitimate defenders, and behave brittlely under obfuscation or request segmentation. We argue that effective refusal requires explicitly modeling the trade-off between offensive risk and defensive benefit, rather than relying solely on intent or offensive classification. In this paper, we introduce a content-based framework for designing and auditing cyber refusal policies that makes offense-defense tradeoffs explicit. The framework characterizes requests along five dimensions: Offensive Action Contribution, Offensive Risk, Technical Complexity, Defensive Benefit, and Expected Frequency for Legitimate Users, grounded in the technical substance of the request rather than stated intent. We demonstrate that this content-grounded approach resolves inconsistencies in current frontier model behavior and allows organizations to construct tunable, risk-aware refusal policies.