STAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens
作者: Shiqi Liu, Zeyu He, Guojian Zhan, Letian Tao, Zhilong Zheng, Jiang Wu, Yinuo Wang, Yang Guan, Kehua Sheng, Bo Zhang, Keqiang Li, Jingliang Duan, Shengbo Eben Li
分类: cs.CL, cs.AI
发布日期: 2026-02-17
💡 一句话要点
STAPO:通过抑制罕见虚假token稳定LLM强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 策略优化 虚假token 训练稳定性
📋 核心要点
- 现有LLM强化学习微调依赖启发式方法,但存在后期性能崩溃和训练不稳定的问题。
- STAPO通过识别并抑制对推理贡献小但梯度影响大的“虚假token”,稳定训练过程。
- 实验表明,STAPO在多个数学推理基准上显著提升了性能,并提高了熵稳定性。
📝 摘要(中文)
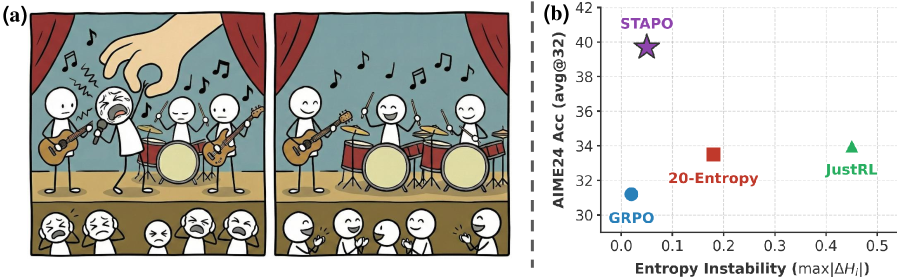
强化学习(RL)显著提升了大型语言模型(LLM)的推理能力,但现有的RL微调方法严重依赖于启发式技术,如熵正则化和重加权,以维持训练稳定性。然而,这些方法在实践中经常出现后期性能崩溃,导致推理质量下降和训练不稳定。我们推导出RL中token级别策略梯度的幅度与token概率和局部策略熵负相关。基于此,我们证明训练不稳定是由一小部分token(约0.01%)驱动的,我们称之为“虚假token”。当这些token出现在正确响应中时,它们对推理结果的贡献很小,但会继承完整的序列级别奖励,从而导致异常放大的梯度更新。受此启发,我们提出了用于大规模模型精炼的虚假token感知策略优化(STAPO),它选择性地屏蔽这些更新,并对有效token上的损失进行重新归一化。在使用Qwen 1.7B、8B和14B基础模型进行的六个数学推理基准测试中,STAPO始终表现出卓越的熵稳定性,并且相比GRPO、20-Entropy和JustRL,平均性能提升了7.13%。
🔬 方法详解
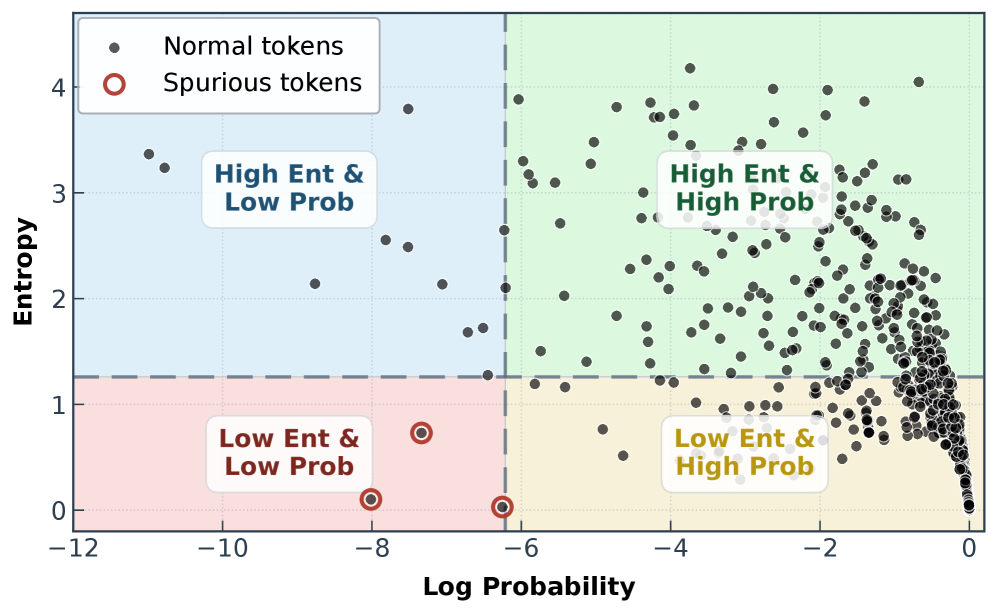
问题定义:现有基于强化学习的LLM微调方法,为了保证训练的稳定性,通常会采用熵正则化、reward reweighting等启发式方法。然而,这些方法仍然无法避免训练后期出现的性能崩塌问题,导致推理质量下降和训练不稳定。根本原因在于,现有方法无法有效区分对推理结果贡献小的token和贡献大的token,导致梯度更新方向出现偏差。
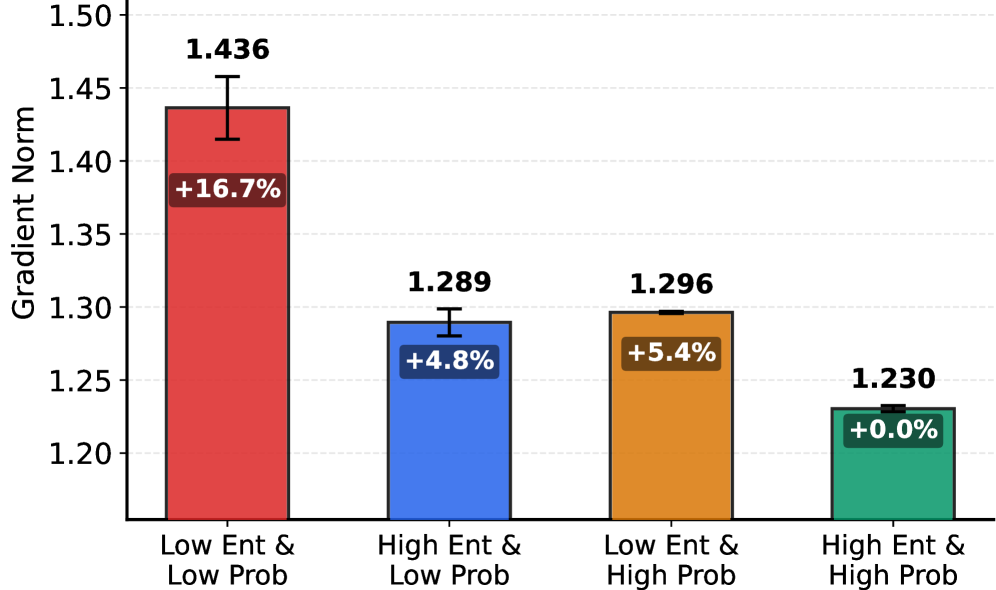
核心思路:论文的核心思路是识别并抑制那些对推理结果贡献小,但由于序列奖励机制而获得较大梯度更新的“虚假token”。通过选择性地屏蔽这些token的梯度更新,并对剩余有效token的损失进行重新归一化,从而稳定训练过程,避免性能崩塌。
技术框架:STAPO (Spurious-Token-Aware Policy Optimization) 的整体框架是在标准的强化学习流程上进行改进。主要包含以下几个步骤:1) 使用LLM生成回复序列;2) 根据环境反馈计算序列级别的奖励;3) 识别回复序列中的“虚假token”;4) 屏蔽“虚假token”的梯度更新;5) 对剩余有效token的损失进行重新归一化,并进行策略优化。
关键创新:STAPO最重要的技术创新点在于提出了“虚假token”的概念,并设计了相应的识别和抑制机制。与现有方法不同,STAPO不是简单地采用全局的熵正则化或reward reweighting,而是针对性地处理那些导致训练不稳定的token,从而更有效地稳定训练过程。
关键设计:STAPO的关键设计包括:1) “虚假token”的识别方法:论文通过分析token概率和局部策略熵来识别“虚假token”,即那些概率低且局部策略熵低的token;2) 梯度屏蔽机制:对于识别出的“虚假token”,STAPO会将其梯度置为零,从而避免其对策略更新产生负面影响;3) 损失函数重归一化:在屏蔽“虚假token”的梯度后,STAPO会对剩余有效token的损失进行重新归一化,以保证策略更新的有效性。
🖼️ 关键图片
📊 实验亮点
在Qwen 1.7B、8B和14B模型上,STAPO在六个数学推理基准测试中始终优于GRPO、20-Entropy和JustRL等基线方法,平均性能提升高达7.13%。同时,STAPO还表现出更强的熵稳定性,有效避免了训练后期出现的性能崩塌问题。
🎯 应用场景
STAPO方法可应用于各种需要强化学习微调的大型语言模型任务,尤其是在数学推理、代码生成等对token序列质量要求较高的领域。该方法能够提升模型的推理能力和训练稳定性,降低模型部署和维护的成本,具有广泛的应用前景。
📄 摘要(原文)
Reinforcement Learning (RL) has significantly improved large language model reasoning, but existing RL fine-tuning methods rely heavily on heuristic techniques such as entropy regularization and reweighting to maintain stability. In practice, they often experience late-stage performance collapse, leading to degraded reasoning quality and unstable training. We derive that the magnitude of token-wise policy gradients in RL is negatively correlated with token probability and local policy entropy. Building on this result, we prove that training instability is driven by a tiny fraction of tokens, approximately 0.01\%, which we term \emph{spurious tokens}. When such tokens appear in correct responses, they contribute little to the reasoning outcome but inherit the full sequence-level reward, leading to abnormally amplified gradient updates. Motivated by this observation, we propose Spurious-Token-Aware Policy Optimization (STAPO) for large-scale model refining, which selectively masks such updates and renormalizes the loss over valid tokens. Across six mathematical reasoning benchmarks using Qwen 1.7B, 8B, and 14B base models, STAPO consistently demonstrates superior entropy stability and achieves an average performance improvement of 7.13\% over GRPO, 20-Entropy and JustRL.