jina-embeddings-v5-text: Task-Targeted Embedding Distillation
作者: Mohammad Kalim Akram, Saba Sturua, Nastia Havriushenko, Quentin Herreros, Michael Günther, Maximilian Werk, Han Xiao
分类: cs.CL
发布日期: 2026-02-17
备注: 14 pages, 8 figures. Model weights: https://huggingface.co/collections/jinaai/jina-embeddings-v5-text
💡 一句话要点
提出任务导向的蒸馏方法,用于训练高性能小型文本嵌入模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本嵌入 模型蒸馏 对比学习 长文本处理 语义相似度 信息检索 量化鲁棒性
📋 核心要点
- 现有的通用文本嵌入模型通常采用对比损失函数进行单阶段或多阶段训练,但小型模型性能受限。
- 论文提出了一种结合模型蒸馏和任务特定对比损失的训练方法,旨在提升小型文本嵌入模型的性能。
- 实验结果表明,该方法在训练小型模型时优于纯对比学习或蒸馏方法,并在长文本和量化方面表现出鲁棒性。
📝 摘要(中文)
本文提出了一种新的训练方法,该方法结合了模型蒸馏技术和任务特定的对比损失,以生成紧凑、高性能的嵌入模型。研究结果表明,对于训练小型模型而言,这种方法比单纯的对比学习或基于蒸馏的训练范式更有效。所得到的模型jina-embeddings-v5-text-small和jina-embeddings-v5-text-nano的基准测试分数超过或匹配了类似大小模型的当前最佳水平。jina-embeddings-v5-text模型还支持多种语言的长文本(最多32k个token),并生成在截断和二值量化下仍然保持鲁棒性的嵌入。模型权重已公开提供,希望能激发嵌入模型开发的进一步进展。
🔬 方法详解
问题定义:论文旨在解决通用文本嵌入模型在小型化时性能下降的问题。现有方法,如单纯的对比学习或蒸馏,无法充分利用小型模型的潜力,导致性能受限,尤其是在处理长文本和量化时的鲁棒性不足。
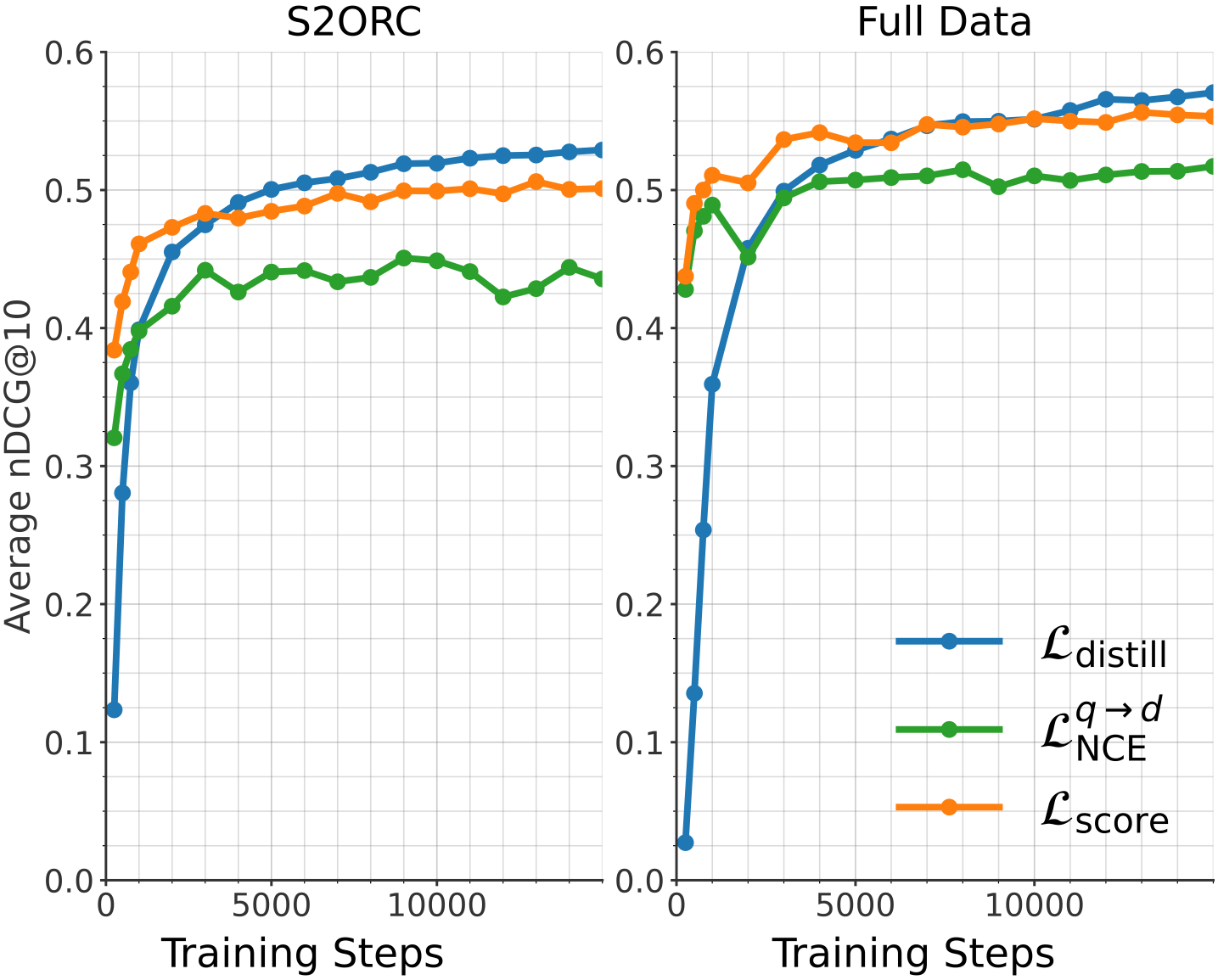
核心思路:论文的核心思路是将模型蒸馏与任务特定的对比损失相结合。通过蒸馏,小型模型可以学习大型模型的知识,而任务特定的对比损失则引导模型学习更适合特定任务的嵌入表示。这种结合能够克服单一方法的局限性,提升小型模型的性能。
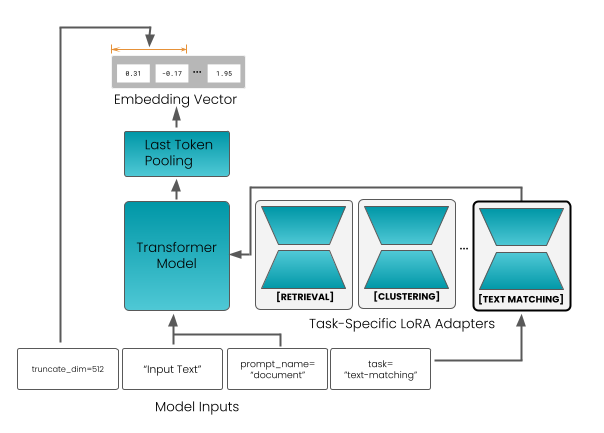
技术框架:该方法包含以下主要阶段:1) 使用大型教师模型生成文本嵌入;2) 使用任务特定的对比损失函数训练小型学生模型,同时利用教师模型的嵌入作为监督信号进行蒸馏;3) 对训练好的模型进行评估和优化。整体流程旨在使学生模型在保持较小体积的同时,尽可能逼近教师模型的性能,并针对特定任务进行优化。
关键创新:该方法最重要的技术创新点在于将模型蒸馏和任务特定的对比损失相结合。与传统的蒸馏方法不同,该方法不仅仅是简单地模仿教师模型的输出,而是通过对比损失来引导学生模型学习更具判别性的嵌入表示。此外,该方法还关注长文本处理和量化鲁棒性,使其更具实用价值。
关键设计:在具体实现上,论文可能采用了以下关键设计:1) 选择合适的教师模型,例如大型预训练语言模型;2) 设计任务特定的对比损失函数,例如InfoNCE loss;3) 调整蒸馏损失的权重,平衡知识迁移和任务优化;4) 采用数据增强技术,提升模型的泛化能力;5) 探索不同的网络结构,优化学生模型的性能。
🖼️ 关键图片
📊 实验亮点
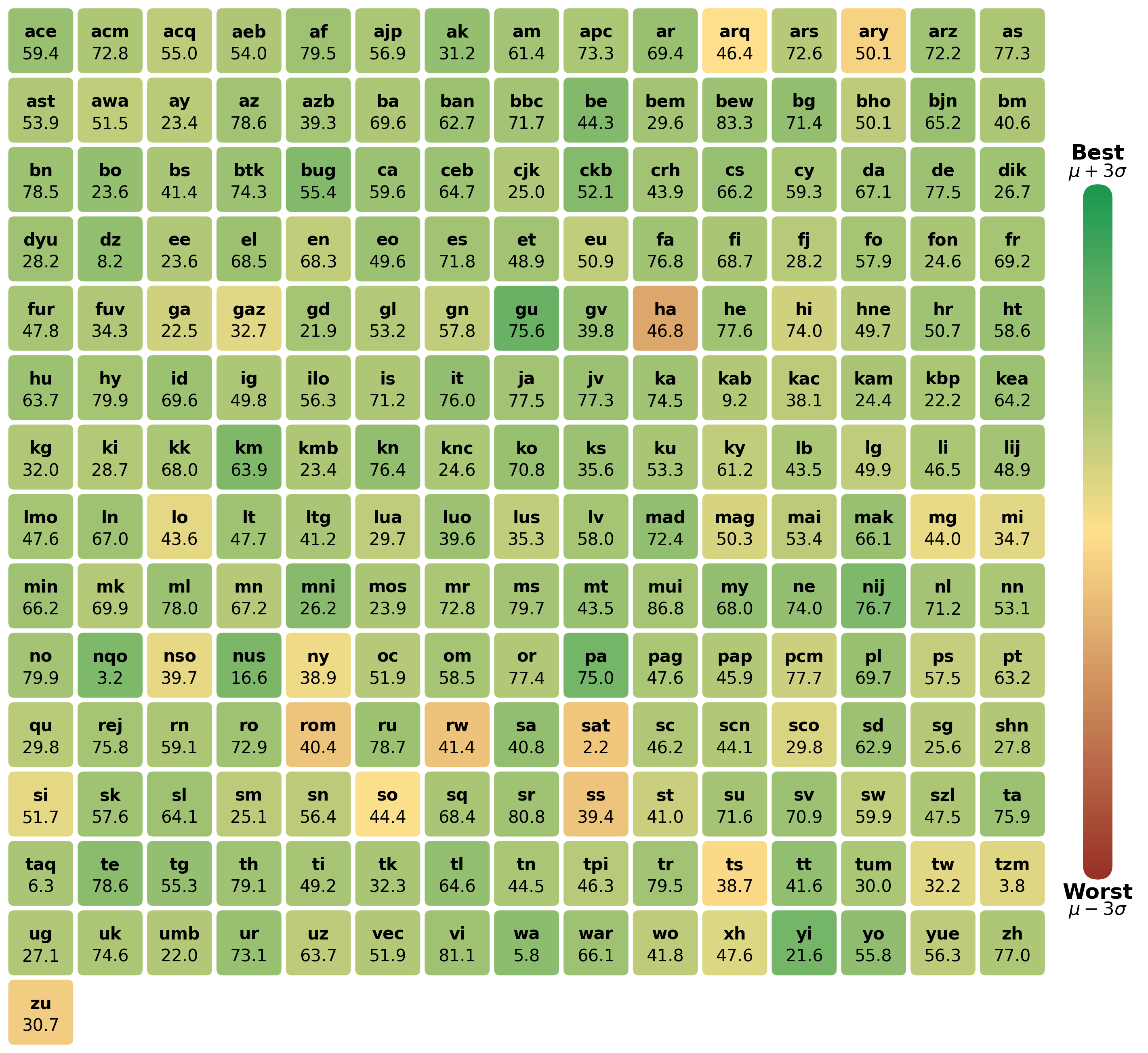
论文提出的jina-embeddings-v5-text-small和jina-embeddings-v5-text-nano模型在基准测试中取得了与同等规模模型相比更优或相当的性能。此外,这些模型支持长达32k tokens的文本,并在截断和二值量化下表现出良好的鲁棒性,表明其在实际应用中具有很强的竞争力。
🎯 应用场景
该研究成果可广泛应用于信息检索、文本聚类、语义相似度计算等领域。小型高性能嵌入模型能够降低计算成本,提升部署效率,尤其适用于资源受限的场景,如移动设备和边缘计算。此外,该模型对长文本的支持使其在处理文档分析、问答系统等任务时更具优势。
📄 摘要(原文)
Text embedding models are widely used for semantic similarity tasks, including information retrieval, clustering, and classification. General-purpose models are typically trained with single- or multi-stage processes using contrastive loss functions. We introduce a novel training regimen that combines model distillation techniques with task-specific contrastive loss to produce compact, high-performance embedding models. Our findings suggest that this approach is more effective for training small models than purely contrastive or distillation-based training paradigms alone. Benchmark scores for the resulting models, jina-embeddings-v5-text-small and jina-embeddings-v5-text-nano, exceed or match the state-of-the-art for models of similar size. jina-embeddings-v5-text models additionally support long texts (up to 32k tokens) in many languages, and generate embeddings that remain robust under truncation and binary quantization. Model weights are publicly available, hopefully inspiring further advances in embedding model development.