Fine-Refine: Iterative Fine-grained Refinement for Mitigating Dialogue Hallucination
作者: Xiangyan Chen, Yujian Gan, Matthew Purver
分类: cs.CL
发布日期: 2026-02-17
💡 一句话要点
提出Fine-Refine框架,通过细粒度迭代修正缓解对话系统中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话系统 幻觉缓解 细粒度修正 知识库 事实性验证
📋 核心要点
- 现有对话系统修正方法忽略了回复中可能存在多个事实性错误,导致修正不够精细。
- Fine-Refine框架将回复分解为原子单元,逐一验证并迭代修正,实现细粒度的错误纠正。
- 实验表明,Fine-Refine能显著提升对话事实准确度,最高提升7.63个百分点,但对话质量略有下降。
📝 摘要(中文)
当前大型语言模型(LLMs)中存在的幻觉倾向对对话系统产生了负面影响。这种幻觉会产生不准确的事实性回复,误导用户并损害系统信任。现有的对话系统修正方法通常在回复层面进行操作,忽略了单个回复可能包含多个可验证或不可验证的事实。为了解决这一差距,我们提出了Fine-Refine,一个细粒度的修正框架,它将回复分解为原子单元,使用外部知识验证每个单元,通过困惑度评估流畅性,并迭代地纠正细粒度的错误。我们在HybriDialogue和OpendialKG数据集上评估了事实性,指标包括事实准确度(fact score)和覆盖率(Not Enough Information Proportion)。实验表明,Fine-Refine显著提高了事实性,在对话事实得分方面实现了高达7.63个百分点的提升,同时对话质量略有下降。
🔬 方法详解
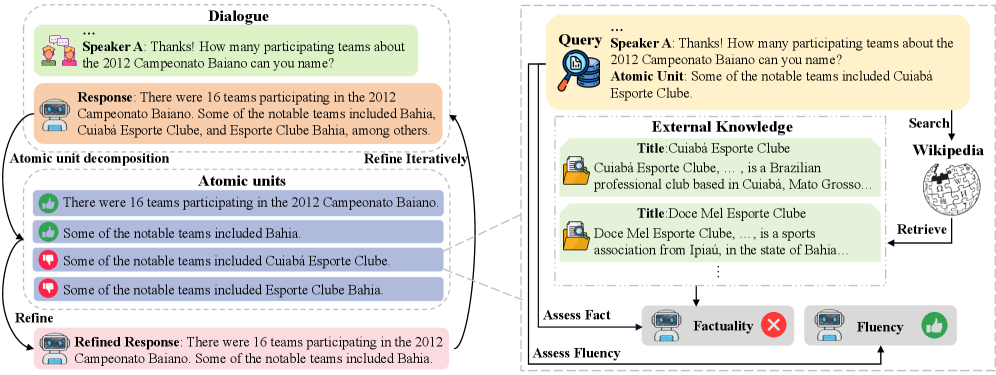
问题定义:论文旨在解决对话系统中大型语言模型(LLMs)产生的幻觉问题,即生成不真实或与知识库不符的回复。现有方法通常在整个回复层面进行修正,无法处理回复中同时存在正确和错误信息的情况,导致修正效果不佳。这种粗粒度的修正方式无法有效定位和纠正细粒度的错误。
核心思路:Fine-Refine的核心思路是将对话回复分解为更小的、原子性的单元(例如,单个事实或陈述),然后针对每个单元进行独立的事实性验证和修正。通过这种细粒度的处理,可以更精确地定位和纠正错误,从而提高整体回复的事实准确性。这种设计借鉴了人类编辑校对的思路,即逐句甚至逐词地检查和修改。
技术框架:Fine-Refine框架包含以下主要模块:1) 回复分解:将LLM生成的回复分解为原子单元。2) 事实验证:使用外部知识库(如知识图谱或搜索引擎)验证每个单元的事实性。3) 流畅性评估:使用困惑度(perplexity)评估每个单元的流畅性,避免过度修正导致语句不通顺。4) 迭代修正:根据事实验证和流畅性评估的结果,迭代地修正每个单元,直到满足预定的准确性或流畅性标准。
关键创新:Fine-Refine的关键创新在于其细粒度的修正方法。与现有方法在整个回复层面进行修正不同,Fine-Refine将回复分解为原子单元,并针对每个单元进行独立的事实性验证和修正。这种细粒度的处理方式能够更精确地定位和纠正错误,从而提高整体回复的事实准确性。此外,迭代修正机制允许逐步改进回复,进一步提高准确性。
关键设计:论文中可能涉及的关键设计包括:1) 原子单元的定义和分解方法(例如,基于依存句法分析或语义角色标注)。2) 外部知识库的选择和使用方法(例如,使用知识图谱进行实体链接和关系抽取)。3) 困惑度的计算方法和阈值设定。4) 迭代修正的停止条件(例如,达到预定的准确性或流畅性阈值,或达到最大迭代次数)。这些细节决定了Fine-Refine框架的实际效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Fine-Refine框架在HybriDialogue和OpendialKG数据集上显著提高了对话的事实准确度,最高提升了7.63个百分点。虽然对话质量略有下降,但整体性能优于现有方法。这些结果验证了细粒度修正方法在缓解对话幻觉方面的有效性。
🎯 应用场景
Fine-Refine框架可应用于各种对话系统,例如聊天机器人、问答系统和虚拟助手,尤其是在需要高信息准确性的场景中,如医疗咨询、金融服务和教育领域。通过减少幻觉,该框架可以提高用户对对话系统的信任度,并减少错误信息带来的潜在风险。未来,该技术可进一步扩展到其他自然语言生成任务,如文本摘要和机器翻译。
📄 摘要(原文)
The tendency for hallucination in current large language models (LLMs) negatively impacts dialogue systems. Such hallucinations produce factually incorrect responses that may mislead users and undermine system trust. Existing refinement methods for dialogue systems typically operate at the response level, overlooking the fact that a single response may contain multiple verifiable or unverifiable facts. To address this gap, we propose Fine-Refine, a fine-grained refinement framework that decomposes responses into atomic units, verifies each unit using external knowledge, assesses fluency via perplexity, and iteratively corrects granular errors. We evaluate factuality across the HybriDialogue and OpendialKG datasets in terms of factual accuracy (fact score) and coverage (Not Enough Information Proportion), and experiments show that Fine-Refine substantially improves factuality, achieving up to a 7.63-point gain in dialogue fact score, with a small trade-off in dialogue quality.