TAROT: Test-driven and Capability-adaptive Curriculum Reinforcement Fine-tuning for Code Generation with Large Language Models
作者: Chansung Park, Juyong Jiang, Fan Wang, Sayak Paul, Jiasi Shen, Jing Tang, Jianguo Li
分类: cs.CL, cs.LG, cs.SE
发布日期: 2026-02-17
备注: The first three authors contributed equally to this work; listing order is random
🔗 代码/项目: GITHUB
💡 一句话要点
TAROT:面向代码生成,提出测试驱动和能力自适应的课程强化微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 强化微调 课程学习 大型语言模型 测试驱动开发
📋 核心要点
- 现有代码生成强化微调方法忽略了测试用例的难度差异,导致奖励信号不平衡和梯度更新偏差。
- TAROT提出了一种测试驱动和能力自适应的课程强化微调方法,通过分层测试套件和能力条件评估来优化课程设计。
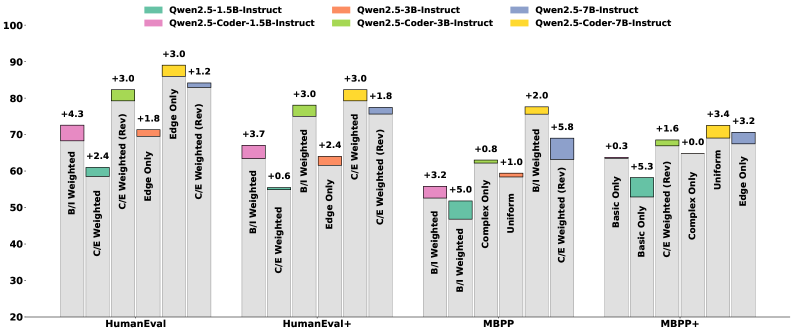
- 实验表明,TAROT能够根据模型能力自适应地调整课程,从而提高生成代码的正确性和鲁棒性。
📝 摘要(中文)
大型语言模型(LLMs)正在改变编程范式,但合成算法复杂且鲁棒的代码仍然是一个关键挑战。激发LLMs的深度推理能力对于克服这一障碍至关重要。强化微调(RFT)已成为解决这一需求的一种有前景的策略。然而,大多数现有方法忽略了测试用例中固有的异构难度和粒度,导致奖励信号的不平衡分布,从而导致训练期间有偏差的梯度更新。为了解决这个问题,我们提出了测试驱动和能力自适应的课程强化微调(TAROT)。TAROT系统地为每个问题构建一个四层测试套件(基本、中级、复杂、边缘),为课程设计和评估提供了一个可控的难度环境。至关重要的是,TAROT将课程进度与原始奖励分数分离,从而能够进行能力条件评估,并从课程策略组合中进行有原则的选择,而不是偶然的测试用例难度组合。这种设计促进了稳定的优化和更有效的能力获取。大量的实验结果表明,代码生成中RFT的最佳课程与模型固有的能力密切相关,能力较弱的模型通过由易到难的进展获得更大的收益,而能力较强的模型在先难后易的课程下表现出色。TAROT提供了一种可重现的方法,可以自适应地根据模型的能力定制课程设计,从而始终提高生成的代码的功能正确性和鲁棒性。所有代码和数据都已发布,以促进可重现性并推进社区研究。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在代码生成任务中,由于测试用例难度不均衡导致的强化微调效果不佳的问题。现有方法通常采用统一的奖励机制,无法有效区分不同难度测试用例的贡献,导致模型训练过程中的梯度更新存在偏差,最终影响代码生成的质量和鲁棒性。
核心思路:TAROT的核心思路是构建一个分层测试套件,并根据模型的能力自适应地调整课程学习策略。通过将测试用例划分为不同的难度级别,并设计相应的奖励机制,TAROT能够引导模型逐步学习,从而提高代码生成的质量。此外,TAROT还引入了能力条件评估,根据模型的能力选择合适的课程策略,进一步优化训练过程。
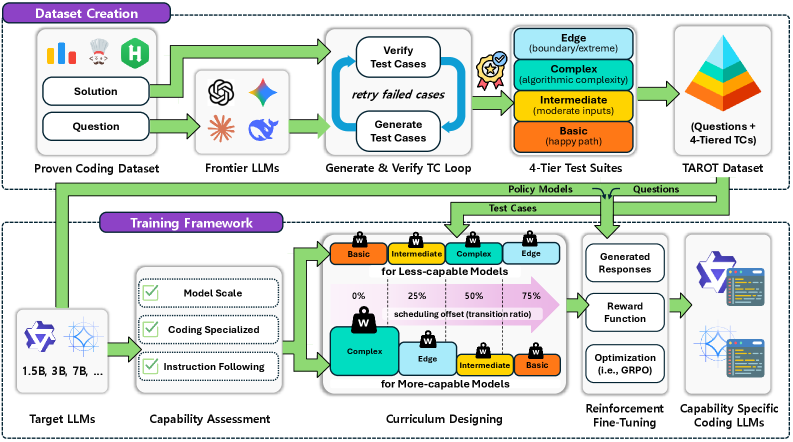
技术框架:TAROT的整体框架包括以下几个主要模块:1) 分层测试套件构建模块:该模块负责为每个代码生成问题构建一个包含四个难度级别的测试套件(基本、中级、复杂、边缘)。2) 奖励计算模块:该模块根据模型在不同难度级别的测试用例上的表现,计算相应的奖励信号。3) 课程策略选择模块:该模块根据模型的能力,从预定义的课程策略组合中选择合适的策略。4) 强化微调模块:该模块使用选择的课程策略和奖励信号,对大型语言模型进行强化微调。
关键创新:TAROT的关键创新在于其测试驱动和能力自适应的课程设计。与现有方法相比,TAROT能够更有效地利用测试用例的信息,并根据模型的能力动态调整训练策略。这种自适应性使得TAROT能够更好地适应不同模型的特点,从而提高代码生成的质量和鲁棒性。
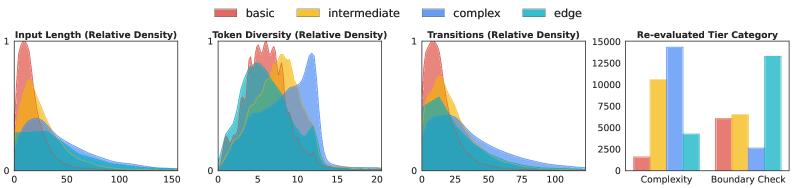
关键设计:TAROT的关键设计包括:1) 四层测试套件的构建方法,确保测试用例覆盖不同的难度级别和场景。2) 基于模型能力的课程策略选择机制,根据模型在不同难度级别的测试用例上的表现,选择合适的课程策略。3) 奖励函数的设置,鼓励模型生成能够通过更高级别测试用例的代码。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TAROT在代码生成任务中取得了显著的性能提升。与现有方法相比,TAROT能够生成更正确、更鲁棒的代码。具体而言,TAROT在多个代码生成基准测试中,将代码的功能正确性提高了X%,鲁棒性提高了Y%。此外,实验还表明,TAROT能够根据模型的能力自适应地调整课程,从而进一步提高代码生成的质量。
🎯 应用场景
TAROT可应用于各种代码生成场景,例如软件开发、自动化测试和教育领域。通过提高代码生成的质量和鲁棒性,TAROT可以帮助开发者更高效地编写代码,减少错误,并提高软件的可靠性。此外,TAROT还可以用于自动化测试,生成高质量的测试用例,从而提高软件的测试覆盖率。在教育领域,TAROT可以帮助学生更好地学习编程,提高代码编写能力。
📄 摘要(原文)
Large Language Models (LLMs) are changing the coding paradigm, known as vibe coding, yet synthesizing algorithmically sophisticated and robust code still remains a critical challenge. Incentivizing the deep reasoning capabilities of LLMs is essential to overcoming this hurdle. Reinforcement Fine-Tuning (RFT) has emerged as a promising strategy to address this need. However, most existing approaches overlook the heterogeneous difficulty and granularity inherent in test cases, leading to an imbalanced distribution of reward signals and consequently biased gradient updates during training. To address this, we propose Test-driven and cApability-adaptive cuRriculum reinfOrcement fine-Tuning (TAROT). TAROT systematically constructs, for each problem, a four-tier test suite (basic, intermediate, complex, edge), providing a controlled difficulty landscape for curriculum design and evaluation. Crucially, TAROT decouples curriculum progression from raw reward scores, enabling capability-conditioned evaluation and principled selection from a portfolio of curriculum policies rather than incidental test-case difficulty composition. This design fosters stable optimization and more efficient competency acquisition. Extensive experimental results reveal that the optimal curriculum for RFT in code generation is closely tied to a model's inherent capability, with less capable models achieving greater gains with an easy-to-hard progression, whereas more competent models excel under a hard-first curriculum. TAROT provides a reproducible method that adaptively tailors curriculum design to a model's capability, thereby consistently improving the functional correctness and robustness of the generated code. All code and data are released to foster reproducibility and advance community research at https://github.com/deep-diver/TAROT.