The Vision Wormhole: Latent-Space Communication in Heterogeneous Multi-Agent Systems
作者: Xiaoze Liu, Ruowang Zhang, Weichen Yu, Siheng Xiong, Liu He, Feijie Wu, Hoin Jung, Matt Fredrikson, Xiaoqian Wang, Jing Gao
分类: cs.CL, cs.CV, cs.LG
发布日期: 2026-02-17
备注: Preprint. Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
提出Vision Wormhole,实现异构多智能体系统中的无文本隐空间通信。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 异构通信 视觉语言模型 隐空间通信 无文本通信 知识蒸馏 通用视觉编码
📋 核心要点
- 现有基于文本的多智能体系统通信效率低,存在运行时开销大和信息量化损失的问题。
- Vision Wormhole利用视觉语言模型的视觉接口,通过通用视觉编解码器实现无文本的隐空间通信。
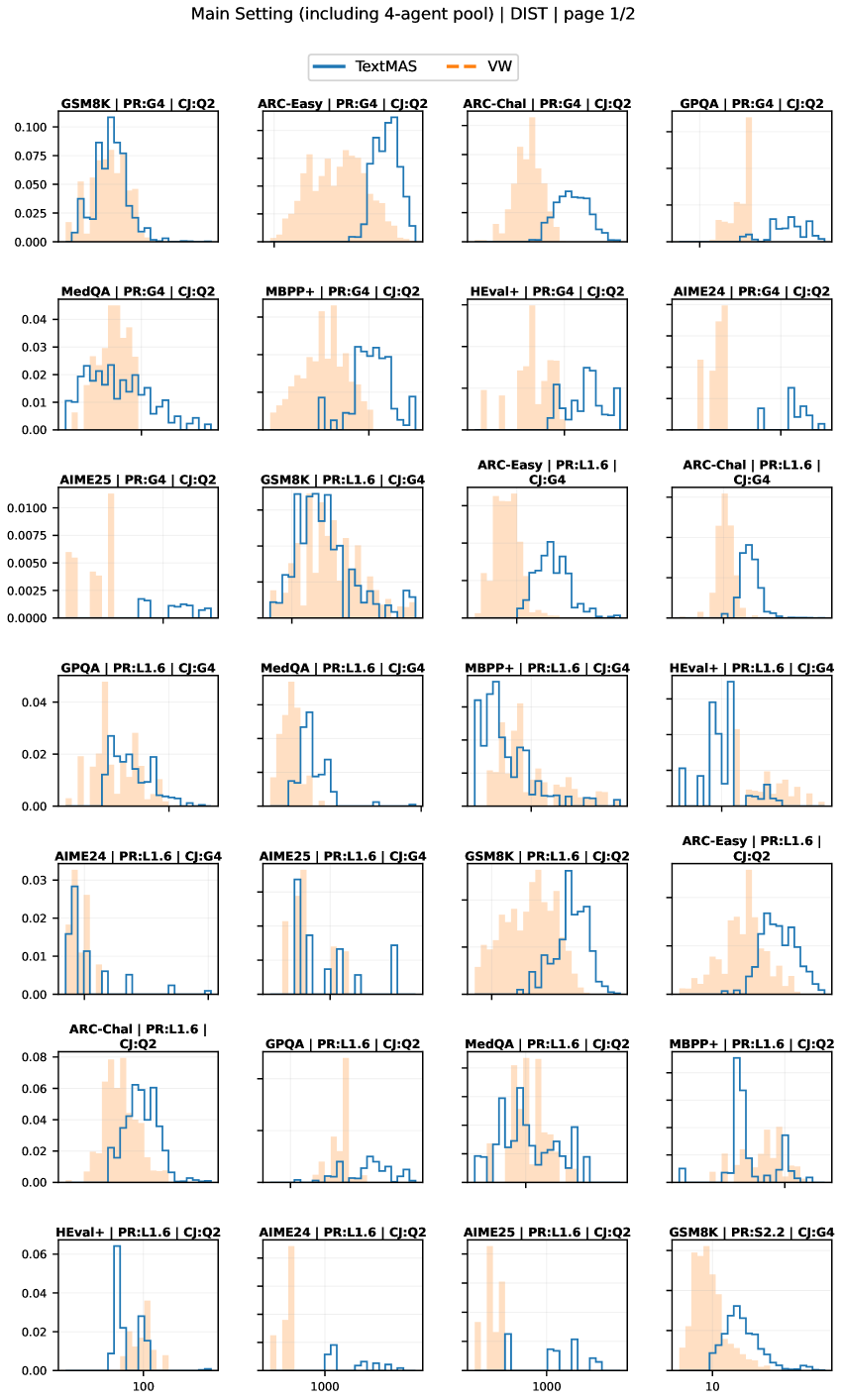
- 实验表明,Vision Wormhole在保证推理精度的前提下,显著降低了端到端运行时间。
📝 摘要(中文)
本文提出Vision Wormhole,一个新颖的框架,旨在利用视觉语言模型(VLM)的视觉接口,实现模型无关、无文本的通信。现有基于大型语言模型的多智能体系统(MAS)虽然实现了高级协作推理,但受限于离散文本通信的低效性,导致显著的运行时开销和信息量化损失。虽然隐状态传输提供了一种高带宽的替代方案,但现有方法要么假设同构的发送者-接收者架构,要么依赖于特定于配对的学习翻译器,限制了跨具有不相交流形的不同模型系列的可扩展性和模块化。Vision Wormhole通过引入通用视觉编解码器,将异构推理轨迹映射到共享的连续潜在空间,并将其直接注入到接收者的视觉通路中,有效地将视觉编码器视为智能体间心灵感应的通用端口。该框架采用hub-and-spoke拓扑,将配对对齐复杂度从O(N^2)降低到O(N),并利用无标签的师生蒸馏目标,使高速视觉通道与文本通道的鲁棒推理模式对齐。在异构模型系列(例如,Qwen-VL,Gemma)上的大量实验表明,Vision Wormhole在受控比较中减少了端到端挂钟时间,同时保持了与标准基于文本的MAS相当的推理保真度。
🔬 方法详解
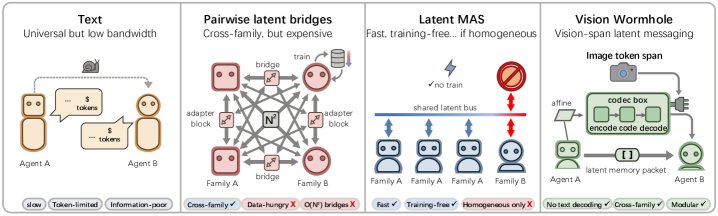
问题定义:现有基于大型语言模型的多智能体系统依赖文本进行通信,效率较低,存在信息损失和延迟。直接进行隐空间状态转移的方法,通常需要同构模型架构或针对特定模型对训练转换器,难以扩展到异构模型场景。因此,需要一种通用的、高效的、模型无关的通信方式。
核心思路:利用视觉语言模型(VLM)的视觉编码器作为通用接口,将不同模型的推理过程编码成视觉信息,通过视觉通道传递给其他智能体。这种方法避免了文本通信的低效性,并且利用了VLM强大的视觉理解能力,实现了模型无关的隐空间通信。
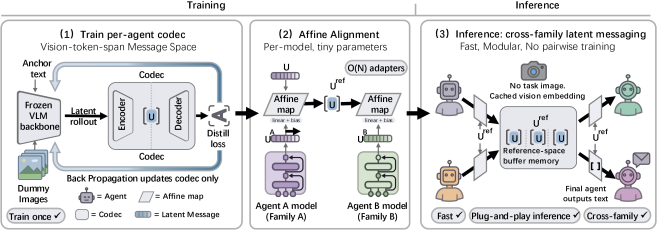
技术框架:Vision Wormhole采用hub-and-spoke的拓扑结构,其中一个中心节点(hub)负责将信息编码成视觉信号,其他节点(spokes)通过视觉通道接收信息。整个框架包含三个主要模块:1) Universal Visual Codec:将异构智能体的推理轨迹编码为视觉表征。2) Visual Channel:视觉信息的传输通道,即VLM的视觉编码器。3) Teacher-Student Distillation:利用文本通信作为教师信号,指导视觉通道的学习,保证推理的准确性。
关键创新:该方法最重要的创新在于利用VLM的视觉接口实现了异构智能体之间的无文本通信。与传统的文本通信相比,该方法具有更高的带宽和更低的延迟。与现有的隐空间通信方法相比,该方法不需要同构模型架构或针对特定模型对训练转换器,具有更好的通用性和可扩展性。
关键设计:Universal Visual Codec的设计至关重要,需要能够将不同类型的推理轨迹编码成统一的视觉表征。Teacher-Student Distillation采用无标签的方式,利用文本通信的输出来指导视觉通道的学习。损失函数的设计需要平衡推理的准确性和通信的效率。Hub-and-spoke的拓扑结构降低了配对对齐的复杂度,提高了系统的可扩展性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Vision Wormhole在异构模型(Qwen-VL, Gemma)上实现了与文本通信相当的推理精度,同时显著降低了端到端运行时间。具体而言,在受控实验中,Vision Wormhole能够减少wall-clock time,证明了其在实际应用中的潜力。
🎯 应用场景
该研究成果可应用于需要多智能体协作的复杂任务,例如自动驾驶、机器人协同、智能交通管理等。通过提高通信效率,可以显著提升系统的整体性能和响应速度。此外,该方法还可以促进异构模型之间的协作,充分利用不同模型的优势,构建更加强大的智能系统。
📄 摘要(原文)
Multi-Agent Systems (MAS) powered by Large Language Models have unlocked advanced collaborative reasoning, yet they remain shackled by the inefficiency of discrete text communication, which imposes significant runtime overhead and information quantization loss. While latent state transfer offers a high-bandwidth alternative, existing approaches either assume homogeneous sender-receiver architectures or rely on pair-specific learned translators, limiting scalability and modularity across diverse model families with disjoint manifolds. In this work, we propose the Vision Wormhole, a novel framework that repurposes the visual interface of Vision-Language Models (VLMs) to enable model-agnostic, text-free communication. By introducing a Universal Visual Codec, we map heterogeneous reasoning traces into a shared continuous latent space and inject them directly into the receiver's visual pathway, effectively treating the vision encoder as a universal port for inter-agent telepathy. Our framework adopts a hub-and-spoke topology to reduce pairwise alignment complexity from O(N^2) to O(N) and leverages a label-free, teacher-student distillation objective to align the high-speed visual channel with the robust reasoning patterns of the text pathway. Extensive experiments across heterogeneous model families (e.g., Qwen-VL, Gemma) demonstrate that the Vision Wormhole reduces end-to-end wall-clock time in controlled comparisons while maintaining reasoning fidelity comparable to standard text-based MAS. Code is available at https://github.com/xz-liu/heterogeneous-latent-mas