Making Large Language Models Speak Tulu: Structured Prompting for an Extremely Low-Resource Language
作者: Prathamesh Devadiga, Paras Chopra
分类: cs.CL
发布日期: 2026-02-17
备注: Accepted to EACL LoResLM Workshop
💡 一句话要点
通过结构化提示,使大语言模型能够使用极低资源语言Tulu进行对话。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源语言处理 结构化提示 大语言模型 Tulu语 负约束
📋 核心要点
- 现有大语言模型在低资源语言上的表现不佳,缺乏足够的训练数据是主要挑战。
- 论文提出一种基于结构化提示的方法,结合语法文档、负约束和合成数据,提升LLM在Tulu语上的对话能力。
- 实验表明,该方法显著降低了词汇污染,提高了语法准确率,并在多个LLM上验证了有效性。
📝 摘要(中文)
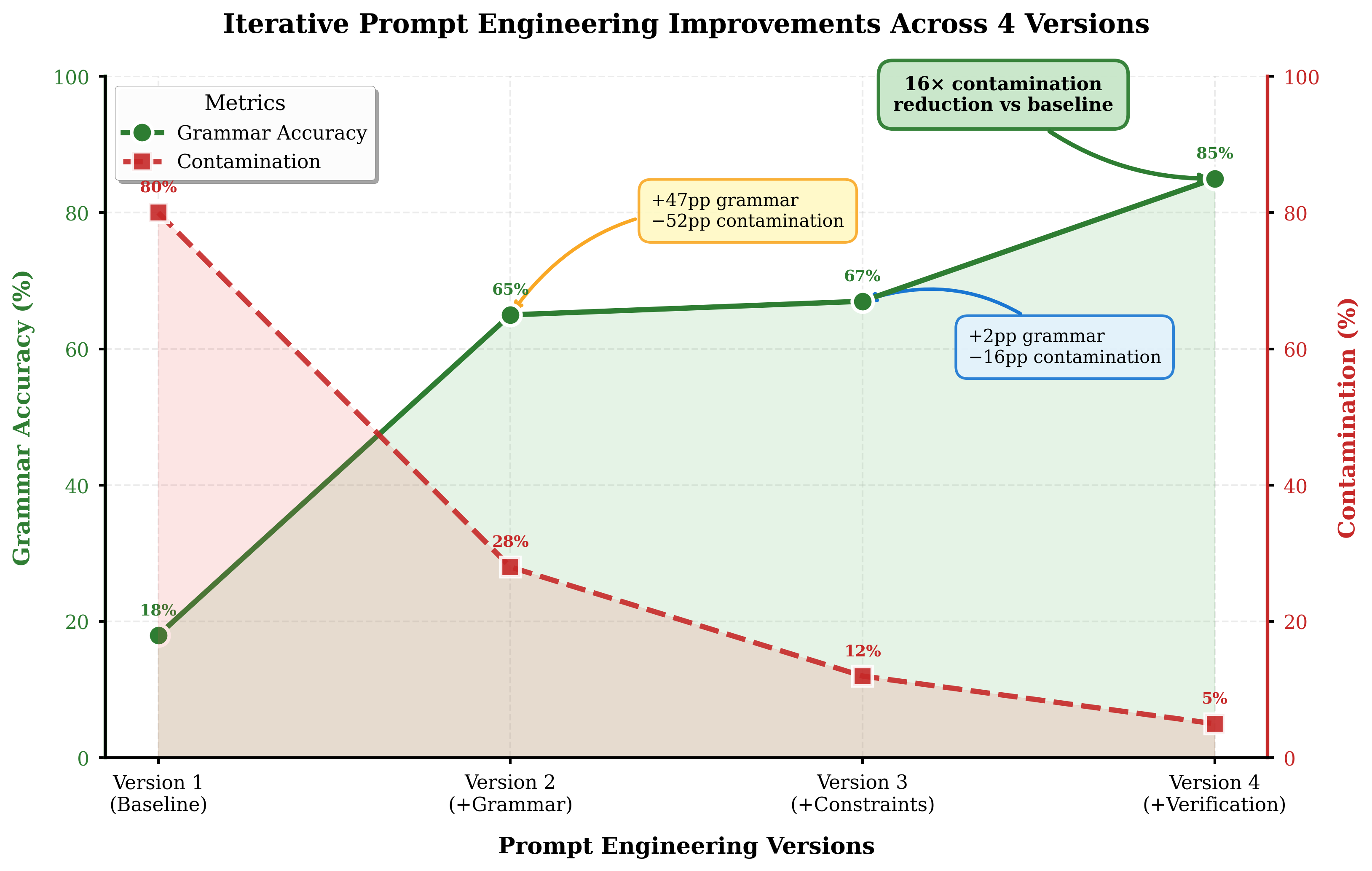
本文研究了大语言模型在几乎没有训练数据的语言中进行对话的能力。以Tulu语为例,该语言拥有超过200万使用者,但数字资源极少。本文没有对LLM进行微调,而是研究了在受控提示下,仅通过结构化提示是否能够激发基本的对话能力。通过结合显式语法文档、抑制相关语言高概率token的负约束、罗马化标准化以及通过自博弈进行质量控制的合成数据生成,系统地解决了Tulu语训练数据缺失带来的各种挑战。在三个LLM(Gemini 2.0 Flash、GPT-4o、Llama 3.1 70B)上手动策划的保留集上进行评估,并由母语人士验证,该方法将词汇污染从80%降低到5%,同时实现了85%的语法准确率。跨模型分析表明,负约束提供了持续的改进(12-18个百分点),而语法文档的效果因模型架构而异(8-22个百分点)。
🔬 方法详解
问题定义:论文旨在解决大语言模型在极低资源语言(如Tulu语)上的对话能力问题。现有方法,如直接应用预训练模型或进行微调,由于缺乏足够的Tulu语数据,效果不佳,容易受到其他高资源语言的干扰,导致词汇污染和语法错误。
核心思路:论文的核心思路是通过精心设计的结构化提示,引导LLM在没有大量Tulu语训练数据的情况下,也能生成符合语法规则且语义合理的Tulu语回复。这种方法避免了昂贵的微调过程,并充分利用了LLM的泛化能力。
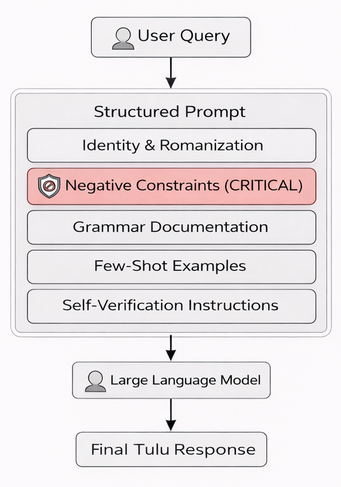
技术框架:整体流程包括以下几个关键阶段:1) 语法文档构建:收集并整理Tulu语的显式语法规则。2) 负约束设计:通过负约束抑制LLM生成其他相关语言(如卡纳达语)的高概率token,减少词汇污染。3) 罗马化标准化:统一Tulu语的罗马化表示,减少拼写变体带来的影响。4) 合成数据生成:利用自博弈生成高质量的Tulu语对话数据,用于进一步提升LLM的对话能力。5) 评估验证:在手动策划的保留集上进行评估,并由母语人士验证生成结果的质量。
关键创新:该方法最重要的创新在于将结构化提示与多种技术手段相结合,有效地解决了低资源语言的对话生成问题。与传统的微调方法相比,该方法更加轻量级,且不需要大量的标注数据。负约束的使用是减少词汇污染的关键。
关键设计:负约束的具体实现方式未知,但推测是通过在生成过程中动态调整token的概率分布,降低与目标语言无关的token的生成概率。合成数据的生成可能使用了强化学习或对抗生成网络等技术,以保证数据的质量和多样性。具体的参数设置和网络结构在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够显著降低Tulu语对话生成中的词汇污染,从80%降低到5%,同时实现了85%的语法准确率。负约束的使用带来了12-18个百分点的持续改进,而语法文档的效果因模型架构而异,提升幅度在8-22个百分点之间。这些结果表明,结构化提示是一种有效的低资源语言对话生成方法。
🎯 应用场景
该研究成果可应用于其他低资源语言的自然语言处理任务,例如机器翻译、语音识别和文本生成。通过结构化提示,可以使LLM在缺乏大量训练数据的情况下,也能支持这些语言,从而促进语言保护和文化传承。此外,该方法还可以应用于特定领域的专业术语生成,提高LLM在特定领域的应用能力。
📄 摘要(原文)
Can large language models converse in languages virtually absent from their training data? We investigate this question through a case study on Tulu, a Dravidian language with over 2 million speakers but minimal digital presence. Rather than fine-tuning an LLM, we examine whether structured prompts alone can elicit basic conversational ability under controlled prompting. We systematically tackle various challenges posed by absence of training data for Tulu by combining explicit grammar documentation, negative constraints to suppress high-probability tokens from related languages, romanization standardization, and quality-controlled synthetic data generation via self-play. Evaluated on a manually curated held-out set across three LLMs (Gemini 2.0 Flash, GPT-4o, Llama 3.1 70B) and validated by native speakers, our approach reduces vocabulary contamination from 80% to 5% while achieving 85% grammatical accuracy. Cross-model analysis reveals that negative constraints provide consistent improvements (12--18 percentage points), while grammar documentation effects vary by model architecture (8--22 points).