InnoEval: On Research Idea Evaluation as a Knowledge-Grounded, Multi-Perspective Reasoning Problem
作者: Shuofei Qiao, Yunxiang Wei, Xuehai Wang, Bin Wu, Boyang Xue, Ningyu Zhang, Hossein A. Rahmani, Yanshan Wang, Qiang Zhang, Keyan Ding, Jeff Z. Pan, Huajun Chen, Emine Yilmaz
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2026-02-16
备注: Ongoing Work
💡 一句话要点
InnoEval:提出一种知识驱动、多视角推理的创新评估框架,提升科研idea评估质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 创新评估 知识驱动 多视角推理 大型语言模型 科研idea 专家评审 深度学习
📋 核心要点
- 现有idea评估方法存在知识面窄、评估维度单一以及LLM偏见等问题,无法满足科学评估的需求。
- InnoEval将idea评估视为知识驱动、多视角推理问题,通过检索证据和专家评审模拟人类评估。
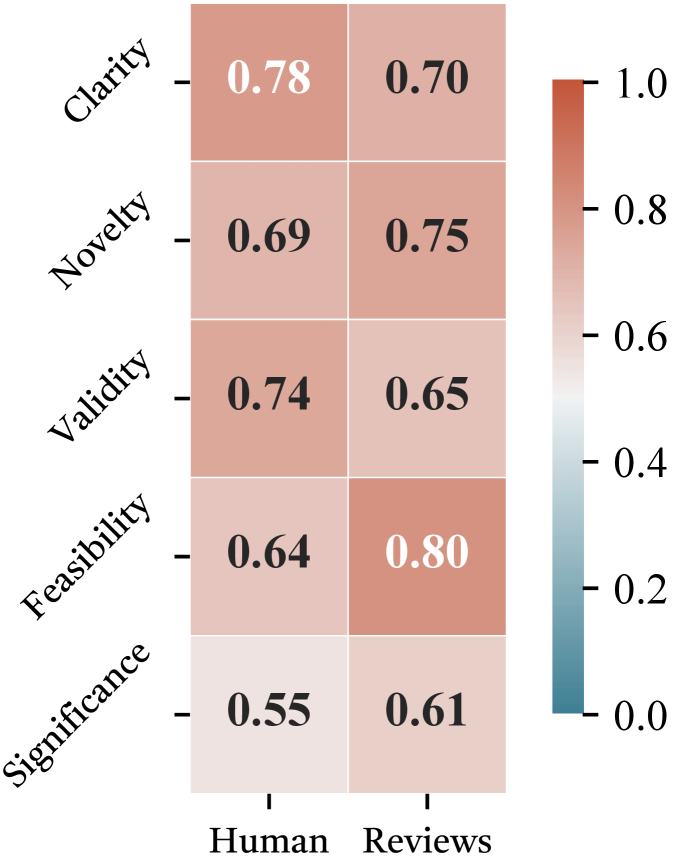
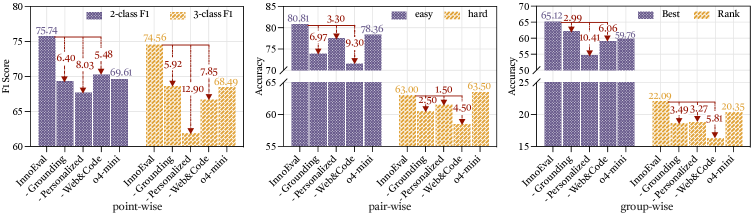
- 实验表明,InnoEval在多个评估任务中超越基线,其判断与人类专家高度一致,证明了有效性。
📝 摘要(中文)
大型语言模型的快速发展催生了科学idea的爆发式增长,但idea评估方法却没有相应进步。科学评估的本质需要知识支撑、集体审议和多标准决策。然而,现有的idea评估方法通常存在知识面窄、评估维度扁平以及LLM作为评判者时固有的偏见。为了解决这些问题,我们将idea评估视为一个知识驱动、多视角推理的问题,并提出了InnoEval,一个旨在模拟人类水平idea评估的深度创新评估框架。InnoEval应用异构深度知识搜索引擎,从不同的在线来源检索和获取动态证据。此外,我们利用包含具有不同学术背景的评审员的创新评审委员会达成评审共识,从而实现跨多个指标的多维度解耦评估。我们构建了来自权威同行评审提交的综合数据集,以评估InnoEval。实验表明,InnoEval在逐点、成对和分组评估任务中始终优于基线,展现出与人类专家高度一致的判断模式和共识。
🔬 方法详解
问题定义:论文旨在解决科研idea评估中存在的不足,现有方法面临知识覆盖不足、评估维度单一以及大语言模型作为评判者时存在的偏见等问题。这些问题导致评估结果不够全面、客观,难以准确反映idea的创新性和潜在价值。
核心思路:论文的核心思路是将idea评估视为一个知识驱动、多视角推理的问题。通过引入外部知识和多方专家评审,模拟人类专家进行评估的过程,从而提高评估的准确性和可靠性。这种方法旨在克服现有方法在知识覆盖、评估维度和偏见方面的局限性。
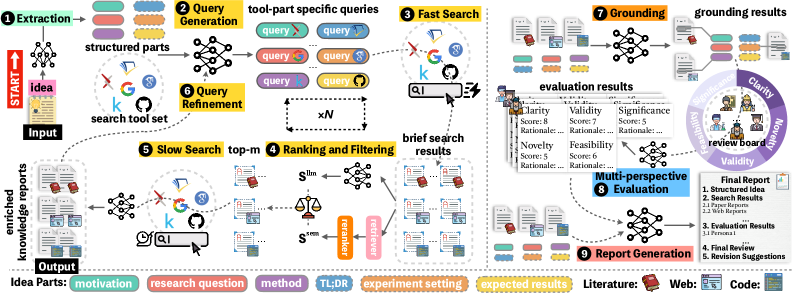
技术框架:InnoEval框架主要包含以下几个模块:1) 异构深度知识搜索引擎:用于从各种在线资源检索和获取与idea相关的动态证据。2) 创新评审委员会:由具有不同学术背景的评审员组成,负责从多个维度对idea进行解耦评估。3) 评估模块:基于检索到的知识和评审委员会的意见,对idea进行综合评估。整体流程是先通过知识搜索引擎获取相关信息,然后由评审委员会进行多维度评估,最后综合各方意见得出最终评估结果。
关键创新:InnoEval的关键创新在于其知识驱动和多视角推理的评估方式。与传统的依赖单一模型或少量信息的评估方法不同,InnoEval通过检索大量外部知识和引入多方专家评审,实现了更全面、客观的评估。这种方法能够有效减少评估中的偏见,提高评估的准确性和可靠性。
关键设计:论文中涉及的关键设计包括:异构深度知识搜索引擎的设计,如何从不同的在线资源中检索相关信息;创新评审委员会的组成和评审流程,如何保证评审的公平性和客观性;以及评估模块的设计,如何综合知识和评审意见进行评估。具体的参数设置、损失函数和网络结构等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
InnoEval在逐点、成对和分组评估任务中均优于基线方法,展现出与人类专家高度一致的判断模式和共识。具体性能数据和提升幅度在摘要中未明确给出,属于未知信息。但实验结果表明,InnoEval能够有效提高科研idea评估的准确性和可靠性。
🎯 应用场景
InnoEval可应用于科研项目立项评估、学术论文评审、创新竞赛评审等领域。通过提供更全面、客观的评估结果,帮助决策者选择更有潜力的科研idea,促进科技创新。未来,该框架有望集成到科研管理平台,提升科研效率和质量。
📄 摘要(原文)
The rapid evolution of Large Language Models has catalyzed a surge in scientific idea production, yet this leap has not been accompanied by a matching advance in idea evaluation. The fundamental nature of scientific evaluation needs knowledgeable grounding, collective deliberation, and multi-criteria decision-making. However, existing idea evaluation methods often suffer from narrow knowledge horizons, flattened evaluation dimensions, and the inherent bias in LLM-as-a-Judge. To address these, we regard idea evaluation as a knowledge-grounded, multi-perspective reasoning problem and introduce InnoEval, a deep innovation evaluation framework designed to emulate human-level idea assessment. We apply a heterogeneous deep knowledge search engine that retrieves and grounds dynamic evidence from diverse online sources. We further achieve review consensus with an innovation review board containing reviewers with distinct academic backgrounds, enabling a multi-dimensional decoupled evaluation across multiple metrics. We construct comprehensive datasets derived from authoritative peer-reviewed submissions to benchmark InnoEval. Experiments demonstrate that InnoEval can consistently outperform baselines in point-wise, pair-wise, and group-wise evaluation tasks, exhibiting judgment patterns and consensus highly aligned with human experts.