Detecting LLM Hallucinations via Embedding Cluster Geometry: A Three-Type Taxonomy with Measurable Signatures
作者: Matic Korun
分类: cs.CL
发布日期: 2026-02-15
备注: 9 pages, 5 figures
💡 一句话要点
通过嵌入聚类几何结构检测LLM幻觉,提出可测量特征的三种类型分类法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉检测 嵌入聚类 几何分析 Transformer模型
📋 核心要点
- 现有方法难以有效区分和检测大语言模型中不同类型的幻觉现象,缺乏细粒度的理解。
- 该论文提出基于token嵌入聚类几何结构的三种幻觉类型分类法,并定义了可测量的几何统计量。
- 实验结果表明,提出的几何统计量能够有效区分不同类型的幻觉,并揭示了模型架构与幻觉脆弱性之间的关系。
📝 摘要(中文)
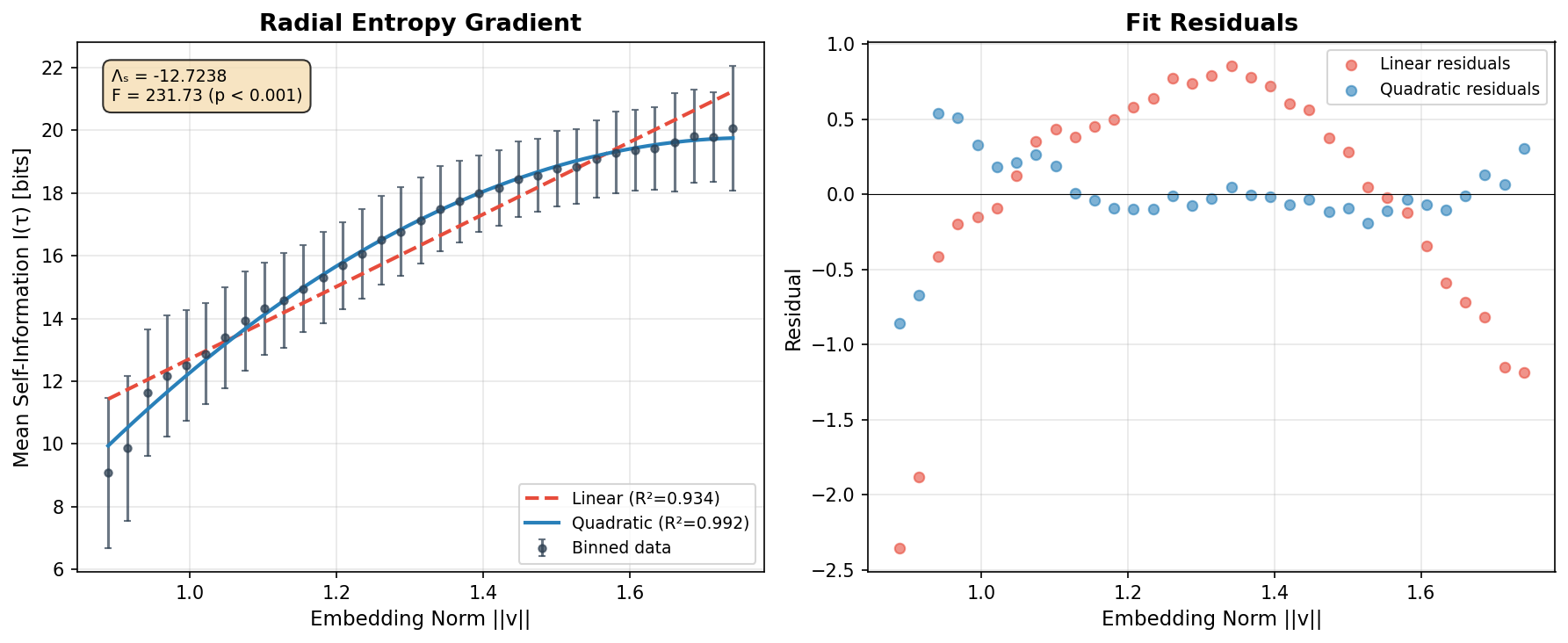
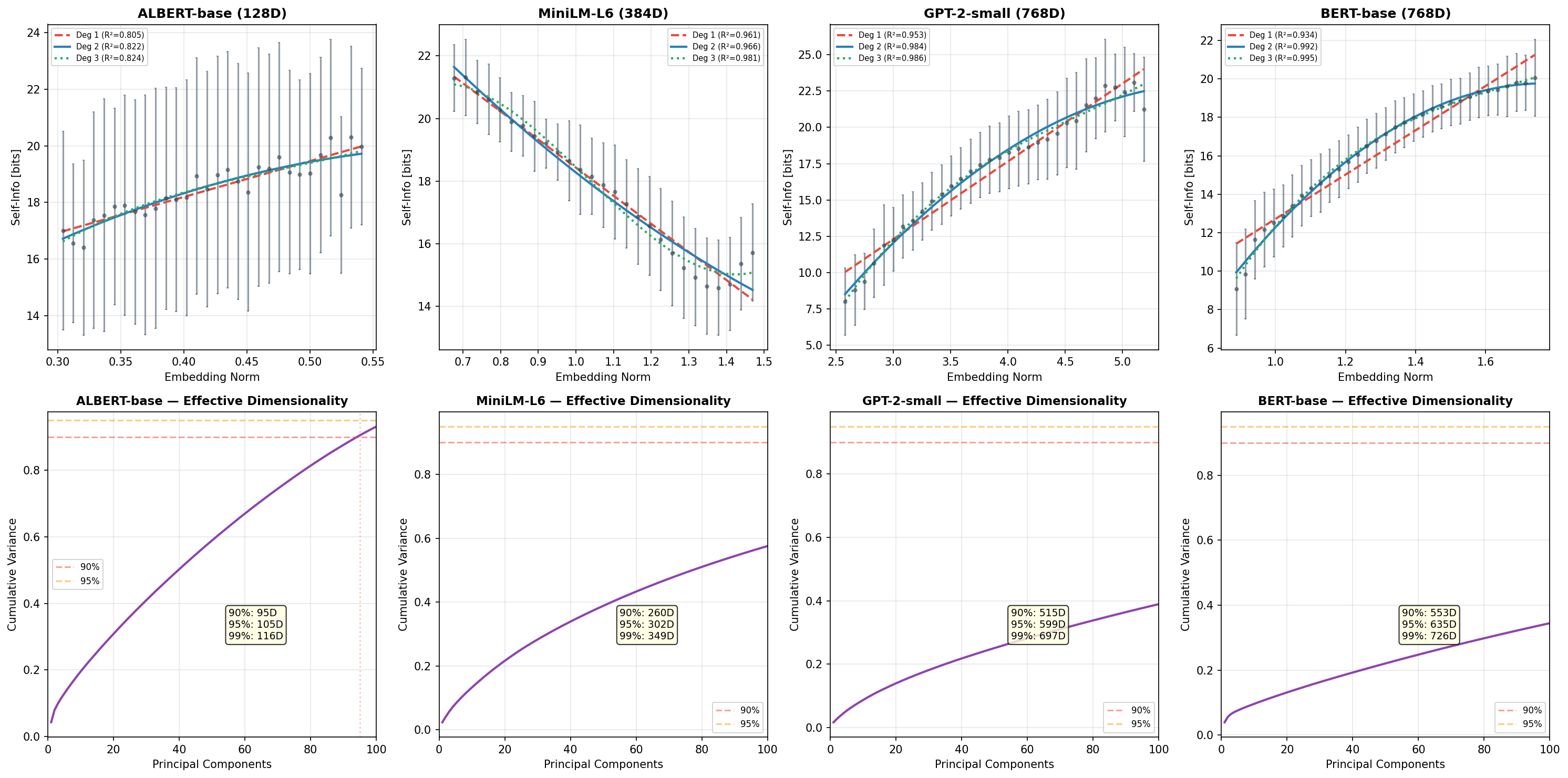
本文提出了一种基于token嵌入聚类结构中可观察特征的大语言模型幻觉几何分类法。通过分析11个Transformer模型的静态嵌入空间,这些模型涵盖了编码器(BERT、RoBERTa、ELECTRA、DeBERTa、ALBERT、MiniLM、DistilBERT)和解码器(GPT-2)架构,我们识别出三种在操作上不同的幻觉类型:类型1(中心漂移)在弱上下文下发生,类型2(错误良好收敛)收敛到局部连贯但上下文不正确的聚类区域,以及类型3(覆盖缺口),即不存在聚类结构。我们引入了三个可测量的几何统计量:α(极性耦合)、β(聚类内聚)和λ_s(径向信息梯度)。在所有11个模型中,极性结构(α > 0.5)是普遍存在的(11/11),聚类内聚(β > 0)是普遍存在的(11/11),并且径向信息梯度是显著的(9/11,p < 0.05)。我们证明了两个未能通过λ_s显著性检验的模型——ALBERT和MiniLM——是由于架构上可解释的原因:分别是因子分解嵌入压缩和蒸馏引起的各向同性。这些发现确立了特定类型幻觉检测的几何先决条件,并产生了关于架构依赖性脆弱性特征的可测试预测。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)中幻觉现象的检测和分类问题。现有的方法通常将幻觉视为一个整体,缺乏对不同类型幻觉的细致区分和理解,难以针对性地进行缓解。此外,现有方法往往依赖于外部知识或人工标注,成本较高且难以推广。
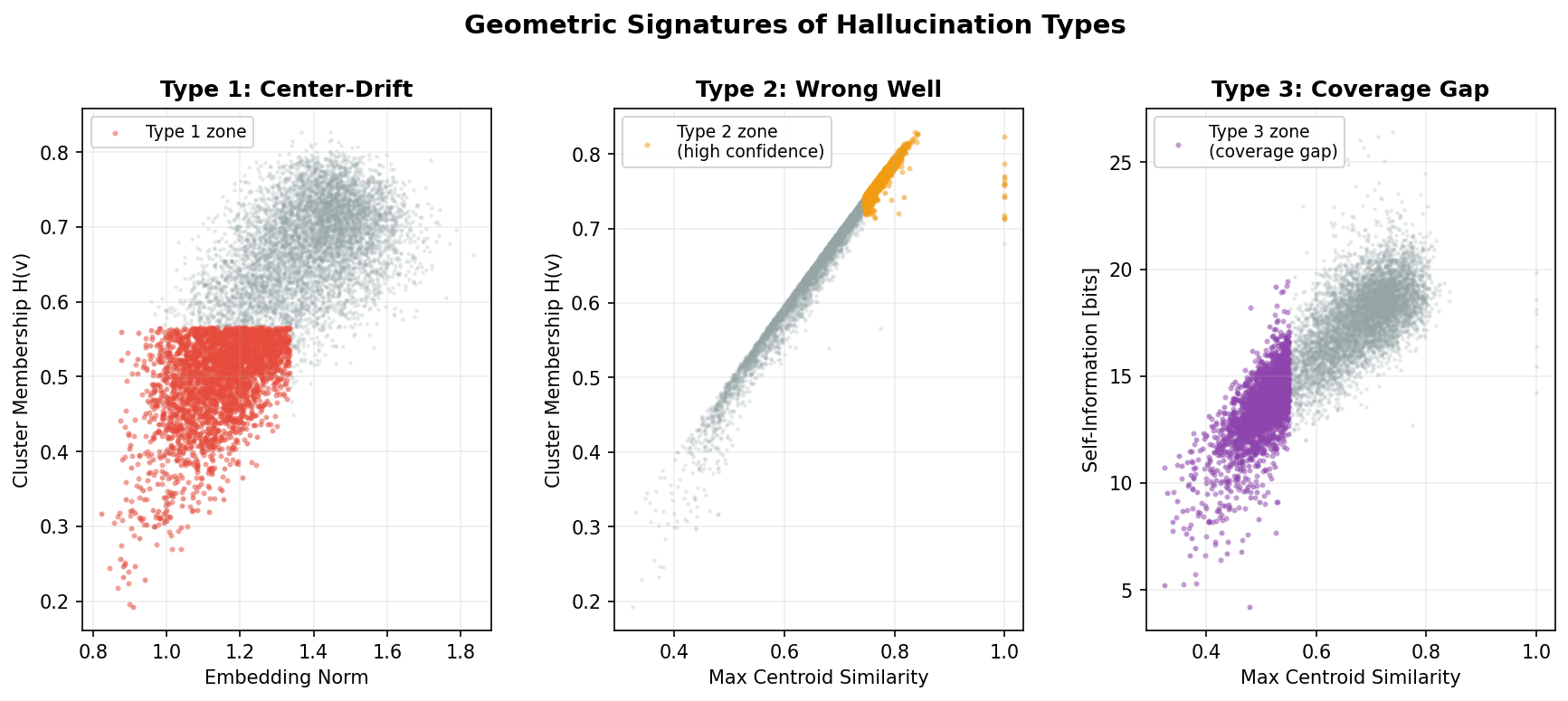
核心思路:论文的核心思路是利用LLM的token嵌入空间中的几何结构来区分不同类型的幻觉。作者认为,不同类型的幻觉会在嵌入空间中留下不同的“痕迹”,例如聚类中心的偏移、收敛到错误的聚类区域以及缺乏聚类结构等。通过分析这些几何特征,可以有效地识别和分类幻觉。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选取多个具有代表性的Transformer模型,包括编码器(BERT等)和解码器(GPT-2)架构;2) 分析这些模型的静态嵌入空间,提取token嵌入的聚类结构;3) 定义三个可测量的几何统计量:α(极性耦合)、β(聚类内聚)和λ_s(径向信息梯度),用于量化嵌入空间的几何特征;4) 基于这些几何统计量,将幻觉分为三种类型:中心漂移、错误良好收敛和覆盖缺口;5) 分析模型架构与几何统计量之间的关系,揭示模型架构对幻觉脆弱性的影响。
关键创新:论文最重要的技术创新点在于提出了基于嵌入聚类几何结构的幻觉分类法。与现有方法相比,该方法无需外部知识或人工标注,而是直接利用模型自身的嵌入空间信息,更加高效和可扩展。此外,该方法还能够区分不同类型的幻觉,为针对性地缓解幻觉问题提供了新的思路。
关键设计:论文的关键设计包括:1) 定义了三个几何统计量(α、β和λ_s),用于量化嵌入空间的几何特征。这些统计量能够有效地捕捉不同类型幻觉在嵌入空间中留下的“痕迹”;2) 选择了多个具有代表性的Transformer模型,涵盖了不同的架构和训练方式,保证了研究结果的普适性;3) 分析了模型架构与几何统计量之间的关系,揭示了模型架构对幻觉脆弱性的影响。例如,ALBERT和MiniLM未能通过λ_s显著性检验,作者分析了其原因分别是因子分解嵌入压缩和蒸馏引起的各向同性。
🖼️ 关键图片
📊 实验亮点
该研究通过分析11个Transformer模型的嵌入空间,发现极性结构(α > 0.5)和聚类内聚(β > 0)在所有模型中普遍存在。径向信息梯度(λ_s)在9/11的模型中显著(p < 0.05)。ALBERT和MiniLM未能通过λ_s显著性检验,作者从架构角度解释了其原因,验证了几何统计量与模型架构之间的关联。
🎯 应用场景
该研究成果可应用于提高大语言模型的可靠性和安全性。通过检测和分类幻觉,可以针对性地进行模型优化和改进,减少模型生成错误信息的可能性。此外,该研究还可以用于评估不同模型架构的幻觉脆弱性,为模型选择和设计提供指导。潜在的应用领域包括智能客服、自动写作、机器翻译等。
📄 摘要(原文)
We propose a geometric taxonomy of large language model hallucinations based on observable signatures in token embedding cluster structure. By analyzing the static embedding spaces of 11 transformer models spanning encoder (BERT, RoBERTa, ELECTRA, DeBERTa, ALBERT, MiniLM, DistilBERT) and decoder (GPT-2) architectures, we identify three operationally distinct hallucination types: Type 1 (center-drift) under weak context, Type 2 (wrong-well convergence) to locally coherent but contextually incorrect cluster regions, and Type 3 (coverage gaps) where no cluster structure exists. We introduce three measurable geometric statistics: α (polarity coupling), \b{eta} (cluster cohesion), and λ_s (radial information gradient). Across all 11 models, polarity structure (α > 0.5) is universal (11/11), cluster cohesion (\b{eta} > 0) is universal (11/11), and the radial information gradient is significant (9/11, p < 0.05). We demonstrate that the two models failing λ_s significance -- ALBERT and MiniLM -- do so for architecturally explicable reasons: factorized embedding compression and distillation-induced isotropy, respectively. These findings establish the geometric prerequisites for type-specific hallucination detection and yield testable predictions about architecture-dependent vulnerability profiles.