Knowing When Not to Answer: Abstention-Aware Scientific Reasoning
作者: Samir Abdaljalil, Erchin Serpedin, Hasan Kurban
分类: cs.CL, cs.AI
发布日期: 2026-02-15
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种基于拒绝回答的科学推理框架,提升科学结论的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学推理 自然语言推理 拒绝回答 证据审核 大型语言模型
📋 核心要点
- 现有科学推理评估通常要求模型必须给出明确答案,忽略了不确定结论的潜在危害。
- 论文提出一种基于拒绝回答的科学推理框架,通过分解条件和证据审核,选择性地支持、反驳或拒绝回答。
- 实验表明,拒绝回答机制在控制错误方面至关重要,即使在准确率提升有限的情况下也能显著降低风险。
📝 摘要(中文)
大型语言模型越来越多地被用于回答和验证科学主张,但现有的评估通常假设模型必须总是给出一个明确的答案。然而,在科学环境中,不支持或不确定的结论可能比拒绝回答更有害。本文研究了这个问题,提出了一个基于拒绝回答的验证框架,该框架将科学主张分解为最小条件,使用自然语言推理(NLI)针对现有证据审核每个条件,并有选择地决定是否支持、反驳或拒绝回答。我们在两个互补的科学基准测试SciFact和PubMedQA上评估了这个框架,涵盖了封闭域和开放域证据设置。实验使用了六个不同的语言模型,包括编码器-解码器、开源聊天模型和专有API。在所有基准测试和模型中,我们观察到原始准确率在不同架构之间变化不大,而拒绝回答在控制错误方面起着关键作用。特别是,基于置信度的拒绝回答在适度的覆盖率水平上显著降低了风险,即使绝对准确率的提高有限。我们的结果表明,在科学推理任务中,主要的挑战不是选择一个最佳模型,而是确定现有证据是否足以证明答案的合理性。这项工作强调了拒绝回答感知评估作为评估科学可靠性的实用且与模型无关的视角,并为未来在科学领域进行选择性推理的工作提供了统一的实验基础。
🔬 方法详解
问题定义:现有的大型语言模型在科学推理任务中,通常被期望给出明确的答案,而忽略了当证据不足或结论不确定时,给出错误答案的风险。现有的评估方法也缺乏对模型拒绝回答能力的考量,导致模型在不确定情况下仍然倾向于给出答案,从而降低了科学结论的可靠性。
核心思路:本文的核心思路是引入“拒绝回答”机制,允许模型在证据不足以支持或反驳某个科学主张时,选择不给出明确的答案。通过这种方式,可以避免模型在不确定情况下给出错误的结论,从而提高科学推理的可靠性。这种方法的核心在于判断何时应该拒绝回答,以及如何有效地利用现有证据进行判断。
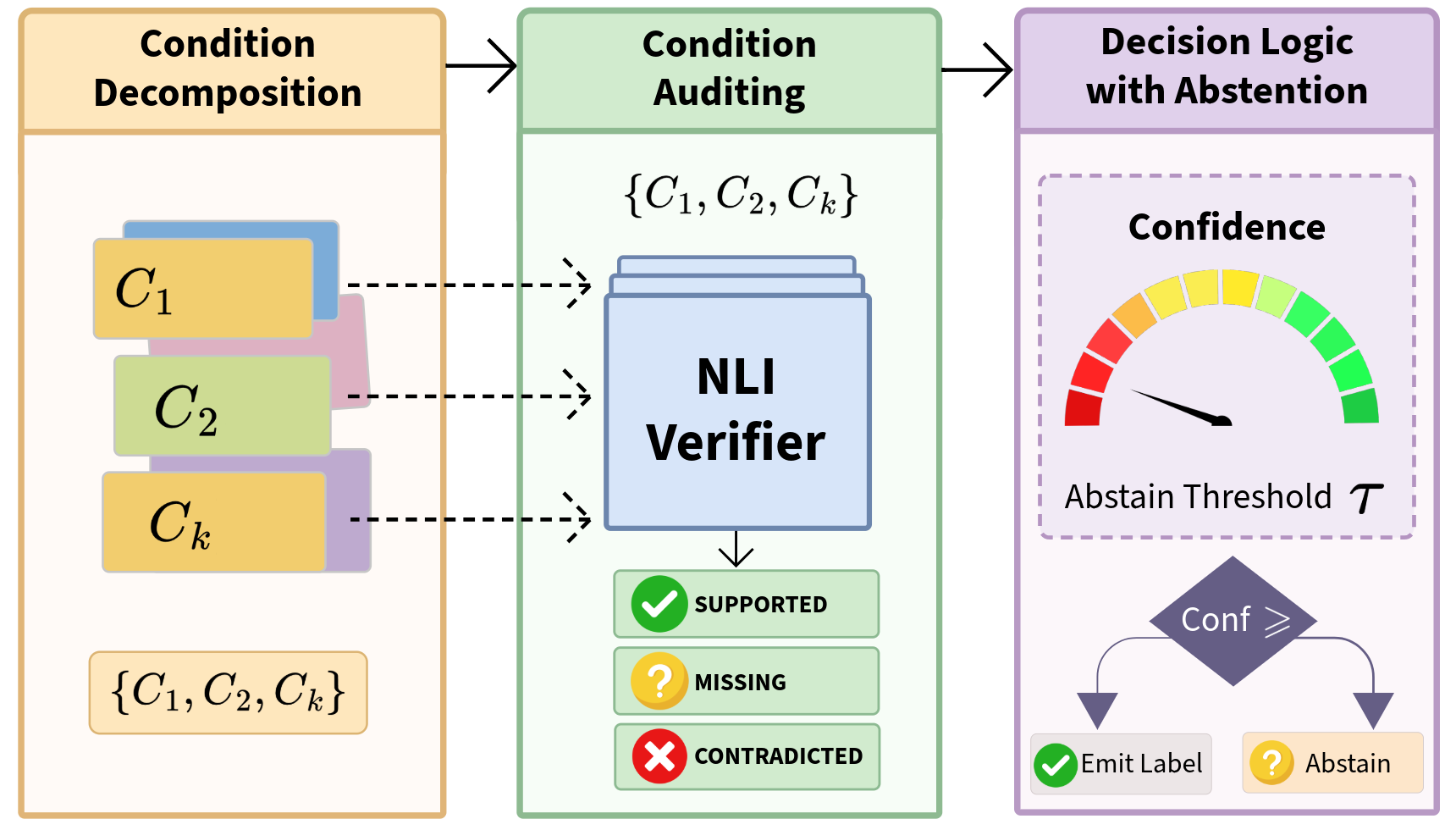
技术框架:该框架主要包含以下几个阶段:1) 科学主张分解:将复杂的科学主张分解为一系列最小的、可验证的条件。2) 证据审核:针对每个条件,利用自然语言推理(NLI)模型,将条件与可用的证据进行比对,判断证据是否支持、反驳或与条件无关。3) 决策:基于证据审核的结果,决定是否支持、反驳或拒绝回答原始的科学主张。如果证据不足以支持或反驳所有条件,则选择拒绝回答。
关键创新:该方法最重要的创新点在于引入了拒绝回答机制,并将其与自然语言推理相结合,形成了一个完整的科学推理框架。与传统的科学推理方法相比,该方法能够更好地处理不确定性,避免给出错误的结论。此外,该框架具有模型无关性,可以与不同的语言模型结合使用。
关键设计:在证据审核阶段,使用了自然语言推理模型来判断证据与条件之间的关系。关键的设计在于如何选择合适的NLI模型,以及如何设置置信度阈值来决定是否拒绝回答。论文中使用了多种不同的语言模型,并探索了不同的置信度阈值,以评估框架的性能。此外,如何将分解后的条件与证据进行有效匹配也是一个关键的设计问题,需要考虑证据检索和信息抽取等技术。
🖼️ 关键图片
📊 实验亮点
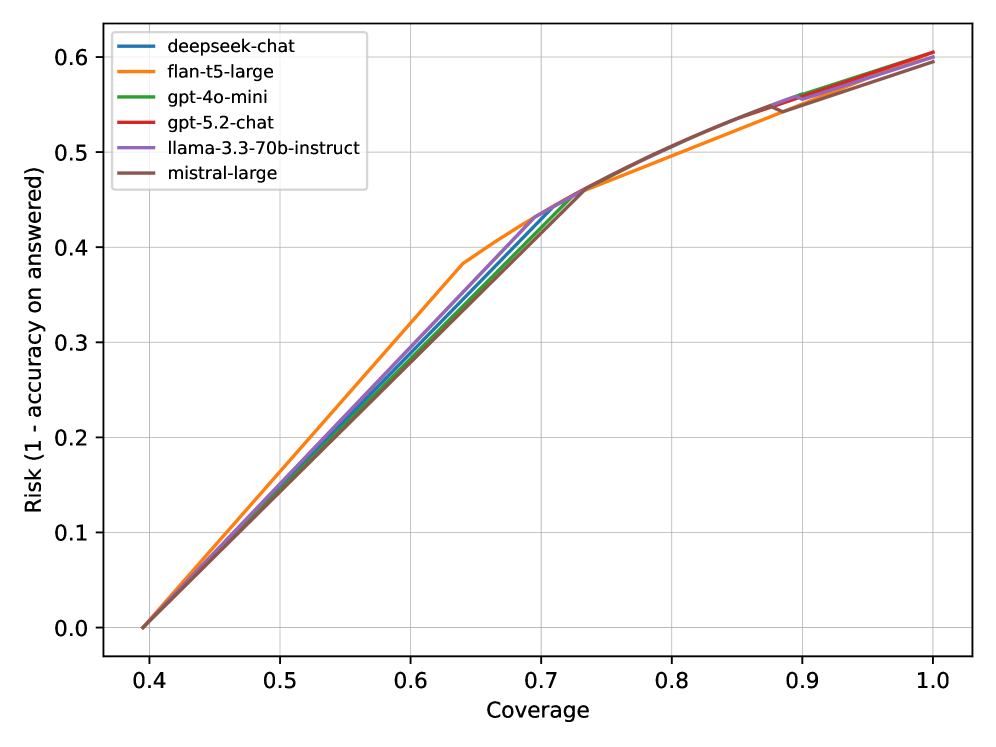
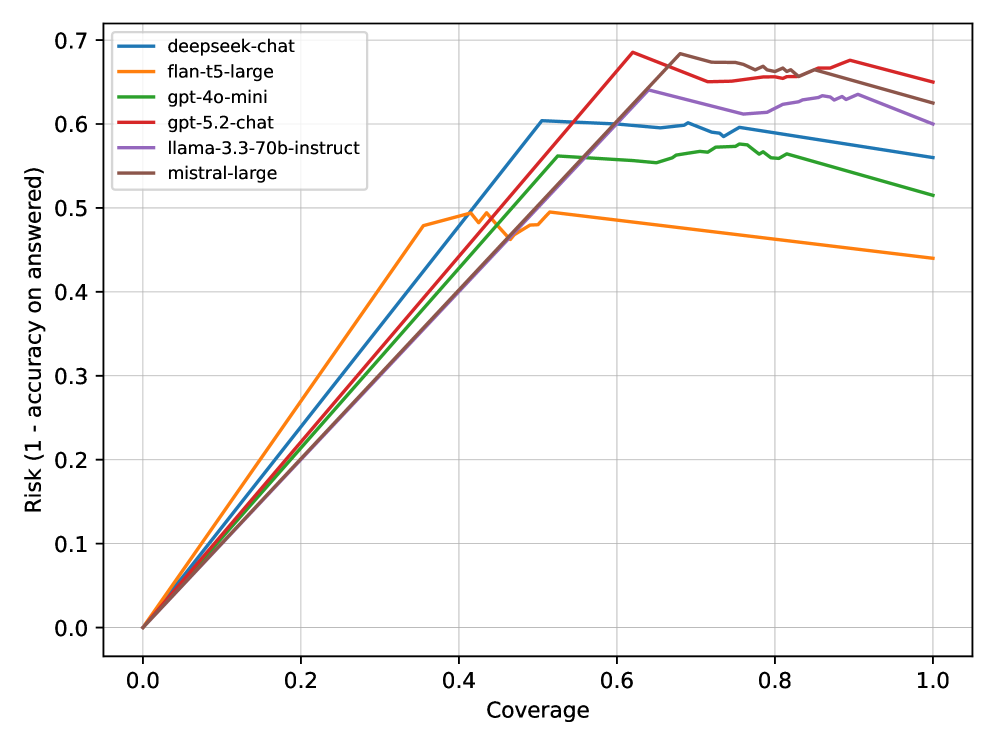
实验结果表明,引入拒绝回答机制后,即使在绝对准确率提升有限的情况下,也能显著降低风险。在SciFact和PubMedQA两个基准测试中,基于置信度的拒绝回答在适度的覆盖率水平上,有效地控制了错误率。实验对比了多种不同的语言模型,包括编码器-解码器、开源聊天模型和专有API,验证了该框架的通用性和有效性。
🎯 应用场景
该研究成果可应用于多个领域,例如:辅助科研人员进行文献综述和科学假设验证,提高科研效率;用于智能问答系统,提供更可靠的科学信息;应用于医疗诊断领域,辅助医生进行疾病诊断和治疗方案选择。通过引入拒绝回答机制,可以有效降低错误结论的风险,提高相关应用的可靠性和安全性。
📄 摘要(原文)
Large language models are increasingly used to answer and verify scientific claims, yet existing evaluations typically assume that a model must always produce a definitive answer. In scientific settings, however, unsupported or uncertain conclusions can be more harmful than abstaining. We study this problem through an abstention-aware verification framework that decomposes scientific claims into minimal conditions, audits each condition against available evidence using natural language inference (NLI), and selectively decides whether to support, refute, or abstain. We evaluate this framework across two complementary scientific benchmarks: SciFact and PubMedQA, covering both closed-book and open-domain evidence settings. Experiments are conducted with six diverse language models, including encoder-decoder, open-weight chat models, and proprietary APIs. Across all benchmarks and models, we observe that raw accuracy varies only modestly across architectures, while abstention plays a critical role in controlling error. In particular, confidence-based abstention substantially reduces risk at moderate coverage levels, even when absolute accuracy improvements are limited. Our results suggest that in scientific reasoning tasks, the primary challenge is not selecting a single best model, but rather determining when available evidence is sufficient to justify an answer. This work highlights abstention-aware evaluation as a practical and model-agnostic lens for assessing scientific reliability, and provides a unified experimental basis for future work on selective reasoning in scientific domains. Code is available at https://github.com/sabdaljalil2000/ai4science .