GPT-5 vs Other LLMs in Long Short-Context Performance
作者: Nima Esmi, Maryam Nezhad-Moghaddam, Fatemeh Borhani, Asadollah Shahbahrami, Amin Daemdoost, Georgi Gaydadjiev
分类: cs.CL, cs.AI, cs.HC
发布日期: 2026-02-15
备注: 10 pages, 7 figures. Accepted for publication in the 3rd International Conference on Foundation and Large Language Models (FLLM2025). IEEE. The final version will be available in IEEE Xplore
💡 一句话要点
评估GPT-5等LLM在长短上下文社交媒体抑郁检测中的性能退化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 大语言模型 性能评估 社交媒体分析 抑郁症检测
📋 核心要点
- 现有大语言模型在长文本处理中,理论上能处理百万tokens,但实际应用中对长上下文信息的利用能力不足,尤其是在需要理解大量细节的任务中。
- 该研究通过构建包含社交媒体抑郁检测等任务的数据集,评估了Grok-4、GPT-4、Gemini 2.5和GPT-5等模型在长短上下文任务中的性能表现。
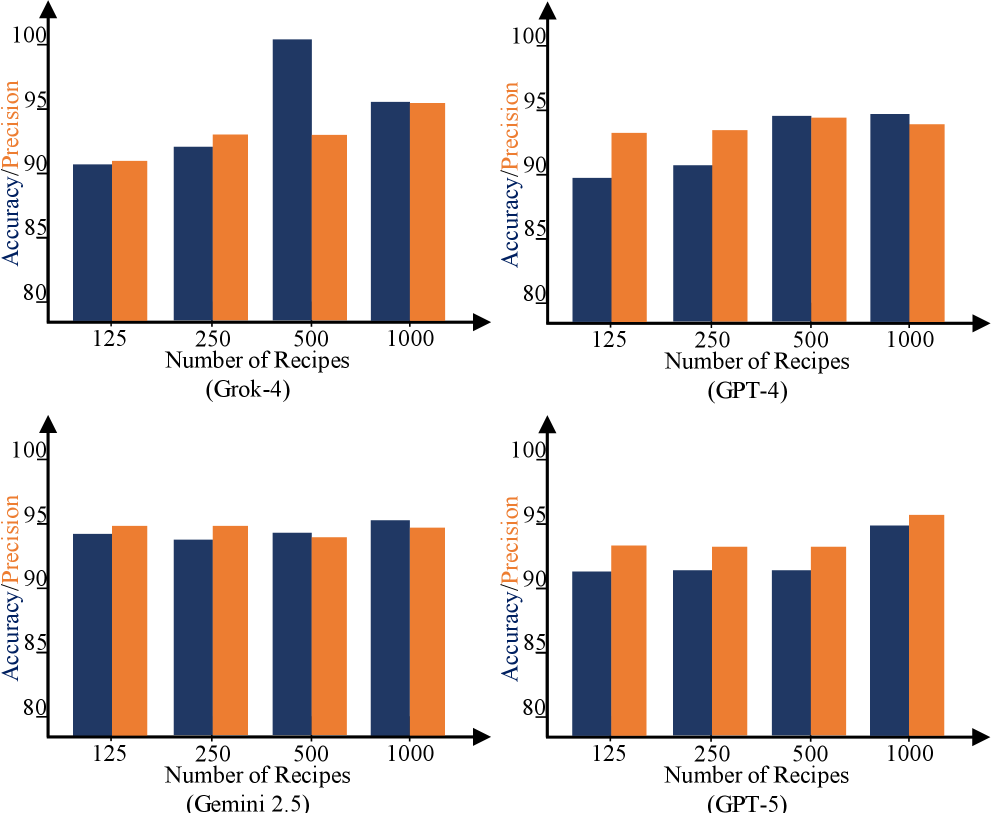
- 实验结果表明,随着输入文本长度增加,模型性能显著下降,但GPT-5在准确率下降的同时保持了较高的精确率,且“中间丢失”问题得到缓解。
📝 摘要(中文)
本文评估了四种先进的大语言模型(LLM):Grok-4、GPT-4、Gemini 2.5和GPT-5在长短上下文任务上的性能。研究使用了三个数据集,包括两个用于检索烹饪食谱和数学问题的补充数据集,以及一个包含2万条社交媒体帖子用于抑郁症检测的主数据集。结果表明,当社交媒体数据集的输入量超过5000条帖子(7万个tokens)时,所有模型的性能都会显著下降,对于2万条帖子,准确率降至50-53%左右。值得注意的是,在GPT-5模型中,尽管准确率急剧下降,但其精确率仍保持在约95%的高水平,这对于抑郁症检测等敏感应用可能非常有效。该研究还表明,较新的模型在很大程度上解决了“中间丢失”问题。这项研究强调了模型在复杂、高容量数据任务中的理论能力与实际性能之间的差距,并强调了超越简单准确率的指标对于实际应用的重要性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在处理长上下文信息时,特别是在社交媒体抑郁症检测任务中的性能表现。现有LLM虽然理论上可以处理非常长的文本序列,但实际应用中,它们在理解和利用长文本中的信息方面存在局限性,尤其是在需要综合多个细节的任务中,性能会显著下降。
核心思路:论文的核心思路是通过构建包含不同长度上下文的数据集,特别是社交媒体帖子数据集,来测试和比较不同LLM在长短上下文条件下的性能。通过分析模型在不同输入长度下的准确率、精确率等指标,揭示模型在处理长文本时存在的挑战和优势。
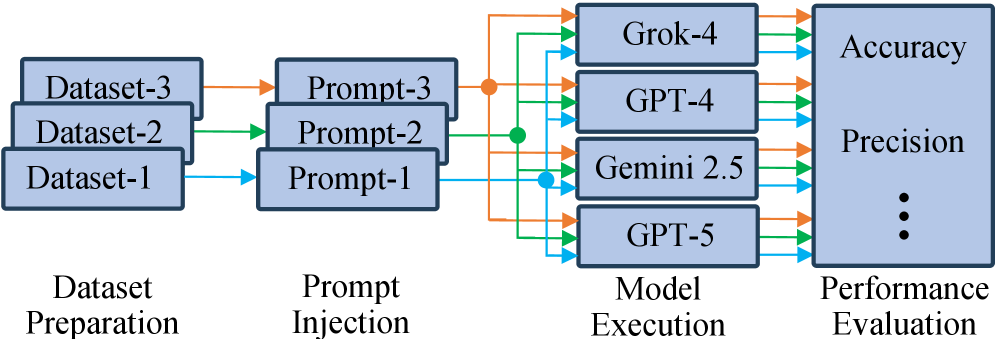
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择和准备数据集,包括烹饪食谱、数学问题和社交媒体帖子;2) 选择待评估的LLM,包括Grok-4、GPT-4、Gemini 2.5和GPT-5;3) 使用不同长度的上下文作为输入,让LLM执行特定任务,如抑郁症检测;4) 评估模型的性能指标,如准确率、精确率等;5) 分析实验结果,比较不同模型在不同上下文长度下的性能差异。
关键创新:该研究的关键创新在于:1) 针对长上下文性能评估,构建了包含真实社交媒体数据的抑郁症检测数据集;2) 细致地分析了不同LLM在长上下文条件下的性能退化情况,并揭示了GPT-5在准确率下降时仍能保持较高精确率的特点;3) 验证了较新的模型在一定程度上解决了“中间丢失”问题。
关键设计:在实验设计方面,论文使用了包含2万条社交媒体帖子的数据集,并逐步增加输入文本的长度,以观察模型性能的变化。对于抑郁症检测任务,模型需要判断社交媒体帖子是否表达了抑郁情绪。性能指标包括准确率和精确率,用于评估模型的整体性能和在敏感应用中的可靠性。没有提及具体的损失函数或网络结构细节。
🖼️ 关键图片
📊 实验亮点
实验结果显示,当输入超过5000条社交媒体帖子(7万tokens)时,所有模型的准确率显著下降,降至50-53%。但GPT-5的精确率保持在95%左右,表明其在长文本处理中仍具有一定的优势,尤其是在需要高精确率的敏感应用中。同时,研究表明新模型在一定程度上缓解了“中间丢失”问题。
🎯 应用场景
该研究成果可应用于提升社交媒体平台的情感分析和心理健康监测能力。通过优化LLM在长文本处理方面的性能,可以更准确地识别用户发布的抑郁情绪,从而为用户提供及时的心理健康支持和干预。此外,该研究也为LLM在其他需要处理长文本信息的领域,如法律文档分析、金融报告解读等,提供了有价值的参考。
📄 摘要(原文)
With the significant expansion of the context window in Large Language Models (LLMs), these models are theoretically capable of processing millions of tokens in a single pass. However, research indicates a significant gap between this theoretical capacity and the practical ability of models to robustly utilize information within long contexts, especially in tasks that require a comprehensive understanding of numerous details. This paper evaluates the performance of four state-of-the-art models (Grok-4, GPT-4, Gemini 2.5, and GPT-5) on long short-context tasks. For this purpose, three datasets were used: two supplementary datasets for retrieving culinary recipes and math problems, and a primary dataset of 20K social media posts for depression detection. The results show that as the input volume on the social media dataset exceeds 5K posts (70K tokens), the performance of all models degrades significantly, with accuracy dropping to around 50-53% for 20K posts. Notably, in the GPT-5 model, despite the sharp decline in accuracy, its precision remained high at approximately 95%, a feature that could be highly effective for sensitive applications like depression detection. This research also indicates that the "lost in the middle" problem has been largely resolved in newer models. This study emphasizes the gap between the theoretical capacity and the actual performance of models on complex, high-volume data tasks and highlights the importance of metrics beyond simple accuracy for practical applications.