CCiV: A Benchmark for Structure, Rhythm and Quality in LLM-Generated Chinese \textit{Ci} Poetry
作者: Shangqing Zhao, Yupei Ren, Yuhao Zhou, Xiaopeng Bai, Man Lan
分类: cs.CL
发布日期: 2026-02-15
备注: ARR 2025 May and Icassp 2026 submission. Working in progress
💡 一句话要点
CCiV:构建中文词牌诗生成基准,评估LLM在结构、韵律和质量上的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 中文词牌诗生成 大型语言模型 评估基准 结构韵律 形式感知提示
📋 核心要点
- 现有方法难以兼顾词牌诗的结构、韵律和质量要求,对LLM提出了挑战。
- CCiV基准通过结构、韵律和质量三个维度评估LLM生成的词牌诗。
- 实验表明,形式感知的提示能提升强模型性能,但可能降低弱模型性能。
📝 摘要(中文)
本文提出了中文词牌诗变体(CCiV)基准,旨在系统性地评估和提升大型语言模型(LLM)生成词牌诗的能力,尤其是在结构严谨性、韵律和谐性和艺术质量这三个维度上的表现。该基准包含30个词牌,对17个LLM进行了评估,揭示了两个关键现象:模型经常生成有效的但出乎意料的历史变体,并且模型在音调模式上的遵循比结构规则更困难。研究还表明,形式感知的提示可以提高较强模型在结构和音调控制方面的能力,但可能会降低较弱模型的性能。最后,观察到样本中形式正确性和文学质量之间存在微弱且不一致的对齐关系。CCiV强调了变体感知评估和更全面的约束性创造生成方法的需求。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成高质量中文词牌诗方面的挑战。现有的方法难以同时满足词牌诗在结构、韵律和艺术质量上的严格要求,导致生成的结果往往不尽如人意。此外,缺乏一个专门的基准来系统性地评估和比较不同LLM在词牌诗生成方面的能力,阻碍了相关研究的进展。
核心思路:论文的核心思路是构建一个全面的评估基准(CCiV),该基准能够从结构、韵律和质量三个维度对LLM生成的词牌诗进行细致的评估。通过分析LLM在不同词牌上的表现,揭示其在结构规则、音调模式和艺术表达方面的优势和不足。同时,探索形式感知的提示方法,以提升LLM在词牌诗生成方面的控制能力。
技术框架:CCiV基准主要包含以下几个部分:1) 词牌选择:选取了30个具有代表性的词牌,涵盖了不同的结构和韵律模式。2) 模型评估:使用17个不同的LLM生成词牌诗,并使用自动和人工评估方法对生成结果进行评估。3) 维度分析:从结构、韵律和质量三个维度对生成结果进行分析,揭示LLM在不同维度上的表现。4) 提示策略:探索形式感知的提示策略,以提升LLM在结构和韵律控制方面的能力。
关键创新:论文的关键创新在于构建了一个专门用于评估LLM生成中文词牌诗的基准(CCiV)。该基准不仅考虑了词牌诗的结构和韵律要求,还关注了其艺术质量。此外,论文还提出了形式感知的提示策略,能够有效地提升LLM在结构和韵律控制方面的能力。
关键设计:在模型评估方面,论文采用了自动评估和人工评估相结合的方法。自动评估主要关注生成结果在结构和韵律上的正确性,而人工评估则侧重于评估生成结果的艺术质量。在形式感知的提示策略方面,论文设计了不同的提示模板,引导LLM生成符合特定结构和韵律要求的词牌诗。具体的参数设置和损失函数等技术细节在论文中没有详细描述。
🖼️ 关键图片


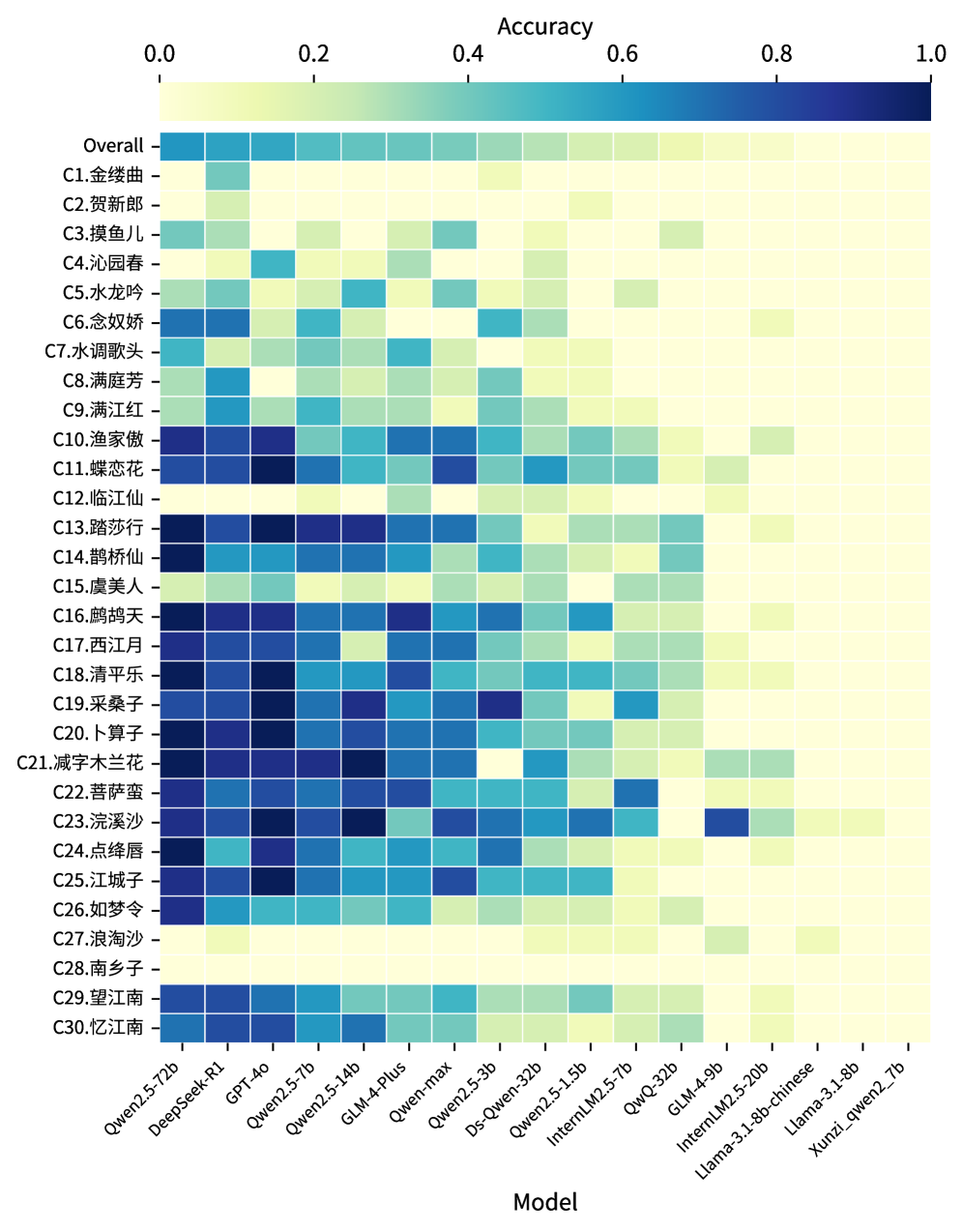
📊 实验亮点
实验结果表明,LLM在生成词牌诗时,音调模式的遵循比结构规则更困难。形式感知的提示可以提高较强模型在结构和音调控制方面的能力,但可能会降低较弱模型的性能。此外,研究还发现形式正确性和文学质量之间存在微弱且不一致的对齐关系,表明需要更全面的评估方法。
🎯 应用场景
该研究成果可应用于智能诗歌创作、传统文化教育、人机交互等领域。通过CCiV基准,可以更好地评估和提升LLM在诗歌生成方面的能力,为用户提供更优质的诗歌创作工具。同时,该研究也有助于促进传统文化的传承和发展,提高人们对古典诗词的兴趣和理解。
📄 摘要(原文)
The generation of classical Chinese \textit{Ci} poetry, a form demanding a sophisticated blend of structural rigidity, rhythmic harmony, and artistic quality, poses a significant challenge for large language models (LLMs). To systematically evaluate and advance this capability, we introduce \textbf{C}hinese \textbf{Ci}pai \textbf{V}ariants (\textbf{CCiV}), a benchmark designed to assess LLM-generated \textit{Ci} poetry across these three dimensions: structure, rhythm, and quality. Our evaluation of 17 LLMs on 30 \textit{Cipai} reveals two critical phenomena: models frequently generate valid but unexpected historical variants of a poetic form, and adherence to tonal patterns is substantially harder than structural rules. We further show that form-aware prompting can improve structural and tonal control for stronger models, while potentially degrading weaker ones. Finally, we observe weak and inconsistent alignment between formal correctness and literary quality in our sample. CCiV highlights the need for variant-aware evaluation and more holistic constrained creative generation methods.