Annotation-Efficient Vision-Language Model Adaptation to the Polish Language Using the LLaVA Framework
作者: Grzegorz Statkiewicz, Alicja Dobrzeniecka, Karolina Seweryn, Aleksandra Krasnodębska, Karolina Piosek, Katarzyna Bogusz, Sebastian Cygert, Wojciech Kusa
分类: cs.CL, cs.AI
发布日期: 2026-02-15 (更新: 2026-02-17)
💡 一句话要点
利用LLaVA框架,通过高效标注方法将视觉-语言模型适配到波兰语
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 多模态学习 低资源语言 机器翻译 数据增强
📋 核心要点
- 现有视觉-语言模型主要基于英语数据训练,导致其在其他语言和文化背景下表现不佳。
- 论文提出一种基于LLaVA-Next的自动翻译和过滤流程,并结合合成数据,高效构建波兰语视觉-语言模型。
- 实验结果表明,该方法在波兰语MMBench上性能提升9.5%,且生成字幕的语言质量更高。
📝 摘要(中文)
大多数视觉-语言模型(VLMs)都基于以英语为中心的数据进行训练,这限制了它们在其他语言和文化环境中的性能。这限制了非英语用户的使用,并阻碍了反映不同语言和文化现实的多模态系统的发展。本文复现并调整了LLaVA-Next方法,创建了一系列波兰语VLMs。我们依赖于一个全自动的流水线来翻译和过滤现有的多模态数据集,并用合成的波兰语数据来补充OCR和特定文化任务。尽管几乎完全依赖于自动翻译和最少的人工干预来训练数据,但我们的方法产生了强大的结果:在波兰语改编的MMBench上,我们观察到比LLaVA-1.6-Vicuna-13B提高了+9.5%,并且在生成评估中,根据人工标注者对语言正确性的衡量,获得了更高质量的字幕。这些发现表明,大规模自动翻译与轻量级过滤相结合,可以有效地引导低资源语言的高质量多模态模型。一些挑战仍然存在,特别是在文化覆盖和评估方面。为了促进进一步的研究,我们公开了我们的模型和评估数据集。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型在非英语,特别是波兰语环境下的性能瓶颈问题。现有方法依赖大量人工标注的非英语数据,成本高昂且效率低下。此外,现有模型在文化理解方面存在不足,难以适应特定文化背景下的任务。
核心思路:论文的核心思路是利用大规模自动翻译和轻量级过滤,将现有的英语多模态数据集转化为波兰语数据集,并结合少量合成数据进行训练。这种方法旨在降低对人工标注的依赖,提高模型训练效率,并提升模型在波兰语环境下的性能。
技术框架:整体框架基于LLaVA-Next,包含以下主要阶段:1) 数据翻译:使用机器翻译系统将英语多模态数据集翻译成波兰语。2) 数据过滤:采用自动和人工相结合的方式,对翻译后的数据进行过滤,去除质量较差的样本。3) 合成数据生成:生成包含OCR和文化特定信息的合成波兰语数据,以增强模型的泛化能力。4) 模型训练:使用翻译和合成的数据训练LLaVA模型。
关键创新:论文的关键创新在于提出了一种高效的、低成本的视觉-语言模型适配方法,该方法几乎完全依赖于自动翻译和最少的人工干预。这种方法显著降低了对人工标注数据的需求,使得将视觉-语言模型快速适配到低资源语言成为可能。
关键设计:论文的关键设计包括:1) 选择合适的机器翻译系统,以保证翻译质量。2) 设计有效的过滤策略,以去除翻译错误和噪声数据。3) 精心设计合成数据的生成方式,以覆盖OCR和文化特定信息。4) 采用LLaVA-Next框架,并针对波兰语的特点进行微调。
🖼️ 关键图片
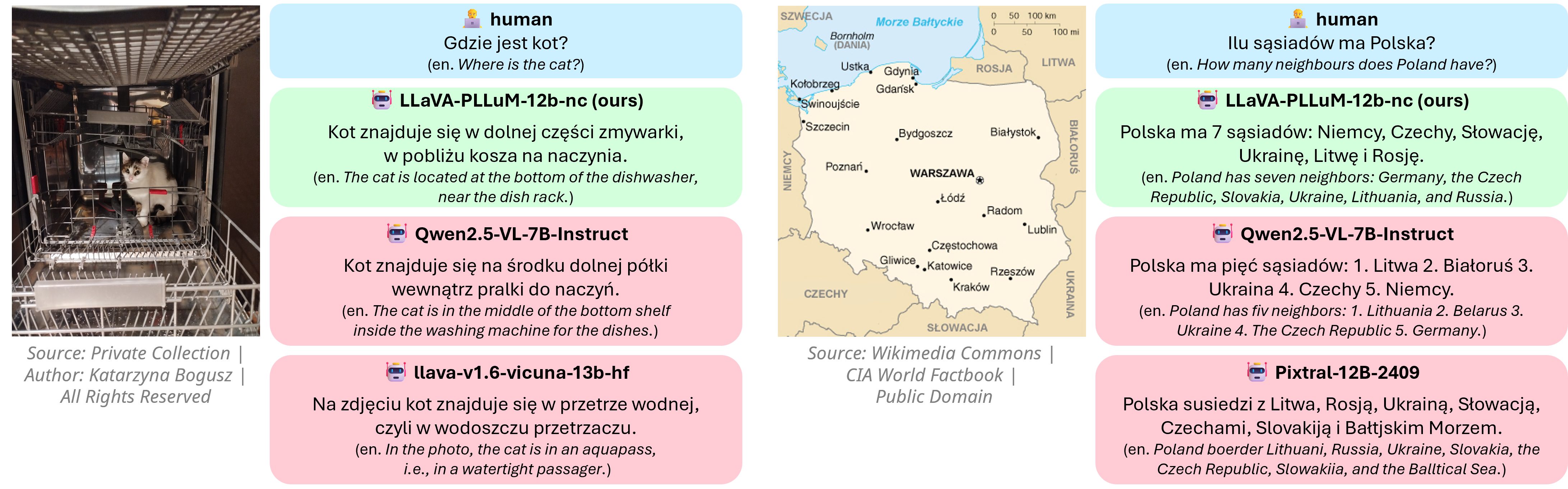
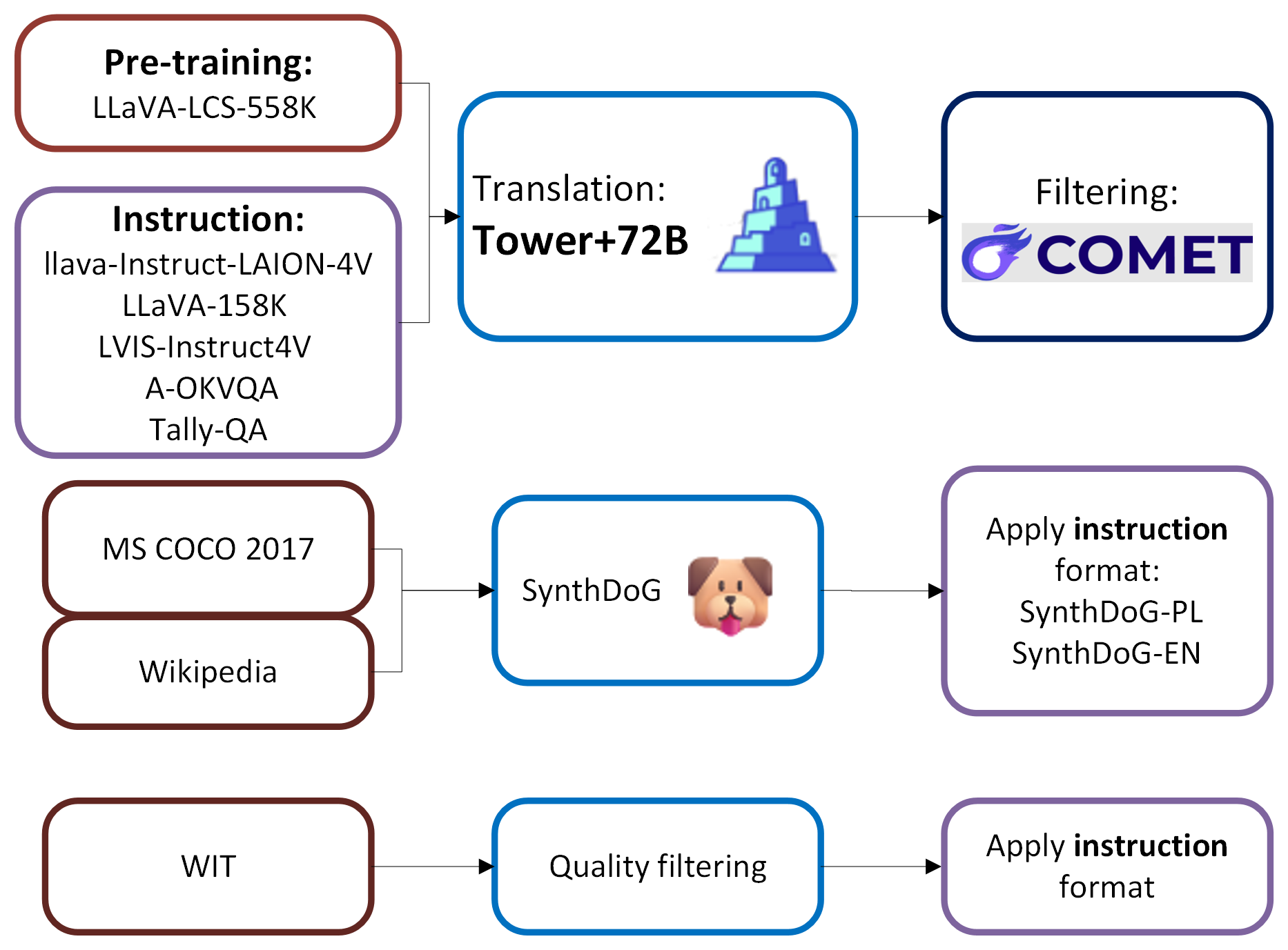
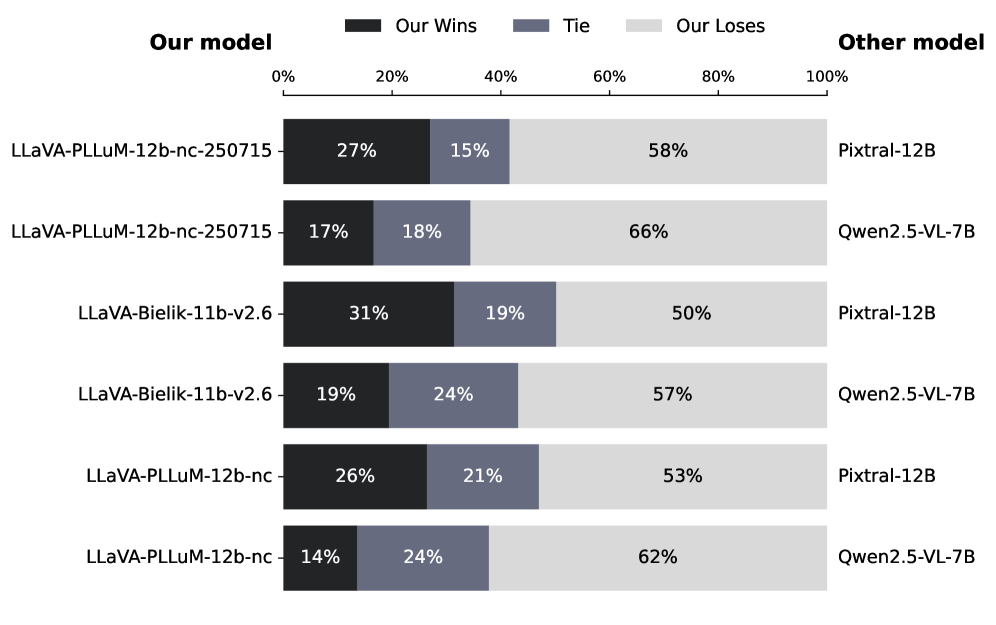
📊 实验亮点
实验结果表明,该方法在波兰语MMBench上取得了显著的性能提升,相比LLaVA-1.6-Vicuna-13B模型,性能提升了9.5%。此外,人工评估结果表明,该方法生成的字幕在语言正确性方面表现更好,证明了大规模自动翻译和轻量级过滤在低资源语言模型构建中的有效性。
🎯 应用场景
该研究成果可应用于多种场景,如波兰语地区的智能客服、图像描述、视觉问答等。通过低成本地构建高质量的波兰语视觉-语言模型,可以促进人工智能技术在波兰语地区的普及和应用,并为其他低资源语言的视觉-语言模型开发提供借鉴。
📄 摘要(原文)
Most vision-language models (VLMs) are trained on English-centric data, limiting their performance in other languages and cultural contexts. This restricts their usability for non-English-speaking users and hinders the development of multimodal systems that reflect diverse linguistic and cultural realities. In this work, we reproduce and adapt the LLaVA-Next methodology to create a set of Polish VLMs. We rely on a fully automated pipeline for translating and filtering existing multimodal datasets, and complement this with synthetic Polish data for OCR and culturally specific tasks. Despite relying almost entirely on automatic translation and minimal manual intervention to the training data, our approach yields strong results: we observe a +9.5% improvement over LLaVA-1.6-Vicuna-13B on a Polish-adapted MMBench, along with higher-quality captions in generative evaluations, as measured by human annotators in terms of linguistic correctness. These findings highlight that large-scale automated translation, combined with lightweight filtering, can effectively bootstrap high-quality multimodal models for low-resource languages. Some challenges remain, particularly in cultural coverage and evaluation. To facilitate further research, we make our models and evaluation dataset publicly available.