Open Rubric System: Scaling Reinforcement Learning with Pairwise Adaptive Rubric
作者: Ruipeng Jia, Yunyi Yang, Yuxin Wu, Yongbo Gai, Siyuan Tao, Mengyu Zhou, Jianhe Lin, Xiaoxi Jiang, Guanjun Jiang
分类: cs.CL
发布日期: 2026-02-15
💡 一句话要点
提出OpenRS,通过可检验的原则和自适应评分标准提升开放场景强化学习的鲁棒对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 奖励建模 开放场景 鲁棒对齐 评分标准 LLM-as-a-Judge 元学习
📋 核心要点
- 现有标量奖励模型存在信息瓶颈,导致开放场景对齐的脆弱性和奖励利用问题。
- OpenRS通过显式推理过程和可检验原则,将奖励视为可解释的评分标准,而非黑盒函数。
- OpenRS使用成对自适应元评分标准和逐点可验证评分标准,提升了开放场景中的辨别能力。
📝 摘要(中文)
标量奖励模型将多维人类偏好压缩成单一的不透明分数,造成信息瓶颈,这通常导致开放式对齐中的脆弱性和奖励利用。我们认为,对于不可验证任务的鲁棒对齐本质上是一个原则泛化问题:奖励不应是内化到评判者中的学习函数,而应是在可检查原则下执行的显式推理过程。为了实现这一观点,我们提出了开放评分系统(OpenRS),这是一个即插即用的、基于评分标准的LLM-as-a-Judge框架,围绕成对自适应元评分标准(PAMR)和轻量级逐点可验证评分标准(PVR)构建,当存在ground-truth或程序化检查时,它们提供硬约束护栏和可验证的奖励组件。OpenRS使用显式的元评分标准——一种类似章程的规范,用于管理评分标准的实例化、加权和执行——并通过调节两个候选响应之间的语义差异来动态地实例化自适应评分标准。然后,它执行标准方面的成对比较,并在外部聚合标准级别的偏好,避免逐点加权标量化,同时提高开放式设置中的可辨别性。为了保持原则的一致性和可编辑性,我们引入了一个两级元评分标准细化流程(用于一般原则的自动化进化细化和用于领域原则的可重复的人工参与流程),并辅以逐点可验证的评分标准,这些评分标准既可以作为防止退化行为的护栏,又可以作为客观子任务的可验证奖励来源。最后,我们将OpenRS实例化为成对RL训练中的奖励监督。
🔬 方法详解
问题定义:现有强化学习方法在开放场景中依赖标量奖励模型,该模型将复杂的人类偏好压缩成单一数值,导致信息损失和奖励利用。这种方法难以泛化到新的、未见过的场景,并且容易受到对抗性攻击,产生不符合人类期望的行为。因此,需要一种更鲁棒、可解释的奖励机制,能够更好地反映人类的价值观和目标。
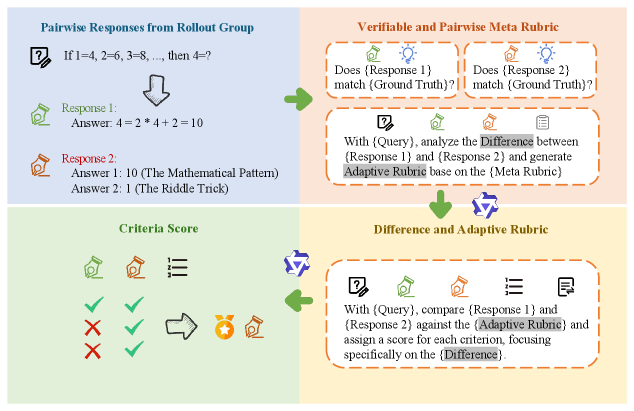
核心思路:OpenRS的核心思路是将奖励建模为一个显式的推理过程,而非一个黑盒函数。它通过定义一系列可解释的评分标准(rubrics),并根据这些标准对候选行为进行评估。这些评分标准可以根据具体任务进行调整,并且可以被人类审查和修改,从而提高奖励机制的可解释性和可信度。此外,OpenRS采用成对比较的方式,避免了直接对奖励进行标量化,从而保留了更多的信息。
技术框架:OpenRS包含以下主要模块:1) 元评分标准(Meta-Rubric):定义了评分标准实例化、加权和执行的规则,类似于宪法。2) 成对自适应元评分标准(PAMR):根据两个候选响应的语义差异,动态生成评分标准。3) 逐点可验证评分标准(PVR):提供硬约束护栏和可验证的奖励组件,用于客观子任务。4) 元评分标准细化流程:包括自动化进化细化(用于一般原则)和人工参与流程(用于领域原则)。OpenRS将这些模块集成到一个LLM-as-a-Judge框架中,用于成对RL训练中的奖励监督。
关键创新:OpenRS的关键创新在于其显式的、基于评分标准的奖励建模方法。与传统的标量奖励模型相比,OpenRS提供了更高的可解释性、可信度和鲁棒性。此外,OpenRS的成对比较方法避免了信息损失,提高了辨别能力。元评分标准细化流程保证了评分标准的一致性和可编辑性。
关键设计:OpenRS的关键设计包括:1) 元评分标准的定义:需要仔细设计元评分标准的结构和内容,以确保其能够有效地指导评分标准的实例化和执行。2) 成对自适应元评分标准的生成:需要选择合适的模型和算法,以根据候选响应的语义差异生成合适的评分标准。3) 逐点可验证评分标准的选择:需要根据具体任务选择合适的客观指标,并将其转化为可验证的评分标准。4) 元评分标准细化流程的实现:需要设计合适的自动化进化算法和人工参与流程,以保证评分标准的一致性和可编辑性。
🖼️ 关键图片
📊 实验亮点
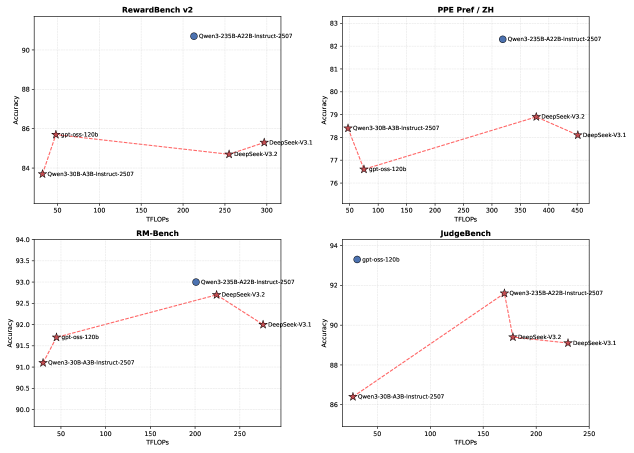
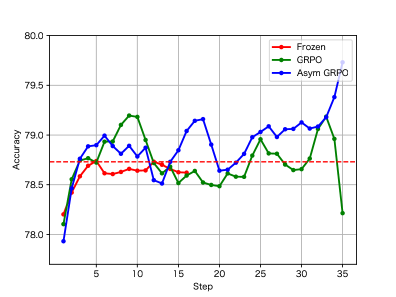
论文提出了OpenRS框架,通过可检验的原则和自适应评分标准提升了开放场景强化学习的鲁棒对齐。实验结果表明,OpenRS在各种开放式任务中取得了显著的性能提升,并且能够有效地防止奖励利用和对抗性攻击。具体的性能数据和对比基线信息在论文中详细展示。
🎯 应用场景
OpenRS可应用于各种需要鲁棒对齐的开放式任务,例如对话生成、代码生成、创意写作等。它能够提高AI系统的安全性、可靠性和可信度,并促进人机协作。未来,OpenRS可以扩展到更复杂的任务和领域,例如自动驾驶、医疗诊断等,为AI的广泛应用提供更可靠的基础。
📄 摘要(原文)
Scalar reward models compress multi-dimensional human preferences into a single opaque score, creating an information bottleneck that often leads to brittleness and reward hacking in open-ended alignment. We argue that robust alignment for non-verifiable tasks is fundamentally a principle generalization problem: reward should not be a learned function internalized into a judge, but an explicit reasoning process executed under inspectable principles. To operationalize this view, we present the Open Rubric System (OpenRS), a plug-and-play, rubrics-based LLM-as-a-Judge framework built around Pairwise Adaptive Meta-Rubrics (PAMR) and lightweight Pointwise Verifiable Rubrics (PVRs), which provide both hard-constraint guardrails and verifiable reward components when ground-truth or programmatic checks are available. OpenRS uses an explicit meta-rubric -- a constitution-like specification that governs how rubrics are instantiated, weighted, and enforced -- and instantiates adaptive rubrics on the fly by conditioning on the semantic differences between two candidate responses. It then performs criterion-wise pairwise comparisons and aggregates criterion-level preferences externally, avoiding pointwise weighted scalarization while improving discriminability in open-ended settings. To keep principles consistent yet editable across various domains, we introduce a two-level meta-rubric refinement pipeline (automated evolutionary refinement for general principles and a reproducible human-in-the-loop procedure for domain principles), complemented with pointwise verifiable rubrics that act as both guardrails against degenerate behaviors and a source of verifiable reward for objective sub-tasks. Finally, we instantiate OpenRS as reward supervision in pairwise RL training.