The Sufficiency-Conciseness Trade-off in LLM Self-Explanation from an Information Bottleneck Perspective
作者: Ali Zahedzadeh, Behnam Bahrak
分类: cs.CL, cs.AI
发布日期: 2026-02-15
备注: LREC 2026 submission; focuses on LLM self-explanation, interpretability, and information bottleneck analysis
💡 一句话要点
从信息瓶颈视角研究LLM自解释的充分性-简洁性权衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自解释性 信息瓶颈 充分性 简洁性 思维链 多步推理
📋 核心要点
- 现有LLM自解释方法生成的解释通常冗长且成本高昂,缺乏对解释必要性的深入研究。
- 论文基于信息瓶颈原理,将解释视为压缩表示,旨在保留生成正确答案的关键信息。
- 实验表明,在保证准确性的前提下,可以显著减少解释长度,但过度压缩会降低性能。
📝 摘要(中文)
大型语言模型(LLM)越来越多地依赖于自解释,例如思维链推理,以提高多步骤问答的性能。虽然这些解释提高了准确性,但它们通常冗长且生成成本高昂,这就提出了一个问题:究竟需要多少解释才是真正必要的?本文研究了充分性(定义为解释证明正确答案的能力)和简洁性(定义为解释长度的减少)之间的权衡。基于信息瓶颈原理,我们将解释概念化为压缩表示,仅保留生成正确答案所需的基本信息。为了实现这一观点,我们引入了一个评估流程,该流程约束了解释长度,并使用多个语言模型在ARC Challenge数据集上评估充分性。为了扩大范围,我们使用原始数据集在英语和波斯语(作为一种资源受限的语言,通过翻译)中进行了实验。我们的实验表明,更简洁的解释通常仍然是充分的,在保持准确性的同时显着减少了解释长度,而过度压缩会导致性能下降。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在自解释推理过程中,解释的冗余性和效率问题。现有方法生成的解释往往过于冗长,增加了计算成本,但并没有明确量化解释的必要性,即多少解释是“足够”的。因此,如何平衡解释的充分性(保证正确推理)和简洁性(减少计算成本)是本文要解决的核心问题。
核心思路:论文的核心思路是将LLM的自解释过程类比于信息瓶颈(Information Bottleneck, IB)原理。IB原理旨在找到一个变量的压缩表示,该表示尽可能保留关于另一个变量(目标变量)的信息。在这里,原始的、冗长的解释被视为原始变量,而简洁的解释则是压缩表示。目标是找到一个既能保证LLM正确回答问题(充分性),又能显著减少解释长度(简洁性)的解释。
技术框架:论文提出了一个评估流程来研究充分性-简洁性权衡。该流程主要包含以下几个步骤: 1. 生成解释:使用LLM(例如,通过思维链提示)生成原始的、冗长的解释。 2. 压缩解释:通过各种方法(例如,截断、摘要)来减少解释的长度,生成不同程度的压缩解释。 3. 评估充分性:使用另一个或多个LLM,基于压缩后的解释来回答问题,并评估答案的准确性。准确性越高,说明解释的充分性越好。 4. 评估简洁性:通过计算解释的长度(例如,token数量)来衡量简洁性。长度越短,说明解释越简洁。 5. 分析权衡:分析不同压缩程度下,充分性和简洁性之间的关系,找到最佳的平衡点。
关键创新:论文的关键创新在于将信息瓶颈原理应用于LLM的自解释研究,并提出了一个量化充分性和简洁性之间权衡的评估框架。这为理解和优化LLM的自解释能力提供了一个新的视角。与现有方法相比,该方法不仅关注提高解释的准确性,还关注降低解释的冗余性,从而提高效率。
关键设计:论文的关键设计包括: 1. 解释长度约束:通过设置不同的长度阈值来控制解释的压缩程度。 2. 充分性评估指标:使用LLM回答问题,并根据答案的正确性来评估解释的充分性。 3. 数据集选择:选择ARC Challenge数据集,因为它包含需要多步骤推理的复杂问题,适合评估自解释能力。 4. 多语言实验:在英语和波斯语上进行实验,以验证方法的泛化能力。
🖼️ 关键图片
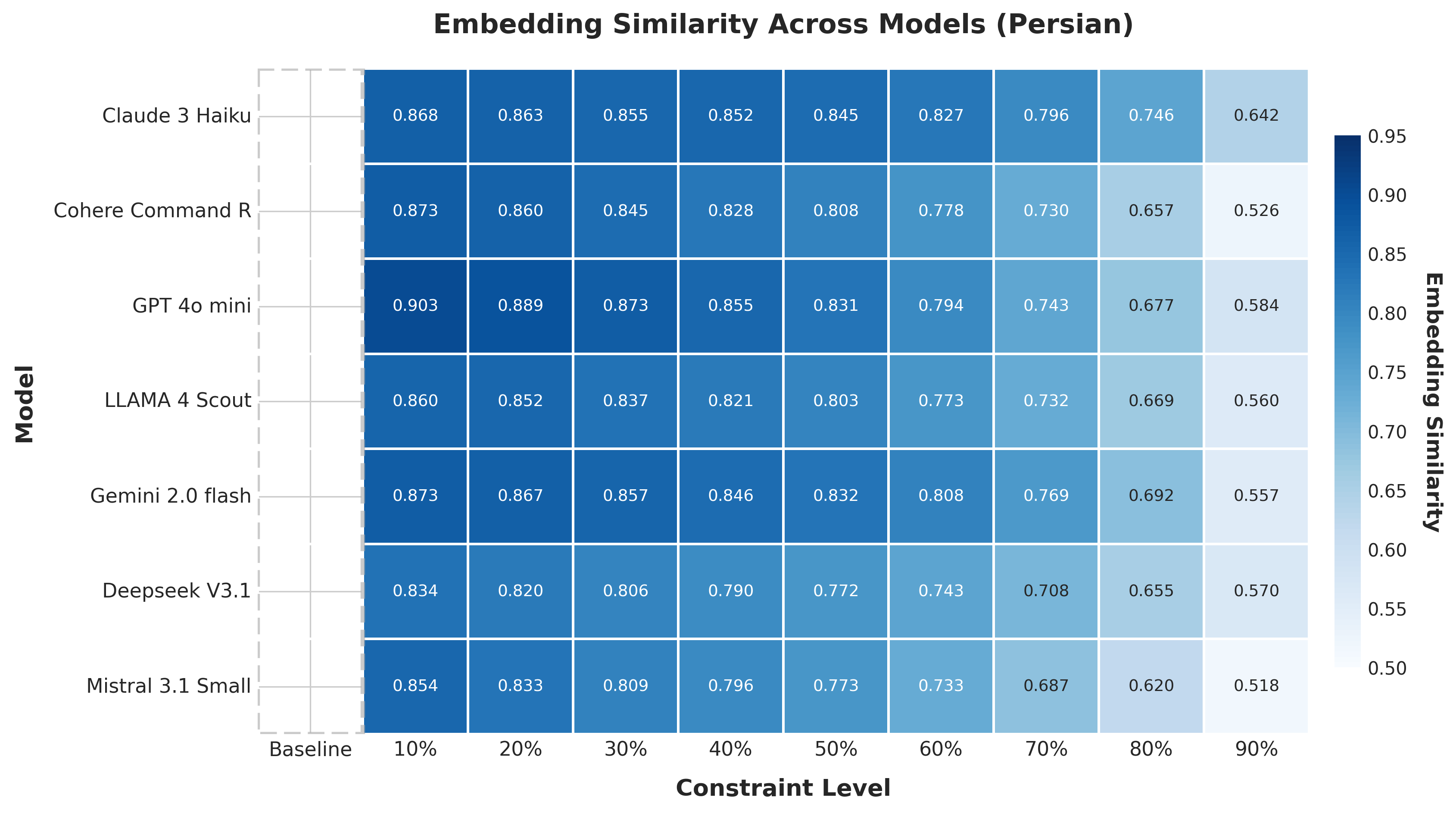
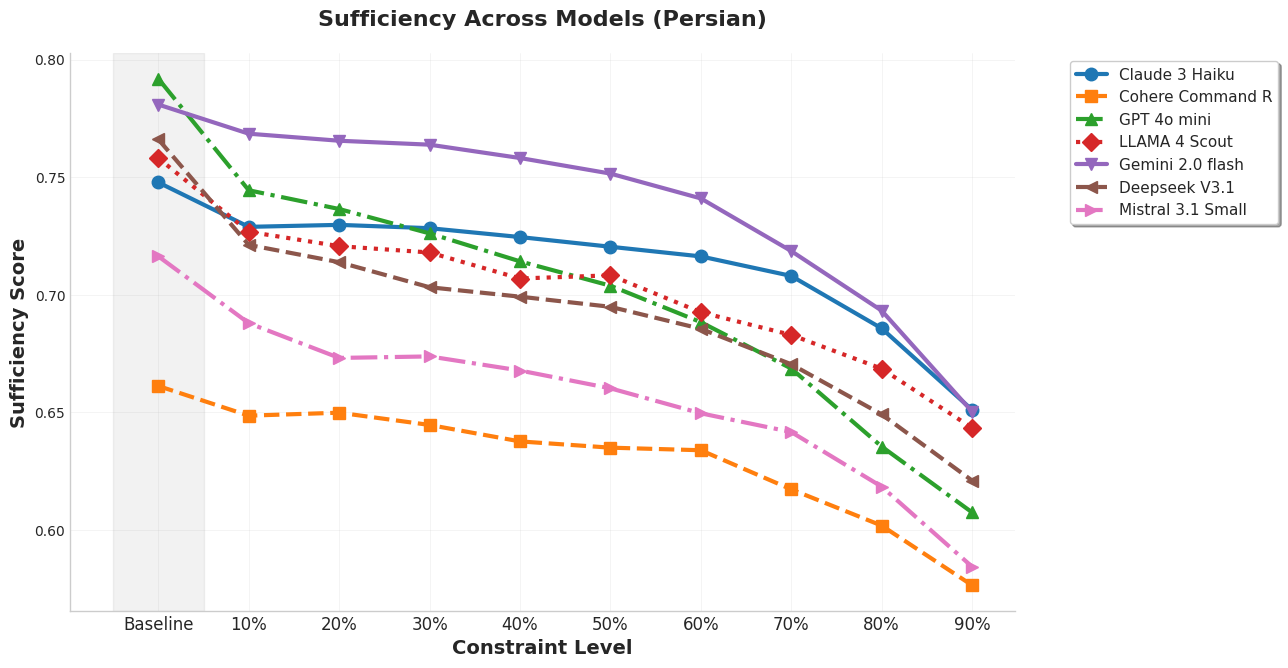
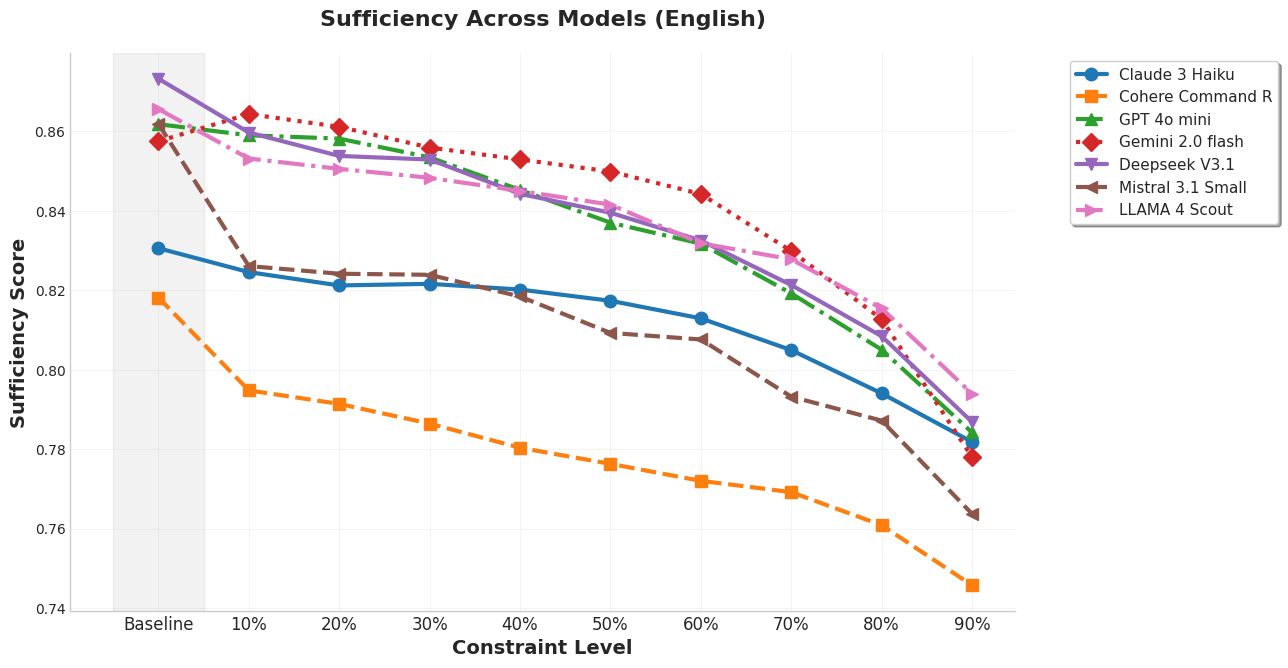
📊 实验亮点
实验结果表明,在ARC Challenge数据集上,通过适当的压缩,可以在保持甚至略微提高准确性的前提下,显著减少解释的长度。例如,在某些情况下,可以将解释长度减少50%以上,而准确率仅下降不到5%。过度压缩会导致性能下降,验证了充分性和简洁性之间的权衡关系。此外,在波斯语上的实验结果表明,该方法具有一定的跨语言泛化能力。
🎯 应用场景
该研究成果可应用于提升大语言模型在资源受限场景下的推理效率,例如在移动设备或边缘计算环境中,通过减少解释的长度来降低计算成本。此外,该研究也有助于开发更高效的教学系统,通过提供简洁而充分的解释来帮助学生理解复杂概念。未来,可以探索更智能的解释压缩方法,例如基于知识图谱或语义分析的压缩技术。
📄 摘要(原文)
Large Language Models increasingly rely on self-explanations, such as chain of thought reasoning, to improve performance on multi step question answering. While these explanations enhance accuracy, they are often verbose and costly to generate, raising the question of how much explanation is truly necessary. In this paper, we examine the trade-off between sufficiency, defined as the ability of an explanation to justify the correct answer, and conciseness, defined as the reduction in explanation length. Building on the information bottleneck principle, we conceptualize explanations as compressed representations that retain only the information essential for producing correct answers.To operationalize this view, we introduce an evaluation pipeline that constrains explanation length and assesses sufficiency using multiple language models on the ARC Challenge dataset. To broaden the scope, we conduct experiments in both English, using the original dataset, and Persian, as a resource-limited language through translation. Our experiments show that more concise explanations often remain sufficient, preserving accuracy while substantially reducing explanation length, whereas excessive compression leads to performance degradation.