HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
作者: Weiqi Zhai, Zhihai Wang, Jinghang Wang, Boyu Yang, Xiaogang Li, Xiang Xu, Bohan Wang, Peng Wang, Xingzhe Wu, Anfeng Li, Qiyuan Feng, Yuhao Zhou, Shoulin Han, Wenjie Luo, Yiyuan Li, Yaxuan Wang, Ruixian Luo, Guojie Lin, Peiyao Xiao, Chengliang Xu, Ben Wang, Zeyu Wang, Zichao Chen, Jianan Ye, Yijie Hu, Jialong Chen, Zongwen Shen, Yuliang Xu, An Yang, Bowen Yu, Dayiheng Liu, Junyang Lin, Hu Wei, Que Shen, Bing Zhao
分类: cs.CL
发布日期: 2026-02-15 (更新: 2026-02-17)
备注: 14 pages, 10 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出HLE-Verified,通过系统验证和修订提升HLE基准的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 基准测试 数据验证 数据清洗 知识问答
📋 核心要点
- 现有HLE基准测试包含大量噪声数据,影响模型评估的准确性和公平性。
- HLE-Verified通过两阶段验证和修复流程,系统性地识别并修正HLE中的错误。
- 实验表明,HLE-Verified能显著提升模型评估的准确性,尤其是在错误数据上。
📝 摘要(中文)
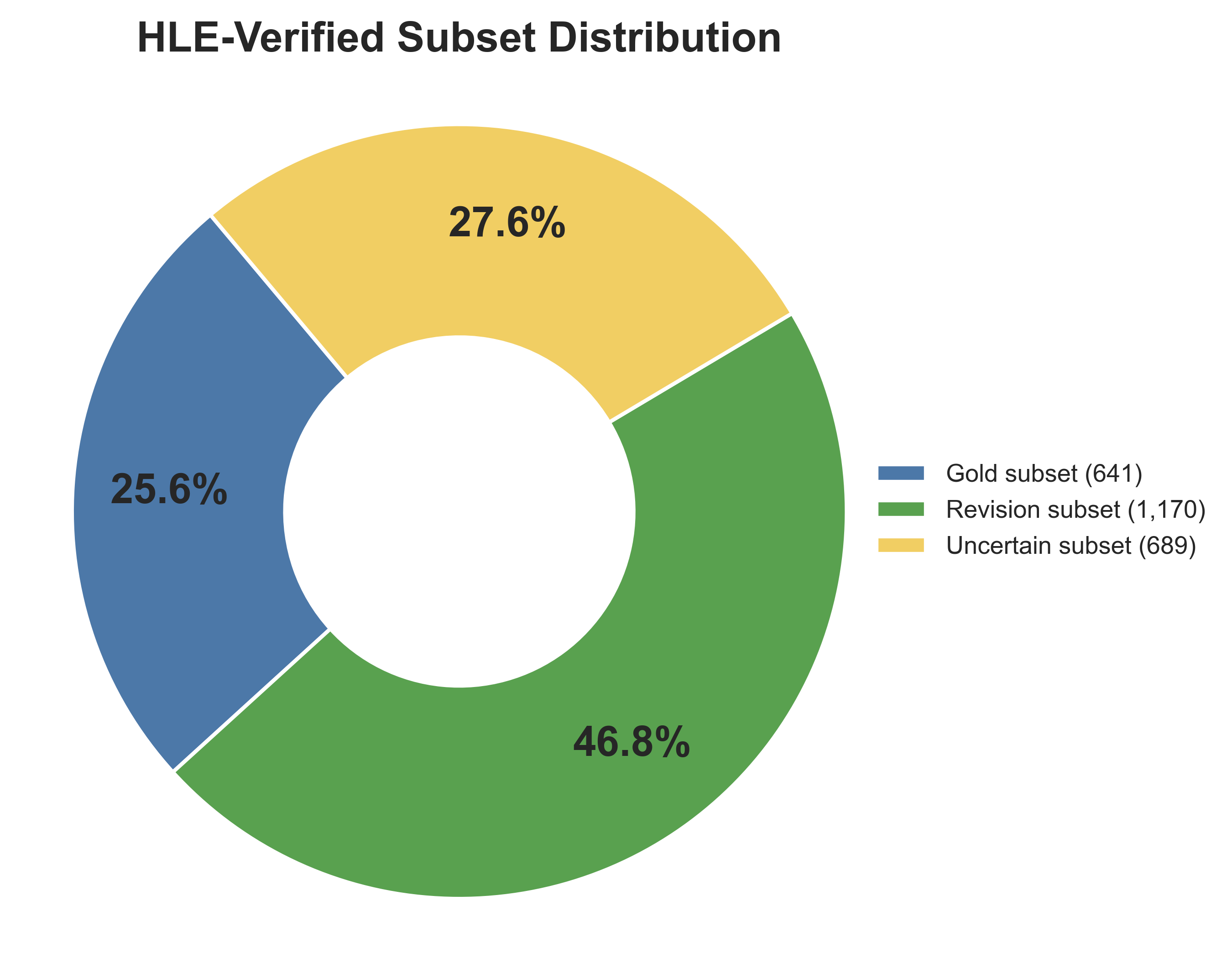
人类最后考试(HLE)已成为评估前沿大型语言模型在具有挑战性的多领域问题上的常用基准。然而,社区主导的分析表明,HLE包含大量噪声条目,这会使评估结果产生偏差并扭曲跨模型比较。为了解决这个问题,我们推出了HLE-Verified,这是一个经过验证和修订的HLE版本,具有透明的验证协议和细粒度的错误分类。我们的构建遵循一个两阶段的验证和修复工作流程,从而产生一个经过认证的基准。在第一阶段,每个条目都通过领域专家审查和基于模型的交叉检查进行问题和最终答案的二元验证,从而产生641个经过验证的条目。在第二阶段,有缺陷但可修复的条目在严格的约束下进行修订,保留原始评估意图,通过双重独立专家修复、模型辅助审计和最终裁决,从而产生1,170个修订和认证的条目。其余689个条目作为记录在案的不确定集发布,其中包含明确的不确定性来源和专业知识标签,以供未来改进。我们在HLE和HLE-Verified上评估了七个最先进的语言模型,观察到HLE-Verified上的平均绝对准确率提高了7-10个百分点。在原始问题陈述和/或参考答案存在错误的条目上,改进尤为明显,增益为30-40个百分点。我们的分析进一步揭示了模型置信度与问题陈述或参考答案中是否存在错误之间存在很强的关联,这支持了我们修订的有效性。总的来说,HLE-Verified通过减少标注噪声并实现对模型能力的更忠实测量来改进HLE风格的评估。数据可在https://github.com/SKYLENAGE-AI/HLE-Verified获得。
🔬 方法详解
问题定义:论文旨在解决HLE(Humanity's Last Exam)基准测试中存在的噪声问题。现有HLE基准包含大量错误或不明确的题目和答案,导致模型评估结果偏差,无法准确反映模型的真实能力。这些噪声数据会误导研究人员,影响模型选择和改进的方向。
核心思路:论文的核心思路是通过一个两阶段的验证和修复流程,系统性地识别并修正HLE中的错误。第一阶段进行严格的二元验证,判断题目和答案是否正确;第二阶段对可修复的错误进行修订,力求在保留原始评估意图的前提下,消除噪声。
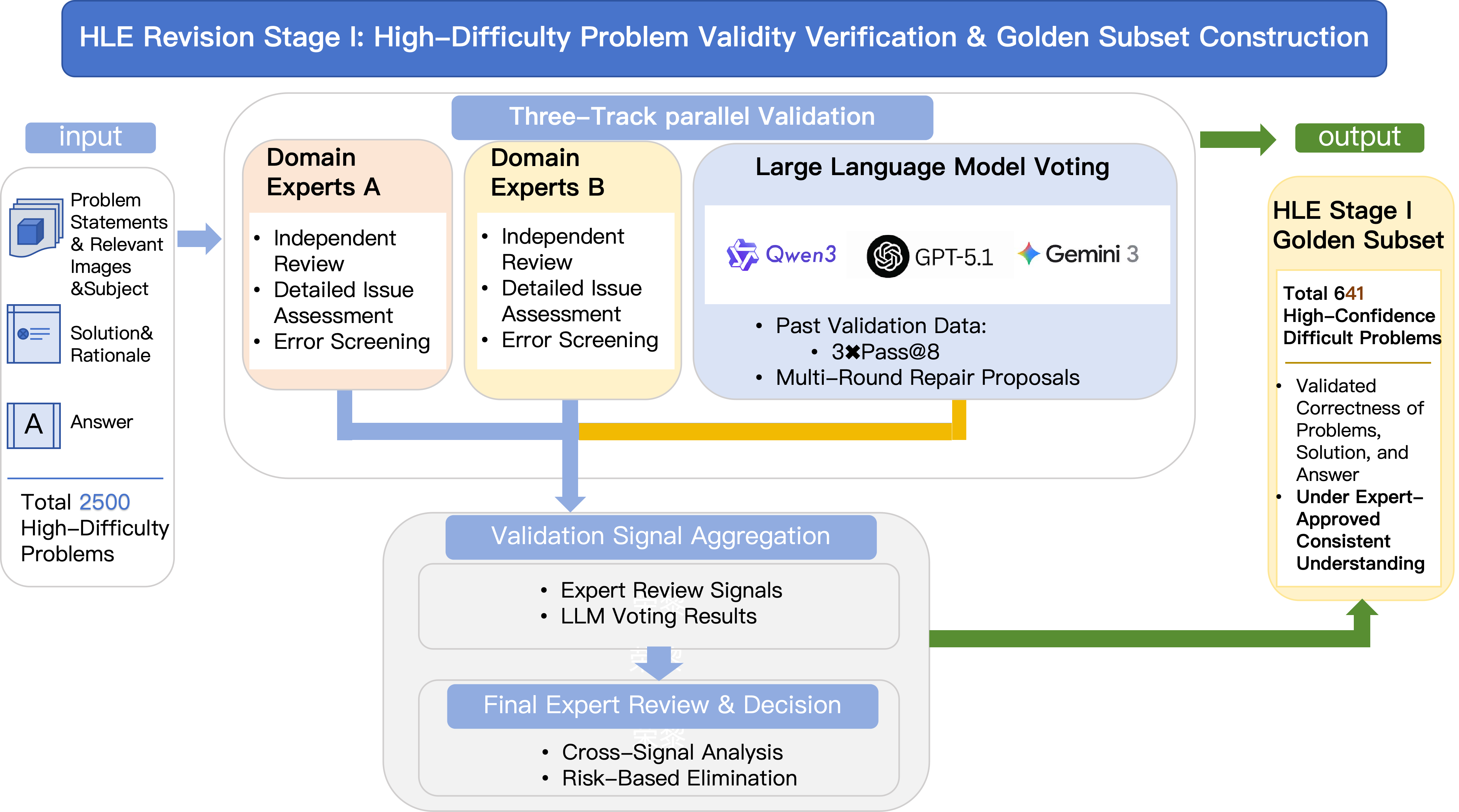
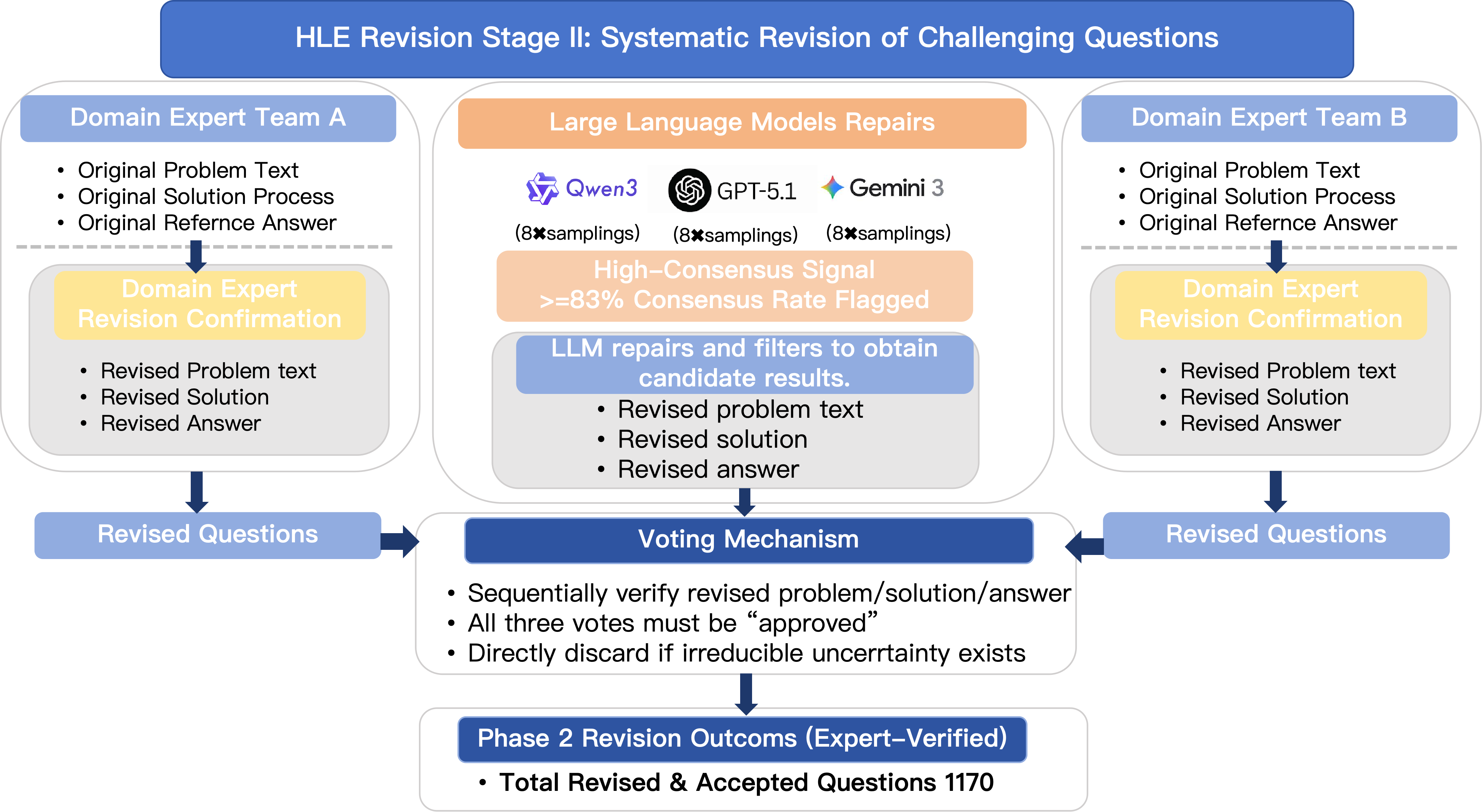
技术框架:HLE-Verified的构建包含两个主要阶段:验证阶段(Stage I)和修复阶段(Stage II)。 Stage I:验证阶段。领域专家和模型对每个条目进行独立验证,判断问题和答案是否正确。通过交叉检查,筛选出641个验证通过的条目。 Stage II:修复阶段。对于验证未通过但可修复的条目,由两位独立专家进行修订。修订后,通过模型辅助审计,确保修订后的条目质量。最终,通过裁决,确定1170个修订并认证的条目。剩余689个条目作为不确定集发布,并标注不确定性来源和专业知识标签。
关键创新:HLE-Verified的关键创新在于其系统性的验证和修复流程,以及透明的错误分类体系。该流程结合了领域专家知识和模型辅助审计,确保了修订后的基准质量。此外,论文还详细记录了不确定性来源,为未来的改进提供了依据。
关键设计:在验证阶段,采用了二元验证方法,即判断题目和答案是否完全正确。在修复阶段,强调保留原始评估意图,避免过度修改。模型辅助审计利用大型语言模型来评估修订后的条目质量,确保修订后的答案与问题相符。对于不确定集,标注了不确定性来源和专业知识标签,方便后续研究人员进行针对性改进。
🖼️ 关键图片
📊 实验亮点
在HLE-Verified上评估了七个最先进的语言模型,平均绝对准确率提高了7-10个百分点。在原始问题陈述和/或参考答案存在错误的条目上,改进尤为明显,增益为30-40个百分点。模型置信度与问题陈述或参考答案中是否存在错误之间存在很强的关联,这验证了修订的有效性。
🎯 应用场景
HLE-Verified可应用于更可靠地评估大型语言模型在多领域知识问答方面的能力。通过减少基准测试中的噪声,可以更准确地衡量模型的真实水平,从而促进语言模型的发展和应用,例如智能客服、教育辅导、知识检索等。
📄 摘要(原文)
Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier large language models on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art language models on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified