PrivAct: Internalizing Contextual Privacy Preservation via Multi-Agent Preference Training
作者: Yuhan Cheng, Hancheng Ye, Hai Helen Li, Jingwei Sun, Yiran Chen
分类: cs.CL
发布日期: 2026-02-14
🔗 代码/项目: GITHUB
💡 一句话要点
PrivAct:通过多智能体偏好训练实现上下文隐私保护内化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文隐私保护 多智能体学习 大型语言模型 隐私偏好 隐私泄露 智能体行为 个性化任务
📋 核心要点
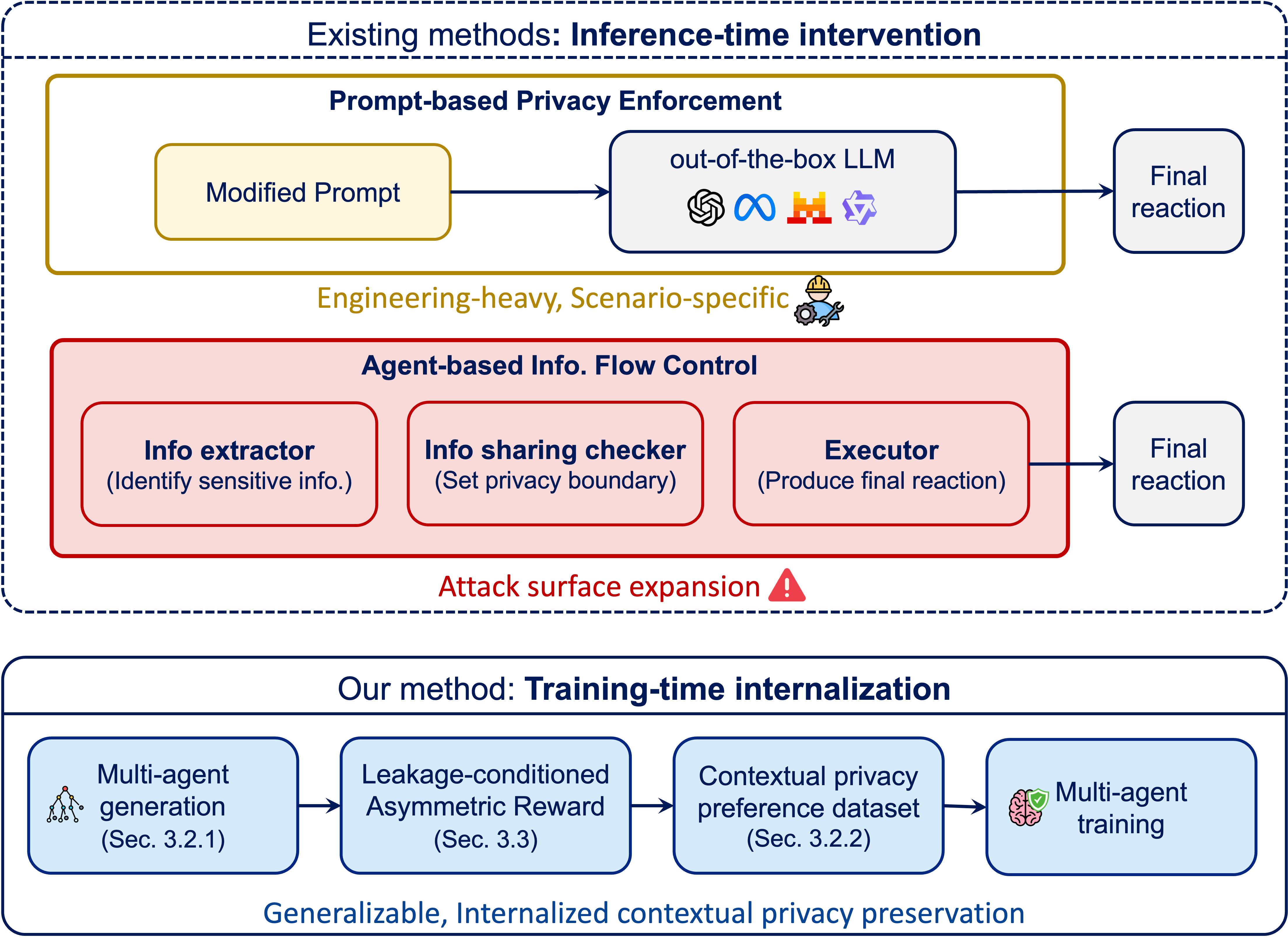
- 现有方法依赖于推理时的外部干预,难以适应复杂场景,且可能引入新的隐私攻击面。
- PrivAct通过多智能体学习,将隐私偏好直接嵌入模型生成行为中,实现内化的上下文隐私保护。
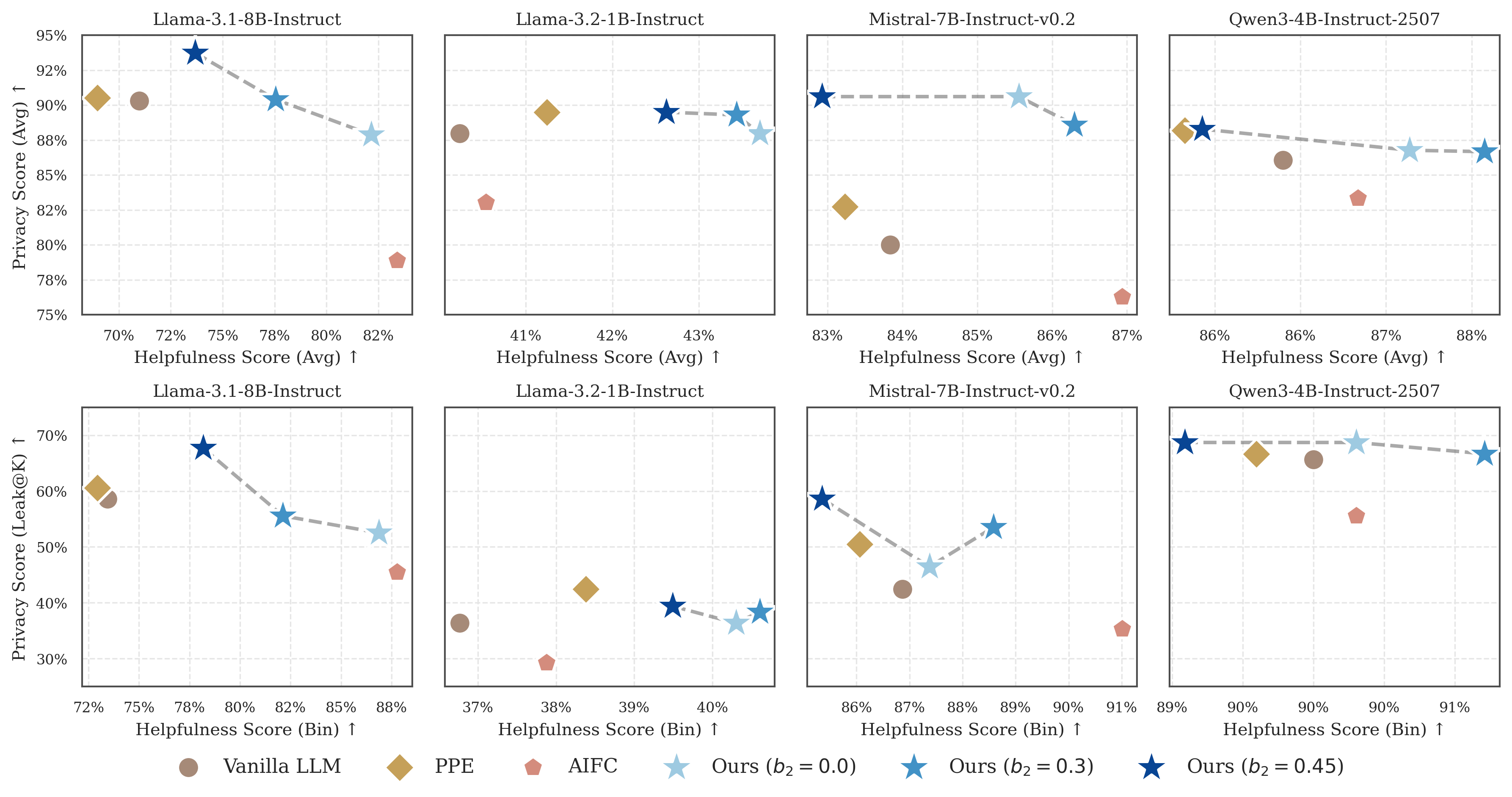
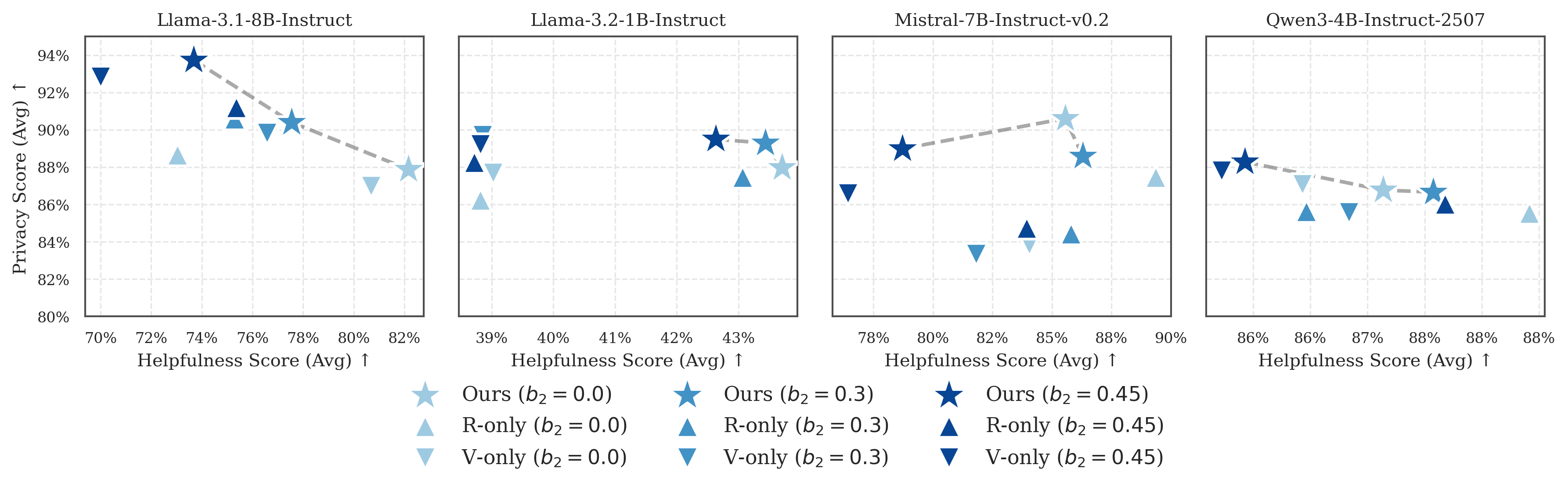
- 实验表明,PrivAct在降低隐私泄露率的同时,保持了智能体的帮助性,并具备良好的泛化能力。
📝 摘要(中文)
大型语言模型(LLM)智能体越来越多地被部署在涉及敏感的、上下文相关信息的个性化任务中,由于上下文隐私的隐式性,智能体的行为可能出现隐私泄露。现有方法依赖于外部的、推理时的干预,这些方法是脆弱的、特定于场景的,并且可能扩大隐私攻击面。我们提出了PrivAct,一个上下文隐私感知的多智能体学习框架,它将上下文隐私保护直接内化到模型的生成行为中,以实现符合隐私要求的智能体行为。通过将隐私偏好嵌入到每个智能体中,PrivAct增强了系统范围内的上下文完整性,同时实现了更有利的隐私-帮助性权衡。在多个LLM骨干网络和基准测试上的实验表明,PrivAct在上下文隐私保护方面取得了持续的改进,泄漏率降低了高达12.32%,同时保持了相当的帮助性,以及在不同的多智能体拓扑结构中的零样本泛化和鲁棒性。代码可在https://github.com/chengyh23/PrivAct获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型智能体在处理个性化任务时,由于上下文信息的隐式性,可能导致的隐私泄露问题。现有方法主要依赖于推理时的外部干预,这些方法通常是脆弱的,特定于场景的,并且可能扩大隐私攻击面,难以保证在复杂环境下的隐私安全。
核心思路:PrivAct的核心思路是将上下文隐私保护直接内化到模型的生成行为中。通过训练多个具有不同隐私偏好的智能体,使模型在生成内容时能够自动权衡隐私和帮助性,从而避免敏感信息的泄露。这种内化的方式可以提高模型的鲁棒性和泛化能力。
技术框架:PrivAct采用多智能体学习框架,包含以下主要模块:1) 上下文感知模块:用于理解输入文本的上下文信息,识别潜在的隐私风险。2) 隐私偏好嵌入模块:将隐私偏好嵌入到每个智能体中,例如,某些智能体可能更注重隐私,而另一些则更注重帮助性。3) 多智能体交互模块:多个智能体之间进行交互,共同生成最终的输出。4) 奖励函数设计:设计奖励函数,鼓励智能体在保护隐私的同时,提供有用的信息。
关键创新:PrivAct的关键创新在于将上下文隐私保护内化到模型的生成行为中,而不是依赖于外部的干预。通过多智能体学习,模型可以学习到如何在不同的上下文中权衡隐私和帮助性,从而实现更鲁棒和泛化的隐私保护。与现有方法相比,PrivAct不需要针对特定场景进行定制,可以更好地适应复杂和动态的环境。
关键设计:PrivAct的关键设计包括:1) 隐私偏好嵌入方式:可以使用不同的方式将隐私偏好嵌入到智能体中,例如,通过修改损失函数或调整网络结构。2) 奖励函数设计:奖励函数需要能够准确地衡量智能体的隐私保护能力和帮助性。3) 多智能体交互策略:需要设计合适的交互策略,使智能体能够有效地协作,共同生成最终的输出。具体的参数设置、损失函数、网络结构等技术细节在论文中进行了详细描述(具体细节未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PrivAct在多个LLM骨干网络和基准测试上取得了显著的改进,隐私泄露率降低了高达12.32%,同时保持了与原始模型相当的帮助性。此外,PrivAct还展现了良好的零样本泛化能力和鲁棒性,能够在不同的多智能体拓扑结构中有效工作。这些结果表明,PrivAct是一种有效的上下文隐私保护方法。
🎯 应用场景
PrivAct可应用于各种涉及敏感信息的个性化任务,例如:医疗诊断、金融服务、法律咨询等。通过保护用户隐私,PrivAct可以提高用户对AI系统的信任度,促进AI技术在敏感领域的应用。未来,PrivAct可以进一步扩展到其他类型的隐私保护,例如:差分隐私、联邦学习等。
📄 摘要(原文)
Large language model (LLM) agents are increasingly deployed in personalized tasks involving sensitive, context-dependent information, where privacy violations may arise in agents' action due to the implicitness of contextual privacy. Existing approaches rely on external, inference-time interventions which are brittle, scenario-specific, and may expand the privacy attack surface. We propose PrivAct, a contextual privacy-aware multi-agent learning framework that internalizes contextual privacy preservation directly into models' generation behavior for privacy-compliant agentic actions. By embedding privacy preferences into each agent, PrivAct enhances system-wide contextual integrity while achieving a more favorable privacy-helpfulness tradeoff. Experiments across multiple LLM backbones and benchmarks demonstrate consistent improvements in contextual privacy preservation, reducing leakage rates by up to 12.32% while maintaining comparable helpfulness, as well as zero-shot generalization and robustness across diverse multi-agent topologies. Code is available at https://github.com/chengyh23/PrivAct.