RMPL: Relation-aware Multi-task Progressive Learning with Stage-wise Training for Multimedia Event Extraction
作者: Yongkang Jin, Jianwen Luo, Jingjing Wang, Jianmin Yao, Yu Hong
分类: cs.CL, cs.CV
发布日期: 2026-02-14
💡 一句话要点
提出RMPL框架,通过关系感知多任务渐进学习解决多媒体事件抽取中的低资源问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多媒体事件抽取 多任务学习 渐进学习 关系感知 低资源学习
📋 核心要点
- 多媒体事件抽取缺乏标注数据,现有方法依赖跨模态对齐,难以学习结构化事件表示,论元定位较弱。
- RMPL框架利用单模态事件抽取和多媒体关系抽取的异构监督,通过阶段式训练学习共享事件表示。
- 在M2E2基准测试中,RMPL框架结合多种视觉-语言模型,在不同模态设置下均表现出性能提升。
📝 摘要(中文)
多媒体事件抽取(MEE)旨在从包含文本和图像的文档中识别事件及其论元,这需要跨不同模态对事件语义进行对齐。MEE的进展受到缺乏标注训练数据的限制。M2E2是唯一已建立的基准,但它仅提供用于评估的标注,这使得直接监督训练不切实际。现有方法主要依赖于跨模态对齐或使用视觉-语言模型(VLM)的推理时提示。这些方法没有明确地学习结构化的事件表示,并且经常在多模态设置中产生较弱的论元定位。为了解决这些限制,我们提出了一种关系感知多任务渐进学习框架RMPL,用于低资源条件下的MEE。RMPL结合了来自单模态事件抽取和多媒体关系抽取的异构监督,并采用阶段式训练。该模型首先使用统一的模式进行训练,以学习跨模态的共享事件中心表示。然后,使用混合的文本和视觉数据对事件提及识别和论元角色抽取进行微调。在M2E2基准上使用多个VLM进行的实验表明,在不同的模态设置中都取得了持续的改进。
🔬 方法详解
问题定义:论文旨在解决多媒体事件抽取(MEE)任务中,由于缺乏标注数据而导致的模型训练困难问题。现有方法,如跨模态对齐和基于视觉-语言模型的提示,无法有效学习结构化的事件表示,导致论元定位不准确,尤其是在多模态环境下。
核心思路:论文的核心思路是利用多任务学习和渐进式训练,结合来自单模态事件抽取和多媒体关系抽取的异构监督信息,从而在低资源条件下提升MEE的性能。通过学习共享的事件中心表示,模型能够更好地理解和抽取事件及其论元。
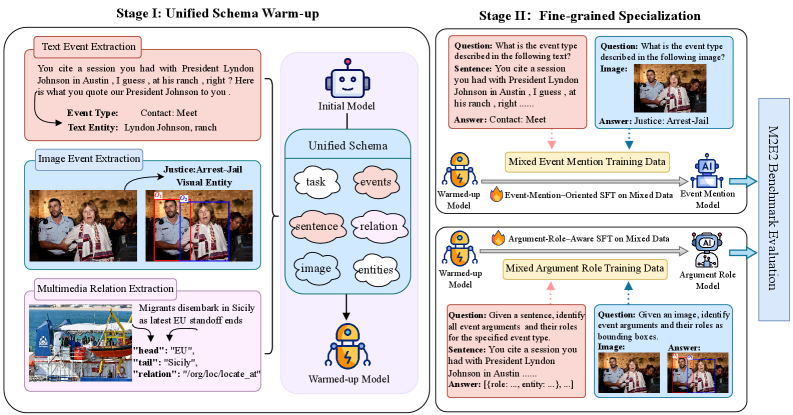
技术框架:RMPL框架包含两个主要阶段:第一阶段是使用统一的事件模式,在单模态数据上进行预训练,学习跨模态的共享事件表示。第二阶段是使用混合的文本和视觉数据,对事件提及识别和论元角色抽取任务进行微调。整个框架采用多任务学习的方式,同时优化事件抽取和关系抽取任务。
关键创新:RMPL的关键创新在于其关系感知的多任务渐进学习策略。它显式地利用了事件之间的关系信息,并将其融入到模型的训练过程中。此外,阶段式训练方法使得模型能够逐步学习事件表示,从而更好地适应低资源环境。与现有方法相比,RMPL更注重学习结构化的事件表示,从而提升论元定位的准确性。
关键设计:RMPL框架使用统一的事件模式来表示不同模态的事件信息。在损失函数方面,采用了多任务学习的损失函数,同时优化事件抽取和关系抽取任务。具体的网络结构细节未知,但根据描述,使用了视觉-语言模型(VLM)作为基础模型,并在此基础上进行了改进。阶段式训练的具体epoch设置和学习率调整策略未知。
🖼️ 关键图片

📊 实验亮点
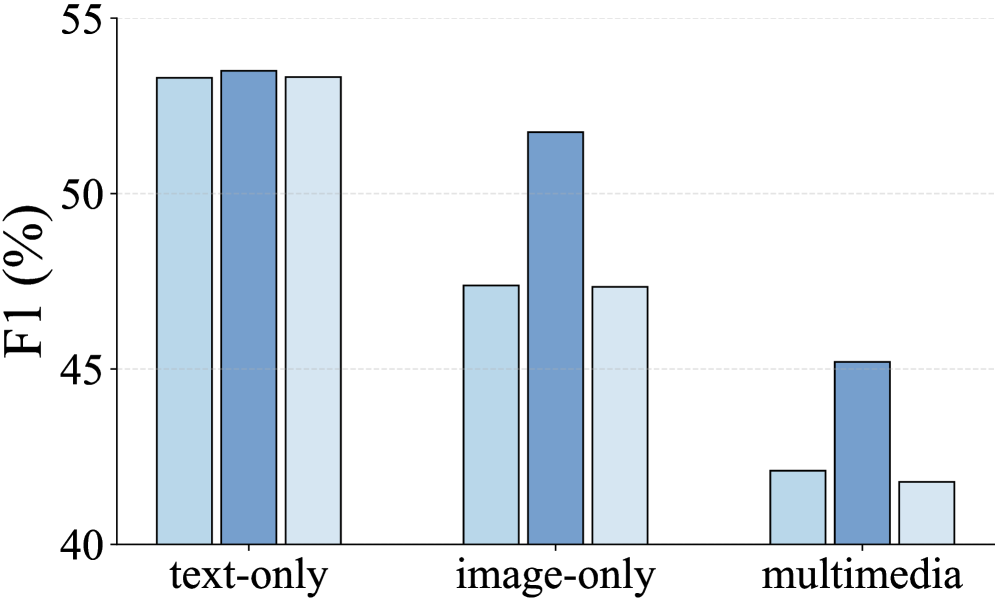
RMPL框架在M2E2基准测试中取得了显著的性能提升。实验结果表明,RMPL在不同的模态设置下均优于现有方法,证明了其在低资源多媒体事件抽取任务中的有效性。具体的性能数据和提升幅度在论文中给出,但摘要中未明确提及。
🎯 应用场景
该研究成果可应用于智能信息检索、舆情分析、智能安防等领域。通过准确抽取多媒体文档中的事件信息,可以帮助用户快速了解事件的发生、发展和影响,提高信息处理效率。未来,该技术有望应用于更广泛的多模态信息处理场景,例如智能客服、自动新闻摘要等。
📄 摘要(原文)
Multimedia Event Extraction (MEE) aims to identify events and their arguments from documents that contain both text and images. It requires grounding event semantics across different modalities. Progress in MEE is limited by the lack of annotated training data. M2E2 is the only established benchmark, but it provides annotations only for evaluation. This makes direct supervised training impractical. Existing methods mainly rely on cross-modal alignment or inference-time prompting with Vision--Language Models (VLMs). These approaches do not explicitly learn structured event representations and often produce weak argument grounding in multimodal settings. To address these limitations, we propose RMPL, a Relation-aware Multi-task Progressive Learning framework for MEE under low-resource conditions. RMPL incorporates heterogeneous supervision from unimodal event extraction and multimedia relation extraction with stage-wise training. The model is first trained with a unified schema to learn shared event-centric representations across modalities. It is then fine-tuned for event mention identification and argument role extraction using mixed textual and visual data. Experiments on the M2E2 benchmark with multiple VLMs show consistent improvements across different modality settings.